Recommended
PDF
PDF
PPTX
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
PPTX
PPTX
PPTX
PPTX
PDF
PDF
KEY
PPT
PDF
PDF
Rにおける大規模データ解析(第10回TokyoWebMining)
PPT
PDF
PPTX
PDF
PDF
PDF
PPTX
ブラックボックスからXAI (説明可能なAI) へ - LIME (Local Interpretable Model-agnostic Explanat...
PPTX
PDF
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
PDF
PDF
PDF
PDF
PPTX
DOCX
More Related Content
PDF
PDF
PPTX
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
PPTX
PPTX
PPTX
PPTX
What's hot
PDF
PDF
KEY
PPT
PDF
PDF
Rにおける大規模データ解析(第10回TokyoWebMining)
PPT
PDF
PPTX
PDF
PDF
PDF
PPTX
ブラックボックスからXAI (説明可能なAI) へ - LIME (Local Interpretable Model-agnostic Explanat...
PPTX
PDF
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
PDF
PDF
PDF
PDF
Viewers also liked
PPTX
DOCX
PPTX
PDF
ロジカル・シンキング & システム設計・プログラミングについて
DOCX
DOCX
PDF
PDF
PDF
HTTP/2 in nginx(2016/3/11 社内勉強会)
PPTX
PPTX
PDF
PDF
PDF
From Java To Clojure (English version)
PDF
PDF
Similar to Rプログラミング02 データ入出力編
PPTX
PDF
PDF
PDF
DOCX
PDF
PDF
PPT
12-11-30 Kashiwa.R #5 初めてのR Rを始める前に知っておきたい10のこと
PPT
PDF
10分で分かるr言語入門ver2.9 14 0920
PDF
10分で分かるr言語入門ver2.10 14 1101
PDF
PDF
PDF
StatGenSummerSchool2023_Rsoftware.pdf
PDF
20170923 excelユーザーのためのr入門
PDF
PDF
外国語教育メディア学会第54回全国研究大会ワークショップ「Rによる外国語教育データの分析と可視化の基本」
PPT
PDF
PDF
More from wada, kazumi
PPTX
PDF
DOCX
DOCX
DOCX
PDF
PPTX
PPTX
PPTX
PDF
PDF
PPTX
PPTX
PPTX
DOCX
DOCX
DOCX
DOCX
Rでの対称行列の固有値・固有ベクトルの最適な求め方
DOCX
Rによるlm関数を使わない回帰と梃子比・cookの距離
DOCX
Rプログラミング02 データ入出力編 1. 2. 目 次
I. データの入力方法
A) コンソールでの直接入力
B) データエディタの利用
C) csvファイル [その1、その2]
D) 固定長テキストファイル
E) 複数のcsvファイルをまとめて
II. 基本的な出力方法
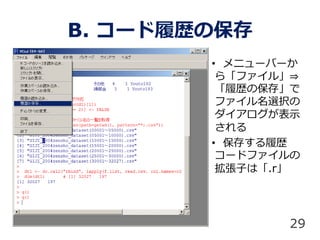
A) ワークスペース全体の保存
B) コードの履歴の保存
C) バイナリファイル
D) csvファイル
2
III. 関連知識
作業領域の掃除方法
ディレクトリやファイル
の操作
ダブルクォーテーション
円記号
プログラミングの留意点
繰り返し処理
条件分岐
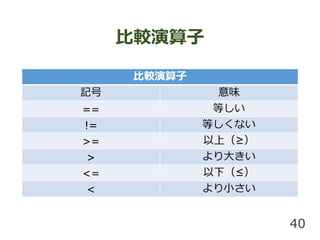
比較演算子
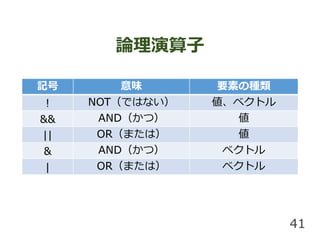
論理演算子
欠損値NAとその対処方法
NaN, Null, Inf
3. 4. • 変数は、車のスピードと制動距離の二つ
• それぞれspeedとdistという変数名を設定し、
「c()」の中に要素をカンマ区切りで並べて付置
することにより、ベクトルデータを作成し、次に
dat1にそれぞれのベクトルをcbindで横に並べて
行列データを作成している
A) コンソールでの直接入力
speed <- c(4, 4, 7, 7, …, 25)
dist <- c(2, 10, 4, 22, …, 85)
dat1 <- cbind(speed, dist)
4
例1. 車の制動距離データ [50×2]
※ 上のコマンドではデータを途中省略しているため、このスライドとセッ
トでアップロードされているデモコードをご利用ください。
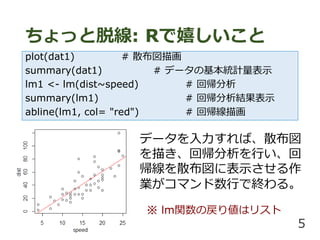
5. ちょっと脱線: Rで嬉しいこと
plot(dat1) # 散布図描画
summary(dat1) # データの基本統計量表示
lm1 <- lm(dist~speed) # 回帰分析
summary(lm1) # 回帰分析結果表示
abline(lm1, col= "red") # 回帰線描画
データを入力すれば、散布図
を描き、回帰分析を行い、回
帰線を散布図に表示させる作
業がコマンド数行で終わる。
※ lm関数の戻り値はリスト
5
6. • まずは空のデータフレーム dat2 を作成
• コンソールのメニューバーから「編集」 => 「データエ
ディタ」を選ぶとデータエディタが起動するので、必要
なデータを入力する
• メニューバー操作の代わりに fix 関数でも同じことがで
きる
• fix関数の代わりにedit 関数を使用する場合は付値が必要
B) データエディタの利用
dat2 <- data.frame() # 空のデータフレーム作成
fix(dat2) # データエディタの起動
6
※ 行列の要素は全て同じ型のデータという制約があるが、
データフレームは列毎に型の違うデータを保持できる
7. • read.csv 関数は、csvを読み込むための関数
• File.choose 関数を使用することにより、ファイル選
択のダイアログボックスが開き、任意のファイルを指
定することができる
• データは、cars.csv を使用する
C) CSVファイル、その1
data1 <- read.csv(file.choose())
head(data1) # データの冒頭だけ表示
tail(data1) # データの末尾だけ表示
7
※ データを読み込んだ後、内容確認はしておく。特に末尾を見る
ことは大切。
8. 9. • read.fwf 関数は、区切り文字のない固定長データを
読み込むための関数
• データは、cars.txt を使用する
• ヘッダはない
• 一行18桁で、10桁がスピード、8桁が距離で左詰め
D) 固定長テキストファイル
wt1 <- c(10, 8) # 桁数
cn1 <- c("speed", "dist") # 項目名
dat4 <- read.fwf("cars.txt", widths=wt1, col.names=cn1)
head(dat4) # データの冒頭だけ表示
tail(dat4) # データの末尾だけ表示
9
10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. - EXCELでの作業手順 -
1. ヘッダより上の部分を削除
2. 「変数名」でソート、ブランク行削除
3. 「型」でソート、ブランクを2に書き換え
4. 「行番号」順に再ソート
5. 必要のない列を削除
6. ヘッダを半角文字に
7. CSVファイルとして保存[ここでは code.csv]
23
i. コンスタント作成
1 : 数量データ
ブランク: カテゴリデータ
Rに読み込むとブランクはNA
に化けるので2に書き換える
型
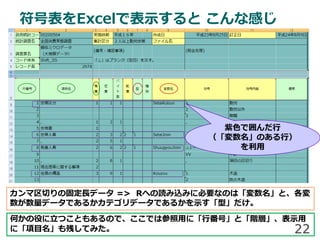
24. ii. コンスタント読込み
~ EXCELで作ったCSVファイルの最後にはよくゴミがある~
24
rm(list=ls(all=TRUE)) # 作業領域のお掃除♪
setwd("c:/Rdemo/giji/") # ファイルを置いたディレクトリの指定
Cd1 <- read.csv("code.csv", header=TRUE)
Tail(cd1)
A1 <- which(!is.na(cd1$ren)) # コンスタントファイル末尾の
Cd1 <- cd1[a1,] # ブランク行削除
Tail(cd1) # cd1の末尾確認
no koumoku lvl type namae
192 517 土地家屋借金返済 4 1 Youto178
193 519 他の借金返済 4 1 Youto179
194 521 分割払・一括払購入借入金返済 4 1 Youto180
195 523 財産購入 4 1 Youto181
196 525 その他 4 1 Youto182
197 527 繰越金 3 1 Youto183
# 因子属性への変換抑制フラグ作成
ft1 <- rep(TRUE, dim(cd1)[1])
ft1[which(cd1$type == 2)] <- FALSEc
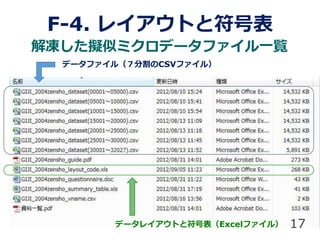
25. iii. データファイル読込み
~ 分割ファイルがたくさんあっても怖くない~
25
# 命名規則を指定してデータファイル名の一覧を取得
(f.list <- list.files(path=getwd(), pattern="*).csv"))
[1] "GIJI_2004zensho_dataset(00001~05000).csv"
[2] "GIJI_2004zensho_dataset(05001~10000).csv"
[3] "GIJI_2004zensho_dataset(10001~15000).csv"
[4] "GIJI_2004zensho_dataset(15001~20000).csv"
[5] "GIJI_2004zensho_dataset(20001~25000).csv"
[6] "GIJI_2004zensho_dataset(25001~30000).csv"
[7] "GIJI_2004zensho_dataset(30001~32027).csv"
dt1 <- do.call("rbind", lapply(f.list, read.csv,
col.names=cd1$namae, as.is=ft1, header=FALSE))
dim(dt1)
[1] 32027 197
26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. i <- 5
while (i > 0){
print("Hello!")
i <- i - 1
}
繰り返し処理
• for
• while
38
for (i in 1:5) print("Hello")
nm1 <- c("Mio", "Ryo", "John", “Yuki", "Taro")
for (i in 1:5) {
print(paste("Hello, ", nm1[i], "!", sep="") )
}
39. 条件分岐
• if() else{}
• ifelse
3
9
b <- c <- 0
if (a > 0) {
b <- b + 1; print("a > 0")
} else {
c <- c + 1; print ("a <= 0")
}
outcome <- ifelse (score > 0.5, print("Passed"), print("Failed"))
40. 41. 42. 欠損値 NA(1)
42
> x1 <- c(1,,5,2,4)
以下にエラー c(1, , 5, 2, 4) : 引数 2 が空です
> x1
エラー: オブジェクト 'x1' がありません
> x1 <- c(1,NA,5,2,4)
> x1
[1] 1 NA 5 2 4
> x1 == 5
[1] FALSE NA TRUE FALSE FALSE
> which(x1 == 5) # x1の値が5であるデータ番号
[1] 3
>
43. 欠損値 NA(2)
43
> which(x1 == NA) # x1の値がNAであるデータ番号
integer(0) # ?????
> x1 == NA
[1] NA NA NA NA NA
NAに対する演算結果は全てNAで比較演算子
==も使えない
代わりに、is.na という特別な関数が用意されているみち
44. 関数 is.na()
44
> which(x1 == NA) #x1の値がNAであるデータ番号
integer(0) # 1つもない
> x1 == NA
[1] NA NA NA NA NA
> sum(x1)
[1] NA
NAに対する演算結果は全てNAで比較演算子
==も使えず、そのままでは合計も計算できない
代わりに、is.na という特別な関数が用意されているみち
45. 46. NaN, Null, Inf
• NaN: 非数。例えば0を0で割ると得られる。
• Null: なにもないことを示す。NAが欠測を示す
のに対し、Nullはなにもないことを示し、ベクト
ルや行列といった構造を持つことはできない。
• Inf, -Inf: 無限大。例えば5を0で割ると得られる。
46
検査のための関数 機能
is.nan() 非数かどうか
is.null() NULLかどうか
is.finite() 有限かどうか
is.infinite() 無限大かどうか
Editor's Notes #6 class(lm1) #7 class関数で各ベクトルの属性を確認できる
# dat2 <- edit(dat2) # 上のコマンドと同じ
#8 class関数で各ベクトルの属性を確認できる #9 class関数で各ベクトルの属性を確認できる #10 class関数で各ベクトルの属性を確認できる #12 匿名データとデータのつくりが同じ。
実際の匿名データよりは小さいが、レコード数約3万2千、197項目という大規模データなので、マイニングなどにも。
試行提供段階なのでご意見をいただきたい。
#24 「型」には1かブランクが入っているが、使いやすいようにブランクを2に置き換える。 #26 メモリ2GBの32bitのVista機で実行。このくらいのデータ量であれば一気読みしても問題はない。
旧コード
#カレントディレクトリから特定の命名規則に従うデータファイル名の一覧を取得
(f.list <- list.files(path=getwd(), pattern="*).csv"))
n.file <- length(f.list) # データファイルの数をカウント
# データの読込
dt2 <- read.csv(f.list[1], col.names=cd1$namae, as.is=ft1, header=FALSE)
for (i in 2:n.file){ # ファイルの数だけループ
d1 <- read.csv(f.list[i], col.names=cd1$namae, as.is=ft1, header=FALSE)
dt2 <- rbind(dt2, d1)
}
#36 テキストエディタを使用している限りは問題が起きないが、WordなどOffice系のソフト上でコマンドを書く場合、半角のダブルクォーテーション(Shift-JISの16進コードで”22”)を勝手に全角(“8167”と”8168”)に変換することがある。
そのままプロンプトの画面にコピーペストしても適正には動かない。 #37 Rで採用されている正規表現では、\に続く文字に特殊な意味を持たせているため。 #41 http://qiita.com/uri/items/1245441ab179c6ee76f9 #42 http://qiita.com/uri/items/1245441ab179c6ee76f9



![目 次
I. データの入力方法
A) コンソールでの直接入力
B) データエディタの利用
C) csvファイル [その1、その2]
D) 固定長テキストファイル
E) 複数のcsvファイルをまとめて
II. 基本的な出力方法
A) ワークスペース全体の保存
B) コードの履歴の保存
C) バイナリファイル
D) csvファイル
2
III. 関連知識
作業領域の掃除方法
ディレクトリやファイル
の操作
ダブルクォーテーション
円記号
プログラミングの留意点
繰り返し処理
条件分岐
比較演算子
論理演算子
欠損値NAとその対処方法
NaN, Null, Inf](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-2-320.jpg)

![• 変数は、車のスピードと制動距離の二つ
• それぞれspeedとdistという変数名を設定し、
「c()」の中に要素をカンマ区切りで並べて付置
することにより、ベクトルデータを作成し、次に
dat1にそれぞれのベクトルをcbindで横に並べて
行列データを作成している
A) コンソールでの直接入力
speed <- c(4, 4, 7, 7, …, 25)
dist <- c(2, 10, 4, 22, …, 85)
dat1 <- cbind(speed, dist)
4
例1. 車の制動距離データ [50×2]
※ 上のコマンドではデータを途中省略しているため、このスライドとセッ
トでアップロードされているデモコードをご利用ください。](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-4-320.jpg)















![- EXCELでの作業手順 -
1. ヘッダより上の部分を削除
2. 「変数名」でソート、ブランク行削除
3. 「型」でソート、ブランクを2に書き換え
4. 「行番号」順に再ソート
5. 必要のない列を削除
6. ヘッダを半角文字に
7. CSVファイルとして保存[ここでは code.csv]
23
i. コンスタント作成
1 : 数量データ
ブランク: カテゴリデータ
Rに読み込むとブランクはNA
に化けるので2に書き換える
型](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-23-320.jpg)
![ii. コンスタント読込み
~ EXCELで作ったCSVファイルの最後にはよくゴミがある~
24
rm(list=ls(all=TRUE)) # 作業領域のお掃除♪
setwd("c:/Rdemo/giji/") # ファイルを置いたディレクトリの指定
Cd1 <- read.csv("code.csv", header=TRUE)
Tail(cd1)
A1 <- which(!is.na(cd1$ren)) # コンスタントファイル末尾の
Cd1 <- cd1[a1,] # ブランク行削除
Tail(cd1) # cd1の末尾確認
no koumoku lvl type namae
192 517 土地家屋借金返済 4 1 Youto178
193 519 他の借金返済 4 1 Youto179
194 521 分割払・一括払購入借入金返済 4 1 Youto180
195 523 財産購入 4 1 Youto181
196 525 その他 4 1 Youto182
197 527 繰越金 3 1 Youto183
# 因子属性への変換抑制フラグ作成
ft1 <- rep(TRUE, dim(cd1)[1])
ft1[which(cd1$type == 2)] <- FALSEc](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-24-320.jpg)
![iii. データファイル読込み
~ 分割ファイルがたくさんあっても怖くない~
25
# 命名規則を指定してデータファイル名の一覧を取得
(f.list <- list.files(path=getwd(), pattern="*).csv"))
[1] "GIJI_2004zensho_dataset(00001~05000).csv"
[2] "GIJI_2004zensho_dataset(05001~10000).csv"
[3] "GIJI_2004zensho_dataset(10001~15000).csv"
[4] "GIJI_2004zensho_dataset(15001~20000).csv"
[5] "GIJI_2004zensho_dataset(20001~25000).csv"
[6] "GIJI_2004zensho_dataset(25001~30000).csv"
[7] "GIJI_2004zensho_dataset(30001~32027).csv"
dt1 <- do.call("rbind", lapply(f.list, read.csv,
col.names=cd1$namae, as.is=ft1, header=FALSE))
dim(dt1)
[1] 32027 197](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-25-320.jpg)

![A. 作業領域全体の保存
save.image()で作業領域にある全ての変数や関数を保存
することができる [拡張子は「.rdata」]
setwd("c:/Rdemo/") # ファイルを作る場所を指定
save.image("Kensyuu1")
メニューバーから「ファイル」⇒ 「作業スペースの保
存」 ⇒ ファイル名を指定する
27
※ このとき保存されるものはls()で一覧表示される
R終了時にダイアログボックス「作業スペースを保存しま
すか?」が表示されるので「Yes」を選ぶ](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-27-320.jpg)



![■ 作業領域の掃除方法
• 作業領域にある全オブジェクト一覧
ls()
• 全オブジェクトを消去
rm(list=ls())
• オブジェクト x1, x2 を消去
rm(x1, x2)
• 関数オブジェクト以外の全てのオブジェクトを消
去
rm(list=ls()[!sapply(ls(), FUN=exists,
mode="function")])
33](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-33-320.jpg)


![円記号[]
Windowsでディレクトリのパス指定に使
われる円記号は、二重[]にするか、あるい
はスラッシュ[/]に置き換える
setwd("e:/R研修")
setwd("c:")
Windowsでの問題](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-36-320.jpg)

![i <- 5
while (i > 0){
print("Hello!")
i <- i - 1
}
繰り返し処理
• for
• while
38
for (i in 1:5) print("Hello")
nm1 <- c("Mio", "Ryo", "John", “Yuki", "Taro")
for (i in 1:5) {
print(paste("Hello, ", nm1[i], "!", sep="") )
}](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-38-320.jpg)

![欠損値 NA(1)
42
> x1 <- c(1,,5,2,4)
以下にエラー c(1, , 5, 2, 4) : 引数 2 が空です
> x1
エラー: オブジェクト 'x1' がありません
> x1 <- c(1,NA,5,2,4)
> x1
[1] 1 NA 5 2 4
> x1 == 5
[1] FALSE NA TRUE FALSE FALSE
> which(x1 == 5) # x1の値が5であるデータ番号
[1] 3
>](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-42-320.jpg)
![欠損値 NA(2)
43
> which(x1 == NA) # x1の値がNAであるデータ番号
integer(0) # ?????
> x1 == NA
[1] NA NA NA NA NA
NAに対する演算結果は全てNAで比較演算子
==も使えない
代わりに、is.na という特別な関数が用意されているみち](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-43-320.jpg)
![関数 is.na()
44
> which(x1 == NA) #x1の値がNAであるデータ番号
integer(0) # 1つもない
> x1 == NA
[1] NA NA NA NA NA
> sum(x1)
[1] NA
NAに対する演算結果は全てNAで比較演算子
==も使えず、そのままでは合計も計算できない
代わりに、is.na という特別な関数が用意されているみち](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-44-320.jpg)
![NAへの対応方法
45
> x1[!is.na(x1)]# NAを単に除去
[1] 1 5 2 4
> sum(x1[!is.na(x1)]) # 除去後合計を計算
[1] 12
> x2 <- ifelse(is.na(x1), 0, x1) # 0に置き換
え
> sum(x2)
[1] 12
> x2
[1] 1 0 5 2 4](https://image.slidesharecdn.com/r02slideshare-151024162328-lva1-app6891/85/R-02-45-320.jpg)





















































































