Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
YS
Uploaded by
Yutaka Shimada
PPTX, PDF
27,222 views
さくっとはじめるテキストマイニング(R言語) スタートアップ編
R言語を少しかじった人が「さくっとテキストマイニングを始める」ための、お助け資料。
Technology
◦
Read more
45
Save
Share
Embed
Embed presentation
Download
Downloaded 213 times
1
/ 57
2
/ 57
3
/ 57
4
/ 57
5
/ 57
6
/ 57
7
/ 57
8
/ 57
9
/ 57
10
/ 57
11
/ 57
12
/ 57
13
/ 57
14
/ 57
15
/ 57
16
/ 57
17
/ 57
18
/ 57
19
/ 57
20
/ 57
21
/ 57
22
/ 57
23
/ 57
24
/ 57
25
/ 57
26
/ 57
27
/ 57
28
/ 57
29
/ 57
30
/ 57
31
/ 57
32
/ 57
33
/ 57
34
/ 57
35
/ 57
36
/ 57
37
/ 57
38
/ 57
39
/ 57
40
/ 57
41
/ 57
42
/ 57
43
/ 57
44
/ 57
45
/ 57
46
/ 57
47
/ 57
48
/ 57
49
/ 57
50
/ 57
51
/ 57
52
/ 57
53
/ 57
54
/ 57
55
/ 57
56
/ 57
57
/ 57
More Related Content
PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
PPTX
データサイエンス概論第一=2-1 データ間の距離と類似度
by
Seiichi Uchida
PDF
StanとRでベイズ統計モデリング 11章 離散値をとるパラメータ
by
Miki Katsuragi
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
21世紀の手法対決 (MIC vs HSIC)
by
Toru Imai
KEY
ラムダ計算入門
by
Eita Sugimoto
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
データサイエンス概論第一=2-1 データ間の距離と類似度
by
Seiichi Uchida
StanとRでベイズ統計モデリング 11章 離散値をとるパラメータ
by
Miki Katsuragi
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
21世紀の手法対決 (MIC vs HSIC)
by
Toru Imai
ラムダ計算入門
by
Eita Sugimoto
What's hot
PPTX
劣モジュラ最適化と機械学習 3章
by
Hakky St
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PDF
R言語による アソシエーション分析-組合せ・事象の規則を解明する-(第5回R勉強会@東京)
by
Koichi Hamada
PPTX
学習時に使ってはいないデータの混入「リーケージを避ける」
by
西岡 賢一郎
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
PDF
はじパタ8章 svm
by
tetsuro ito
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PPTX
トピックモデルの基礎と応用
by
Tomonari Masada
PDF
合成変量とアンサンブル:回帰森と加法モデルの要点
by
Ichigaku Takigawa
PDF
階層ディリクレ過程事前分布モデルによる画像領域分割
by
tn1031
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PDF
これからの仮説検証・モデル評価
by
daiki hojo
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
PDF
データ解析10 因子分析の基礎
by
Hirotaka Hachiya
PDF
{tidytext}と{RMeCab}によるモダンな日本語テキスト分析
by
Takashi Kitano
PDF
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
PDF
パターン認識 04 混合正規分布
by
sleipnir002
PPTX
データサイエンス概論第一=2-2 クラスタリング
by
Seiichi Uchida
PDF
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
PDF
Granger因果による 時系列データの因果推定(因果フェス2015)
by
Takashi J OZAKI
劣モジュラ最適化と機械学習 3章
by
Hakky St
最適輸送の計算アルゴリズムの研究動向
by
ohken
R言語による アソシエーション分析-組合せ・事象の規則を解明する-(第5回R勉強会@東京)
by
Koichi Hamada
学習時に使ってはいないデータの混入「リーケージを避ける」
by
西岡 賢一郎
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
はじパタ8章 svm
by
tetsuro ito
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
トピックモデルの基礎と応用
by
Tomonari Masada
合成変量とアンサンブル:回帰森と加法モデルの要点
by
Ichigaku Takigawa
階層ディリクレ過程事前分布モデルによる画像領域分割
by
tn1031
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
これからの仮説検証・モデル評価
by
daiki hojo
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
データ解析10 因子分析の基礎
by
Hirotaka Hachiya
{tidytext}と{RMeCab}によるモダンな日本語テキスト分析
by
Takashi Kitano
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
パターン認識 04 混合正規分布
by
sleipnir002
データサイエンス概論第一=2-2 クラスタリング
by
Seiichi Uchida
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
Granger因果による 時系列データの因果推定(因果フェス2015)
by
Takashi J OZAKI
Viewers also liked
PDF
TwitterのデータをRであれこれ
by
Takeshi Arabiki
PPT
Working with Word for Qualitative Data Analysis
by
Jenna Condie
PPTX
Rをはじめからていねいに
by
Tsukasa Fukunaga
PPTX
全てをRでやらないと言う事
by
Tsukasa Fukunaga
PDF
Rデバッグあれこれ
by
Takeshi Arabiki
PDF
Rによるテキストマイニングの一例
by
LINE Corp.
PDF
RではじめるTwitter解析
by
Takeshi Arabiki
PDF
twitteRで快適Rライフ!
by
Takeshi Arabiki
TwitterのデータをRであれこれ
by
Takeshi Arabiki
Working with Word for Qualitative Data Analysis
by
Jenna Condie
Rをはじめからていねいに
by
Tsukasa Fukunaga
全てをRでやらないと言う事
by
Tsukasa Fukunaga
Rデバッグあれこれ
by
Takeshi Arabiki
Rによるテキストマイニングの一例
by
LINE Corp.
RではじめるTwitter解析
by
Takeshi Arabiki
twitteRで快適Rライフ!
by
Takeshi Arabiki
Similar to さくっとはじめるテキストマイニング(R言語) スタートアップ編
PPTX
Python による 「スクレイピング & 自然言語処理」入門
by
Tatsuya Tojima
PDF
R による文書分類入門
by
Takeshi Arabiki
PDF
Hadoop入門
by
Preferred Networks
PDF
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
PDF
Sakuteki02 yokkuns
by
Yohei Sato
PPTX
Approximate Scalable Bounded Space Sketch for Large Data NLP
by
Koji Matsuda
PDF
Uec.R#3 YjdnJlpを使ってみた
by
Atsushi Hayakawa
PDF
鬱くしい日本語のための形態素解析入門
by
Hiroyoshi Komatsu
PDF
さくさくテキストマイニング入門セッション
by
antibayesian 俺がS式だ
PPT
スペルミス修正プログラムを作ろう
by
Naoya Ito
PPTX
text_mining_with_R
by
亮介 藤巻
PPTX
今さら聞けないHadoop セントラルソフト株式会社(20120119)
by
Toru Takizawa
PPTX
蔵書選定のための学位論文タイトルマイニング
by
genroku
PPTX
Machine Learning Seminar (5)
by
Tomoya Nakayama
PDF
質問応答システム入門
by
Hiroyoshi Komatsu
PDF
C14
by
anonymousouj
PPTX
Mahoutにパッチを送ってみた
by
issaymk2
PPTX
A Monolingual Tree-based Translation Model for Sentence Simplification
by
DaikiNishihara
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
by
antibayesian 俺がS式だ
PDF
100816 nlpml sec2
by
shirakia
Python による 「スクレイピング & 自然言語処理」入門
by
Tatsuya Tojima
R による文書分類入門
by
Takeshi Arabiki
Hadoop入門
by
Preferred Networks
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
Sakuteki02 yokkuns
by
Yohei Sato
Approximate Scalable Bounded Space Sketch for Large Data NLP
by
Koji Matsuda
Uec.R#3 YjdnJlpを使ってみた
by
Atsushi Hayakawa
鬱くしい日本語のための形態素解析入門
by
Hiroyoshi Komatsu
さくさくテキストマイニング入門セッション
by
antibayesian 俺がS式だ
スペルミス修正プログラムを作ろう
by
Naoya Ito
text_mining_with_R
by
亮介 藤巻
今さら聞けないHadoop セントラルソフト株式会社(20120119)
by
Toru Takizawa
蔵書選定のための学位論文タイトルマイニング
by
genroku
Machine Learning Seminar (5)
by
Tomoya Nakayama
質問応答システム入門
by
Hiroyoshi Komatsu
C14
by
anonymousouj
Mahoutにパッチを送ってみた
by
issaymk2
A Monolingual Tree-based Translation Model for Sentence Simplification
by
DaikiNishihara
第三回さくさくテキストマイニング勉強会 入門セッション
by
antibayesian 俺がS式だ
100816 nlpml sec2
by
shirakia
Recently uploaded
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):コアマイクロシステムズ株式会社 テーマ 「AI HPC時代のトータルソリューションプロバイダ」
by
PC Cluster Consortium
PDF
論文紹介:DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
by
Toru Tamaki
PDF
論文紹介:HiLoRA: Adaptive Hierarchical LoRA Routing for Training-Free Domain Gene...
by
Toru Tamaki
PDF
論文紹介:MotionMatcher: Cinematic Motion Customizationof Text-to-Video Diffusion ...
by
Toru Tamaki
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ1「大規模AIの能力を最大限に活用するHPE Comp...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ2「『Slinky』 SlurmとクラウドのKuber...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ3「『TrinityX』 AI時代のクラスターマネジメ...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):エヌビディア合同会社 テーマ1「NVIDIA 最新発表製品等のご案内」
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ3「IT運用とデータサイエンティストを強力に支援するH...
by
PC Cluster Consortium
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):富士通株式会社 テーマ1「HPC&AI: Accelerating material develo...
by
PC Cluster Consortium
PPTX
2025年11月24日情報ネットワーク法学会大井哲也発表「API利用のシステム情報」
by
Tetsuya Oi
PPTX
ChatGPTのコネクタ開発から学ぶ、外部サービスをつなぐMCPサーバーの仕組み
by
Ryuji Egashira
PDF
ニューラルプロセッサによるAI処理の高速化と、未知の可能性を切り拓く未来の人工知能
by
Data Source
PDF
AI開発の最前線を変えるニューラルネットワークプロセッサと、未来社会における応用可能性
by
Data Source
PDF
膨大なデータ時代を制する鍵、セグメンテーションAIが切り拓く解析精度と効率の革新
by
Data Source
PCCC25(設立25年記念PCクラスタシンポジウム):コアマイクロシステムズ株式会社 テーマ 「AI HPC時代のトータルソリューションプロバイダ」
by
PC Cluster Consortium
論文紹介:DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
by
Toru Tamaki
論文紹介:HiLoRA: Adaptive Hierarchical LoRA Routing for Training-Free Domain Gene...
by
Toru Tamaki
論文紹介:MotionMatcher: Cinematic Motion Customizationof Text-to-Video Diffusion ...
by
Toru Tamaki
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ1「大規模AIの能力を最大限に活用するHPE Comp...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ2「『Slinky』 SlurmとクラウドのKuber...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):Pacific Teck Japan テーマ3「『TrinityX』 AI時代のクラスターマネジメ...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):エヌビディア合同会社 テーマ1「NVIDIA 最新発表製品等のご案内」
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):日本ヒューレット・パッカード合同会社 テーマ3「IT運用とデータサイエンティストを強力に支援するH...
by
PC Cluster Consortium
PCCC25(設立25年記念PCクラスタシンポジウム):富士通株式会社 テーマ1「HPC&AI: Accelerating material develo...
by
PC Cluster Consortium
2025年11月24日情報ネットワーク法学会大井哲也発表「API利用のシステム情報」
by
Tetsuya Oi
ChatGPTのコネクタ開発から学ぶ、外部サービスをつなぐMCPサーバーの仕組み
by
Ryuji Egashira
ニューラルプロセッサによるAI処理の高速化と、未知の可能性を切り拓く未来の人工知能
by
Data Source
AI開発の最前線を変えるニューラルネットワークプロセッサと、未来社会における応用可能性
by
Data Source
膨大なデータ時代を制する鍵、セグメンテーションAIが切り拓く解析精度と効率の革新
by
Data Source
さくっとはじめるテキストマイニング(R言語) スタートアップ編
1.
さくっとはじめる テキストマイニング(R言語) Version 1.0.1 スタートアップ編 2016年3月6日 Copyright ©
Skywill inc. All Rights Reserved.
2.
Copyright © Skywill
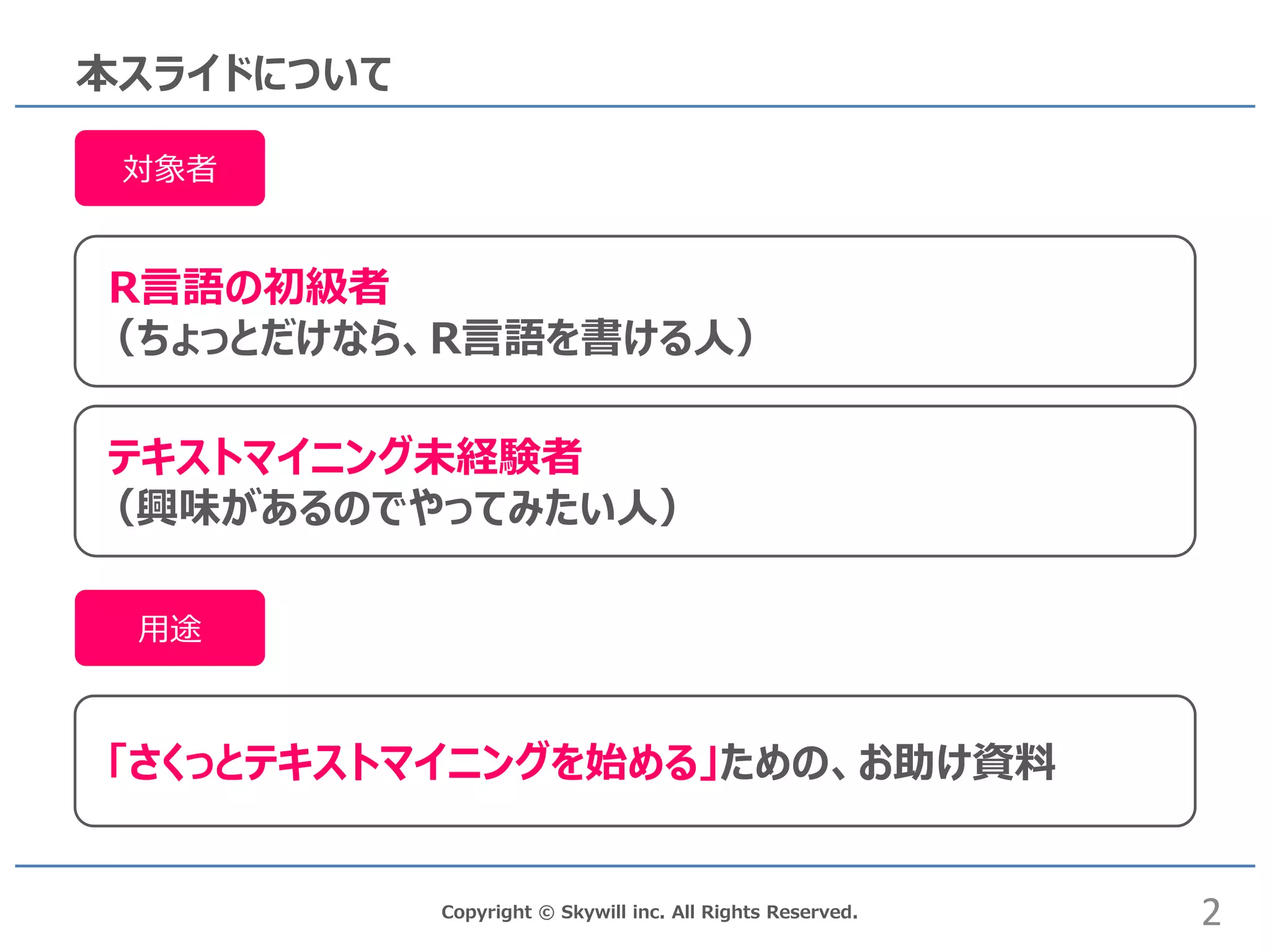
inc. All Rights Reserved. 本スライドについて R言語の初級者 (ちょっとだけなら、R言語を書ける人) 対象者 用途 「さくっとテキストマイニングを始める」ための、お助け資料 テキストマイニング未経験者 (興味があるのでやってみたい人) 2
3.
Copyright © Skywill
inc. All Rights Reserved. 本スライドについて 1)テキストマイニングの技術紹介 内容 3)プログラムを紹介 2)テキストマイニングの流れ 3
4.
Copyright © Skywill
inc. All Rights Reserved. 本スライドについて 作成者 嶋田 裕 R言語経験: 4ヶ月 職業: エンジニア 興味: ビッグデータ、統計解析、Webクローリング 趣味: 家庭菜園、フットサル かいわれ大根 R言語経験: 4ヶ月 職業: エンジニア 興味: ビックデータ、統計解析 趣味: 読書 4
5.
Copyright © Skywill
inc. All Rights Reserved. 1)テキストマイニングの技術紹介 1)テキストマイニングの技術紹介 内容 3)プログラムを紹介 2)テキストマイニングの流れ 5
6.
Copyright © Skywill
inc. All Rights Reserved. 1)テキストマイニングの技術紹介 6 テキストマイニング 形態素解析 ワードクラウド Nグラム解析 ネットワーク図 データクレンジング ■紹介する技術の一覧 テキストデータをマイニングする技術 文章を形態素に分解する技術 ゴミ情報を取り除く処理 文章中で連続する形態素を抽出する技術 関連性のある2つの形態素を表す統計手法 形態素の出現頻度を直感的に表す統計手法
7.
Copyright © Skywill
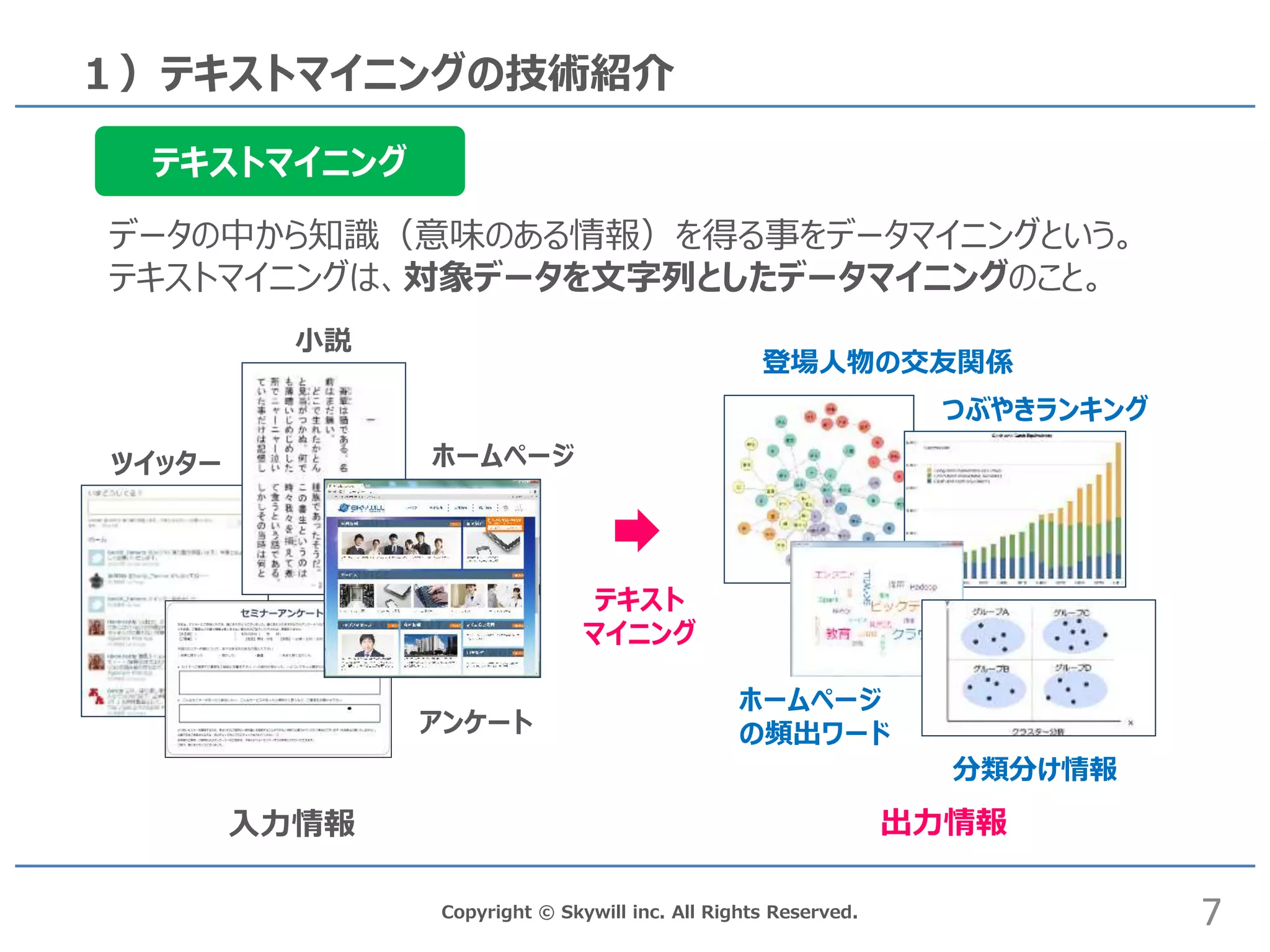
inc. All Rights Reserved. 1)テキストマイニングの技術紹介 データの中から知識(意味のある情報)を得る事をデータマイニングという。 テキストマイニングは、対象データを文字列としたデータマイニングのこと。 テキストマイニング ホームページ 小説 アンケート ツイッター テキスト マイニング 登場人物の交友関係 つぶやきランキング 分類分け情報 ホームページ の頻出ワード 7 入力情報 出力情報
8.
Copyright © Skywill
inc. All Rights Reserved. 1)テキストマイニングの技術紹介 形態素解析 文章を言葉の意味の最小構成要素(形態素)に分割し、 それぞれの品詞、活用形などを判別する技術。 この竹藪に竹立て掛けたのは竹立て掛けたかったから竹立て掛けた。 文章の先頭から辞書の見出しを当てていき、 該当する単語を選択 この 竹 に藪 竹 立て掛けた の は 名詞 名詞 動詞助詞 名詞名詞 助詞連体詞 ・・・ 8
9.
Copyright © Skywill
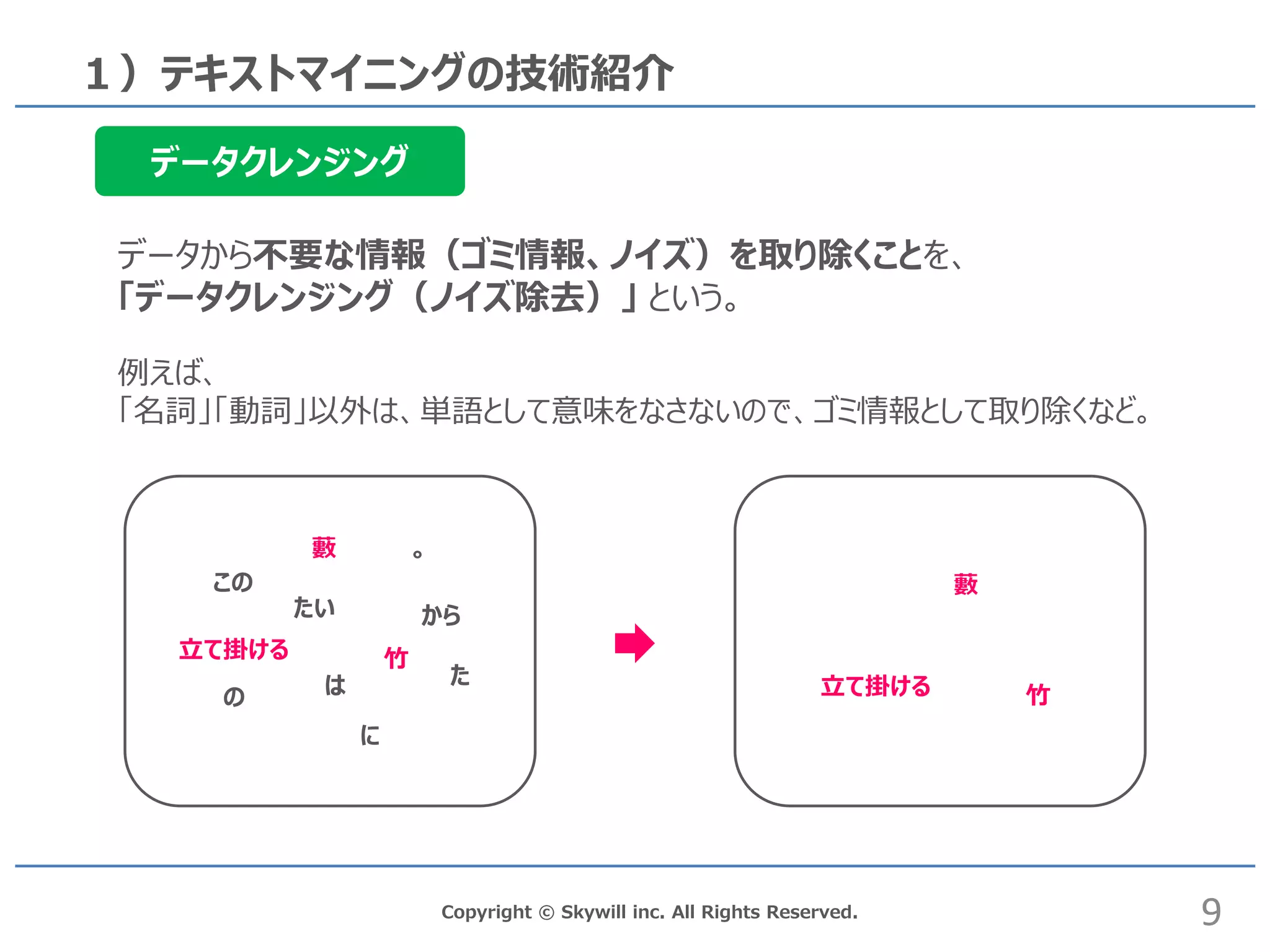
inc. All Rights Reserved. 1)テキストマイニングの技術紹介 データクレンジング データから不要な情報(ゴミ情報、ノイズ)を取り除くことを、 「データクレンジング(ノイズ除去)」 という。 。 たい は から た 立て掛ける に 竹 藪 の この 立て掛ける 竹 藪 9 例えば、 「名詞」「動詞」以外は、単語として意味をなさないので、ゴミ情報として取り除くなど。
10.
Copyright © Skywill
inc. All Rights Reserved. 1)テキストマイニングの技術紹介 ワードクラウド 文章の中で出現頻度が高い単語を複数選び出し、その頻度に応じた大き さで図示する手法。 「ビックデータ」「クラウド」「教育」の 出現頻度が高いという 文章の特徴がパッと見でわかる。 10
11.
Copyright © Skywill
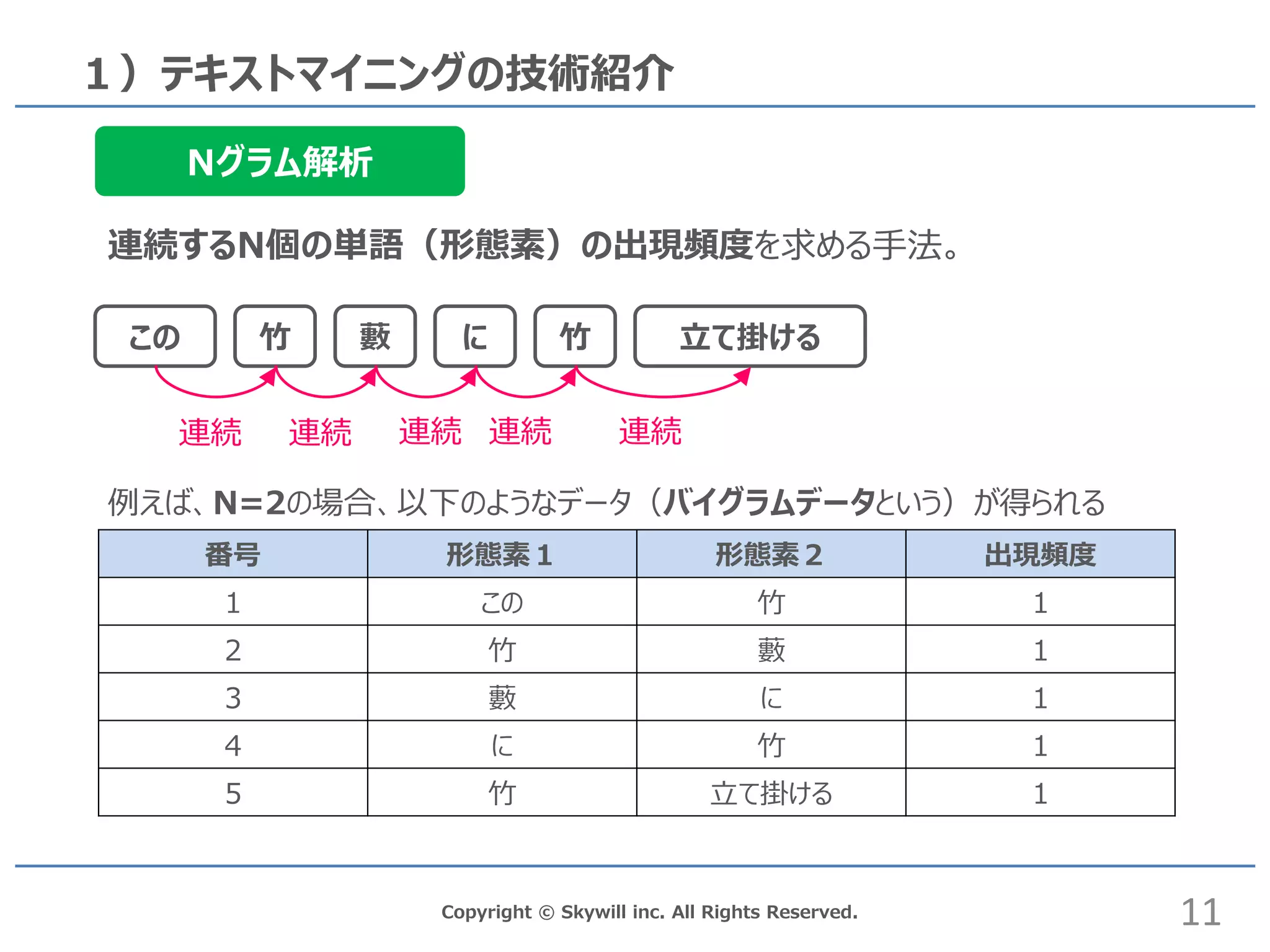
inc. All Rights Reserved. 1)テキストマイニングの技術紹介 この 竹 に藪 竹 立て掛ける 11 Nグラム解析 連続するN個の単語(形態素)の出現頻度を求める手法。 例えば、N=2の場合、以下のようなデータ(バイグラムデータという)が得られる 番号 形態素1 形態素2 出現頻度 1 この 竹 1 2 竹 藪 1 3 藪 に 1 4 に 竹 1 5 竹 立て掛ける 1 連続 連続 連続 連続 連続
12.
Copyright © Skywill
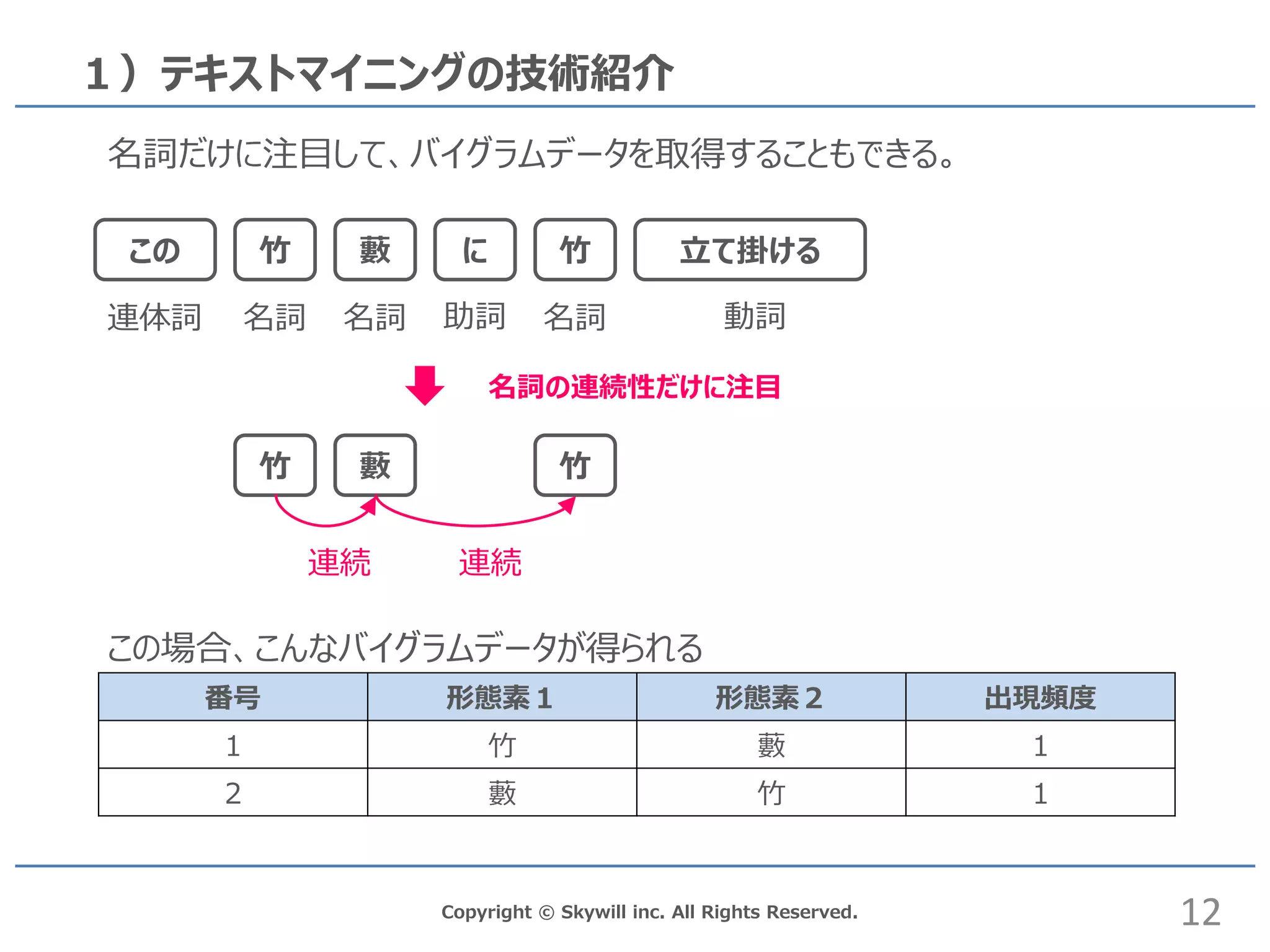
inc. All Rights Reserved. 1)テキストマイニングの技術紹介 この 竹 に藪 竹 立て掛ける 12 この場合、こんなバイグラムデータが得られる 番号 形態素1 形態素2 出現頻度 1 竹 藪 1 2 藪 竹 1 竹 藪 竹 名詞 名詞 動詞助詞 名詞連体詞 名詞だけに注目して、バイグラムデータを取得することもできる。 名詞の連続性だけに注目 連続 連続
13.
Copyright © Skywill
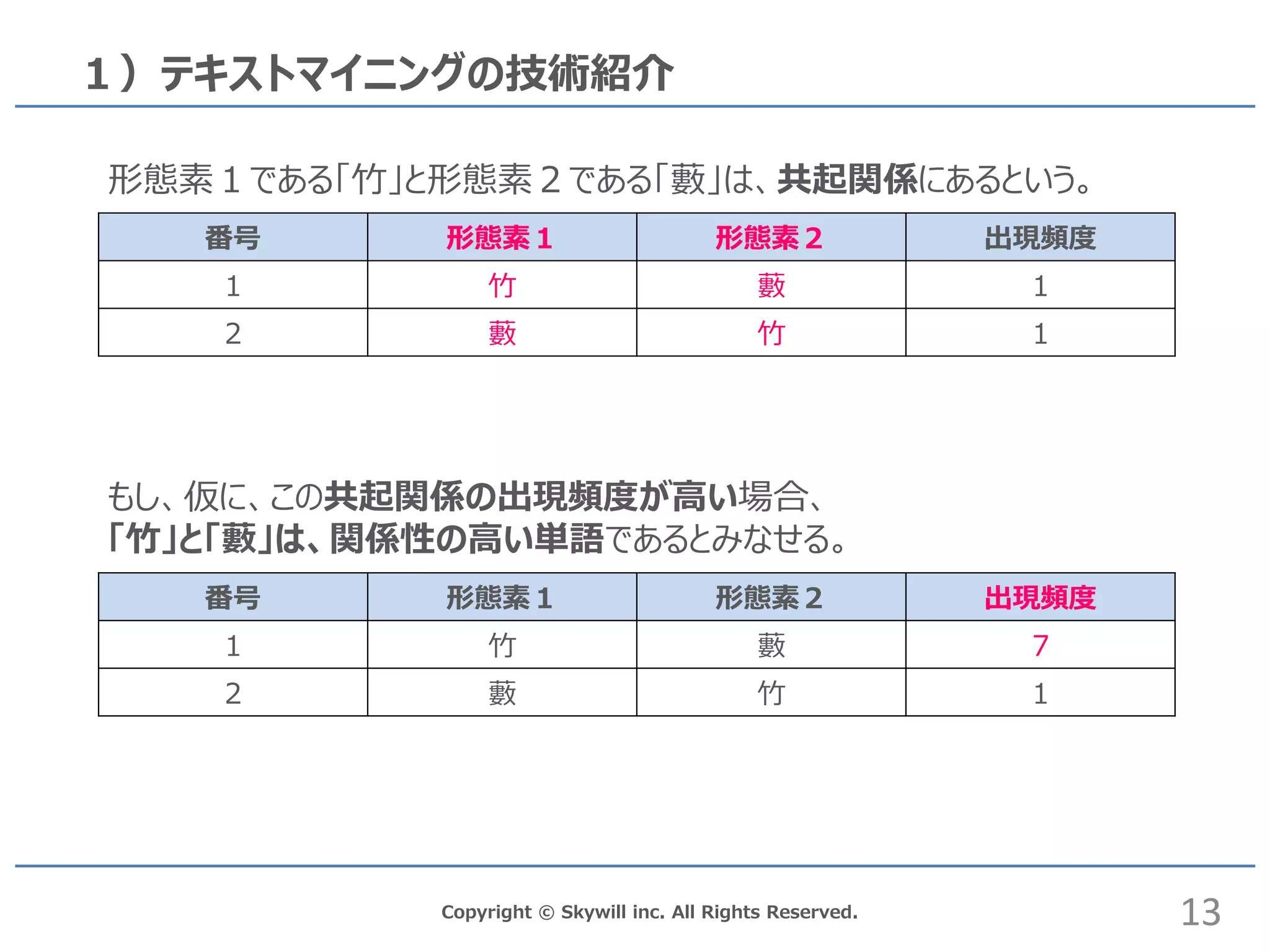
inc. All Rights Reserved. 1)テキストマイニングの技術紹介 13 番号 形態素1 形態素2 出現頻度 1 竹 藪 1 2 藪 竹 1 形態素1である「竹」と形態素2である「藪」は、共起関係にあるという。 番号 形態素1 形態素2 出現頻度 1 竹 藪 7 2 藪 竹 1 もし、仮に、この共起関係の出現頻度が高い場合、 「竹」と「藪」は、関係性の高い単語であるとみなせる。
14.
Copyright © Skywill
inc. All Rights Reserved. 1)テキストマイニングの技術紹介 ネットワーク図 関係性のある単語と単語を矢印で結び、それらの関係性を図示する 手法。 A B A B 「A」は、「B」に対して関係あり 「A」「B」は、お互いに関係あり 14
15.
Copyright © Skywill
inc. All Rights Reserved. 2)テキストマイニングの流れ 1)テキストマイニングの紹介 内容 3)プログラムを紹介 2)テキストマイニングの流れ 15
16.
Copyright © Skywill
inc. All Rights Reserved. 2)テキストマイニングの流れ 「テキストマイニング」の流れ 1)文章を分解してデータを得る 3)データを整える 2)データからゴミを取り除く 4)データをマイニングする 16
17.
Copyright © Skywill
inc. All Rights Reserved. 2)テキストマイニングの流れ この 竹 に 形態素に分解 藪 竹 立て掛ける の は ・・・ 名詞 名詞 動詞助詞 名詞名詞 助詞連体詞 1)文章を分解してデータを得る この竹藪に竹立て掛けたのは竹立て掛けたかったから竹立て掛けた。 17 形態素解析を使用して、文章を形態素に分解する。
18.
Copyright © Skywill
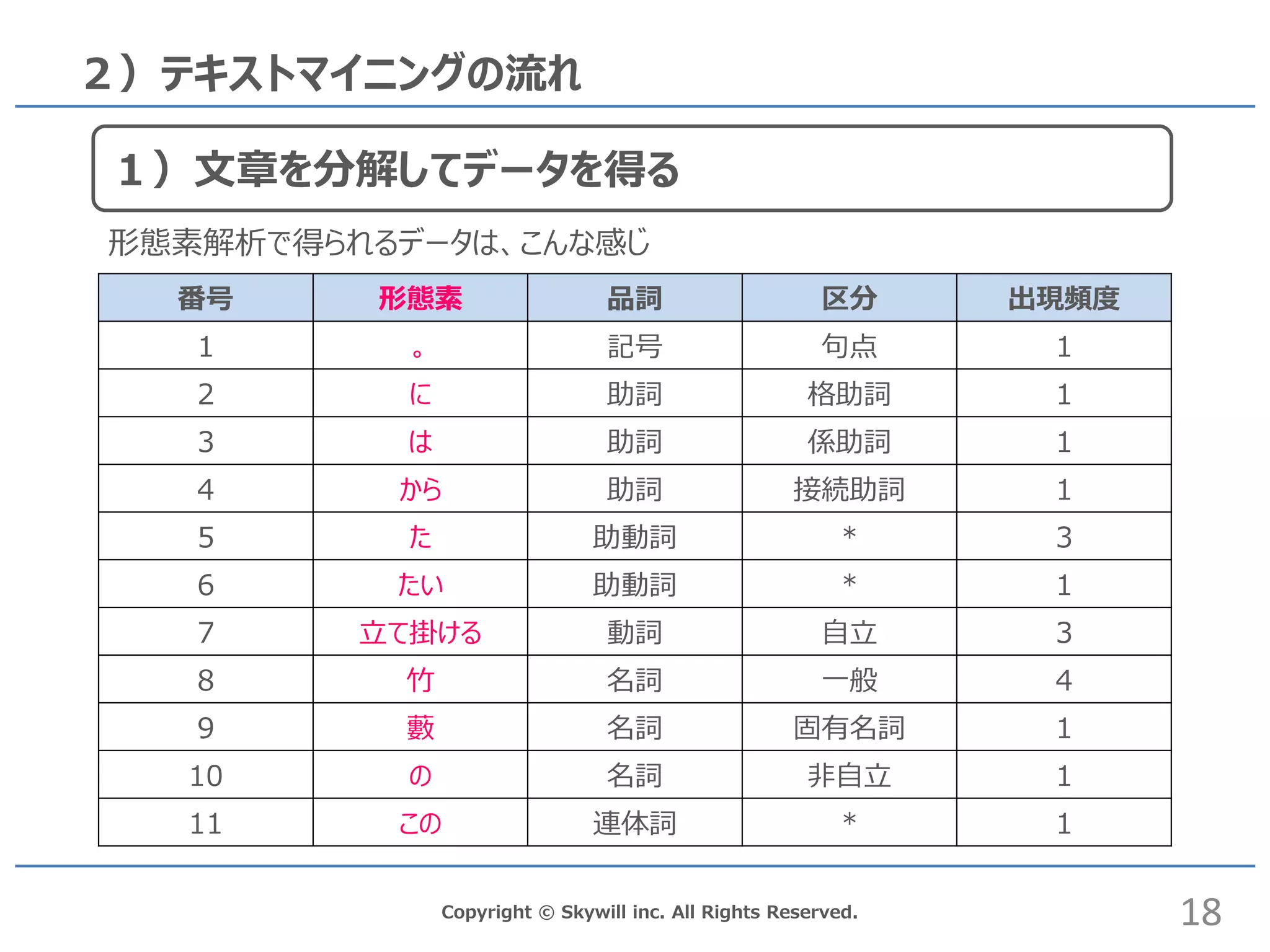
inc. All Rights Reserved. 2)テキストマイニングの流れ 番号 形態素 品詞 区分 出現頻度 1 。 記号 句点 1 2 に 助詞 格助詞 1 3 は 助詞 係助詞 1 4 から 助詞 接続助詞 1 5 た 助動詞 * 3 6 たい 助動詞 * 1 7 立て掛ける 動詞 自立 3 8 竹 名詞 一般 4 9 藪 名詞 固有名詞 1 10 の 名詞 非自立 1 11 この 連体詞 * 1 形態素解析で得られるデータは、こんな感じ 18 1)文章を分解してデータを得る
19.
Copyright © Skywill
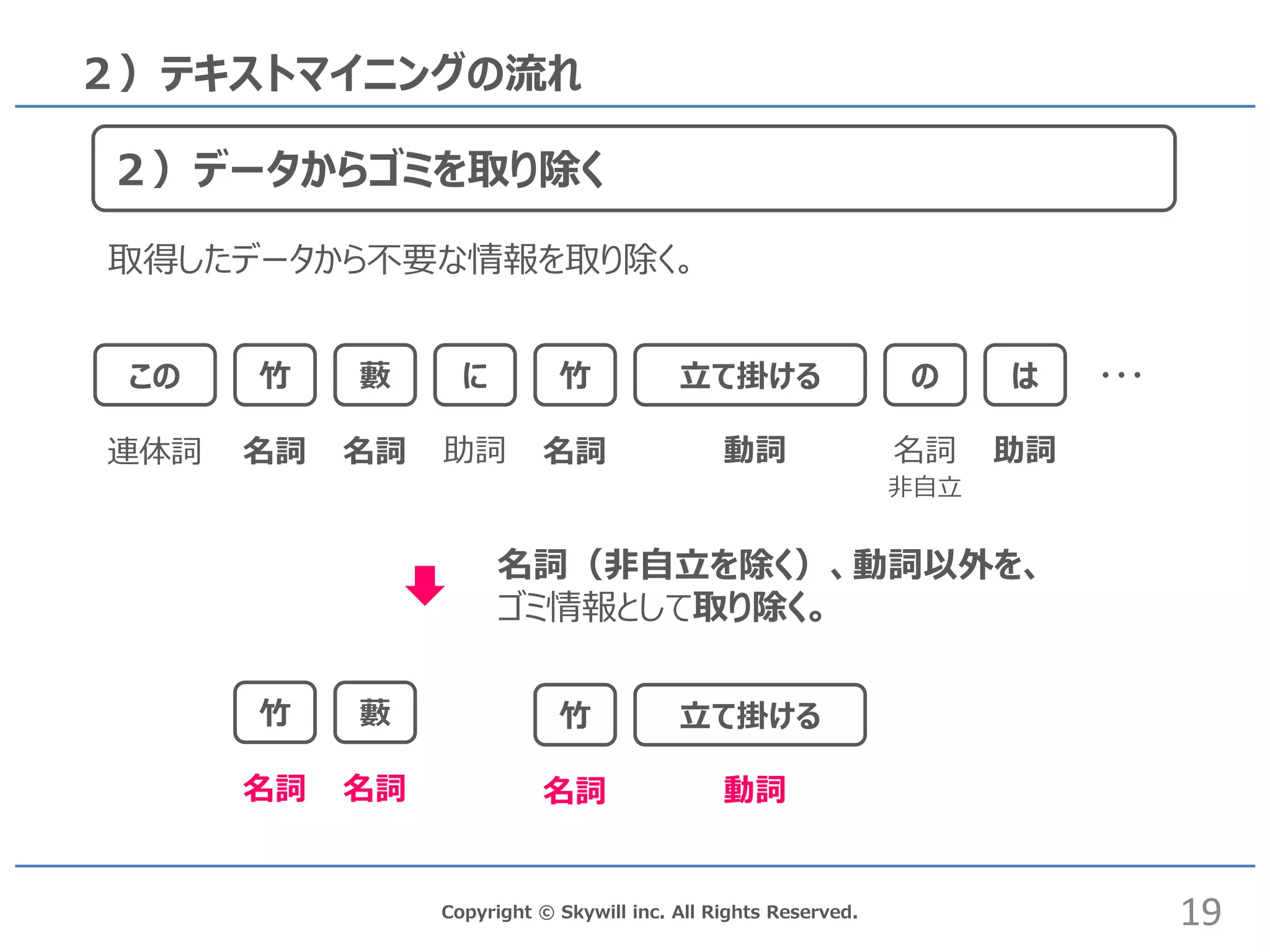
inc. All Rights Reserved. 2)テキストマイニングの流れ 2)データからゴミを取り除く この 竹 に藪 竹 立て掛ける の は 名詞 名詞 動詞助詞 名詞名詞 助詞連体詞 ・・・ 竹 藪 名詞 名詞 竹 立て掛ける 動詞名詞 名詞(非自立を除く)、動詞以外を、 ゴミ情報として取り除く。 非自立 19 取得したデータから不要な情報を取り除く。
20.
Copyright © Skywill
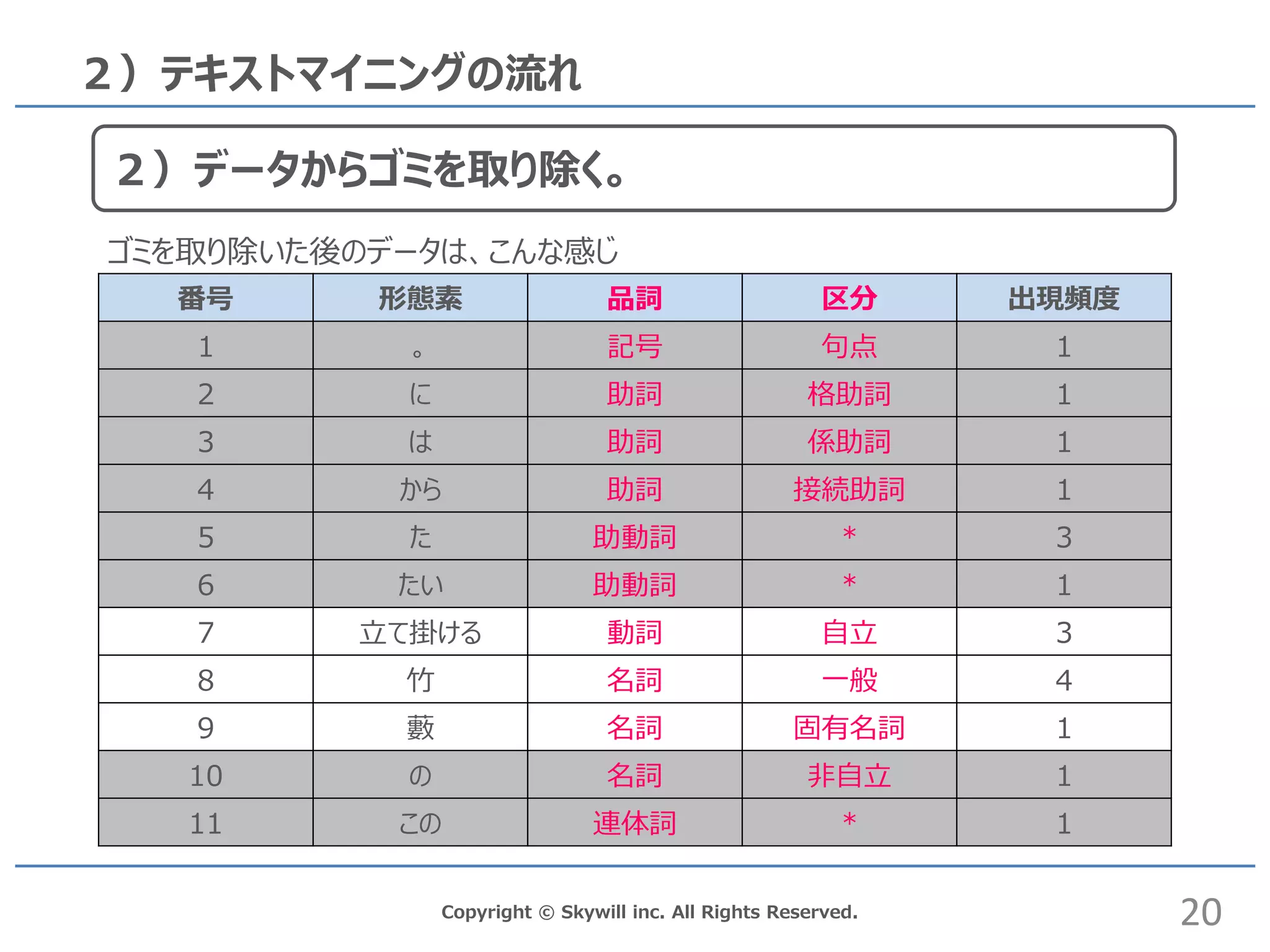
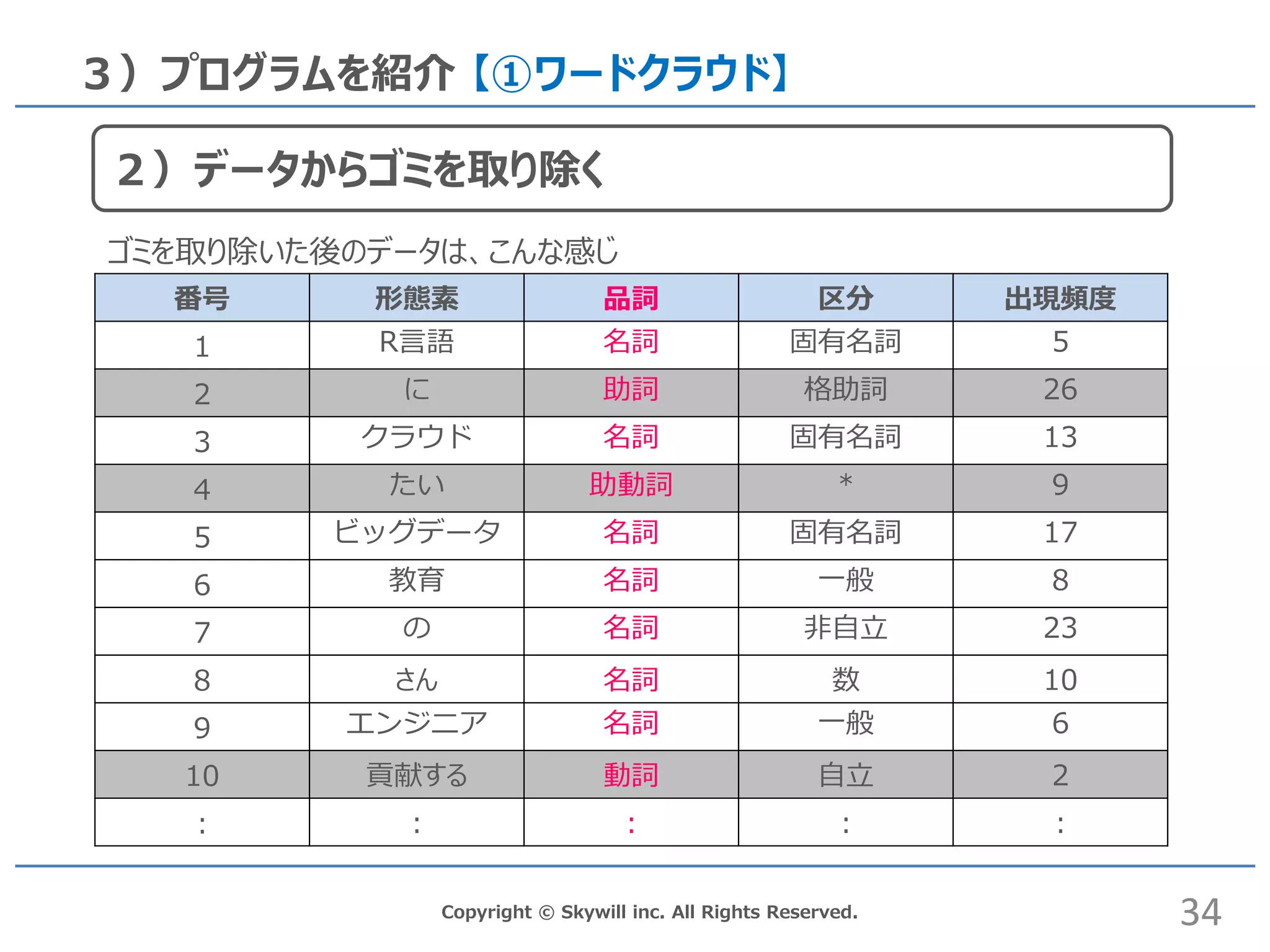
inc. All Rights Reserved. 2)テキストマイニングの流れ 番号 形態素 品詞 区分 出現頻度 1 。 記号 句点 1 2 に 助詞 格助詞 1 3 は 助詞 係助詞 1 4 から 助詞 接続助詞 1 5 た 助動詞 * 3 6 たい 助動詞 * 1 7 立て掛ける 動詞 自立 3 8 竹 名詞 一般 4 9 藪 名詞 固有名詞 1 10 の 名詞 非自立 1 11 この 連体詞 * 1 ゴミを取り除いた後のデータは、こんな感じ 20 2)データからゴミを取り除く。
21.
Copyright © Skywill
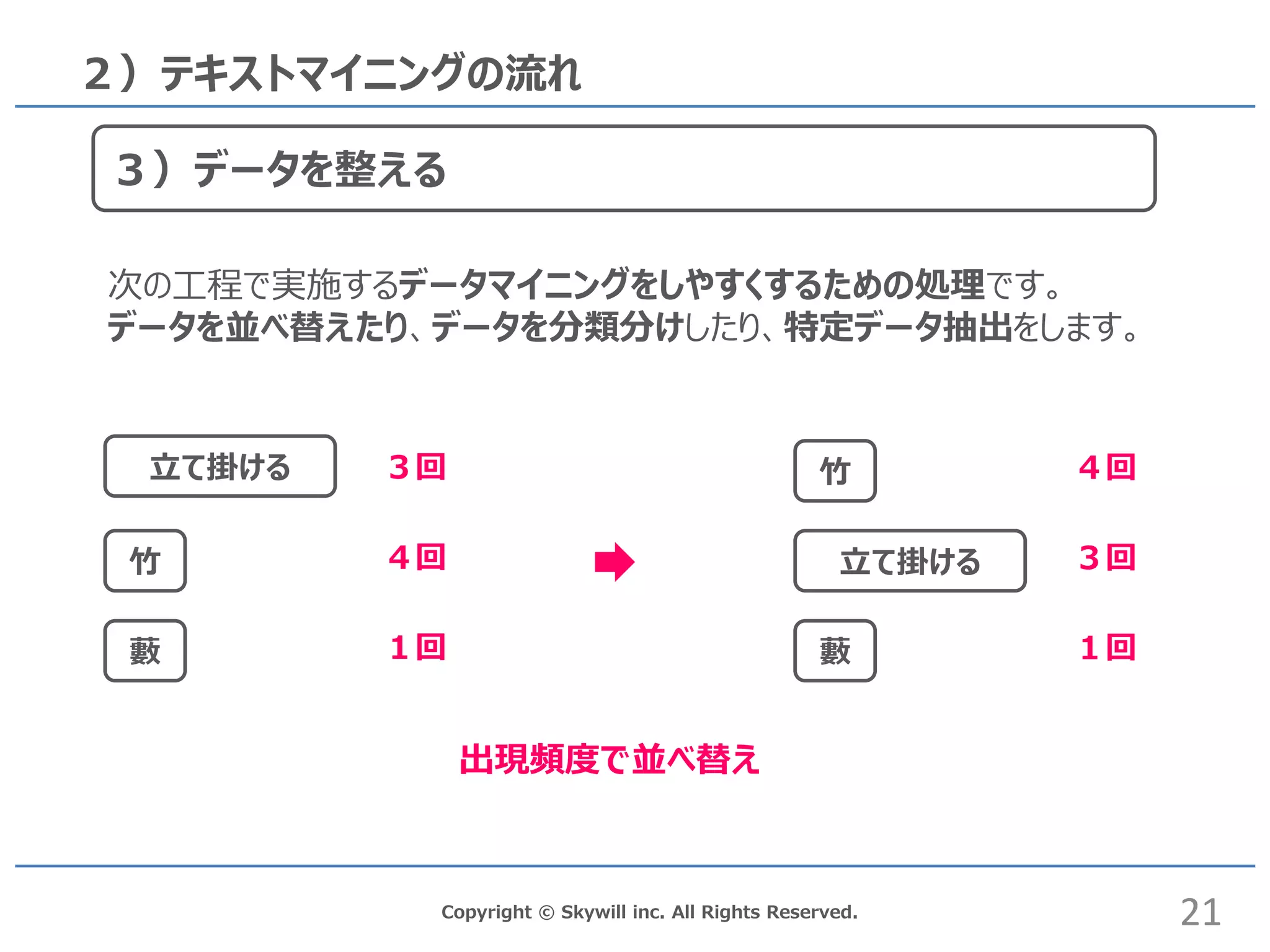
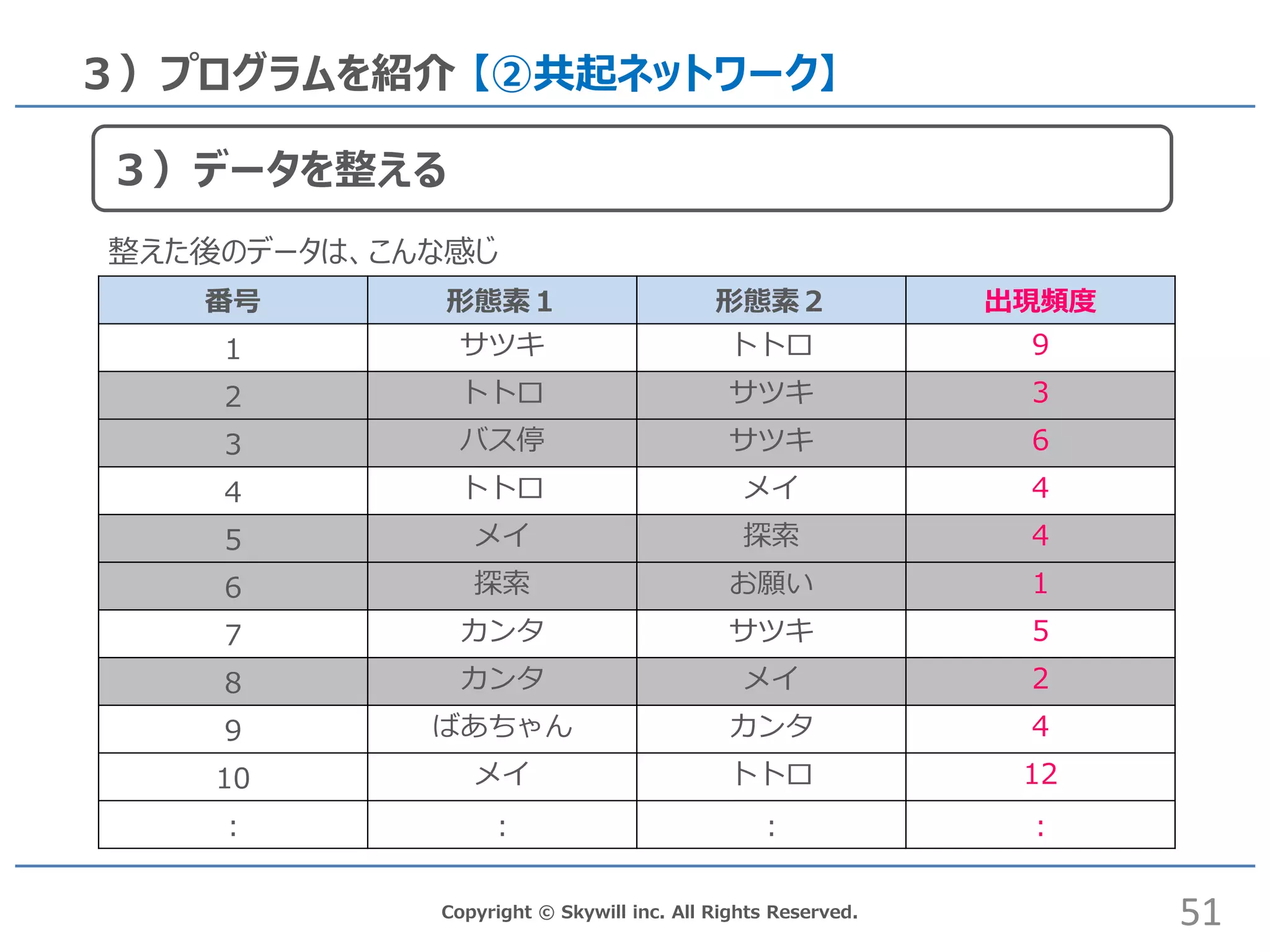
inc. All Rights Reserved. 2)テキストマイニングの流れ 3)データを整える 竹 藪 3回立て掛ける 出現頻度で並べ替え 4回 1回 竹 藪 立て掛ける 4回 3回 1回 次の工程で実施するデータマイニングをしやすくするための処理です。 データを並べ替えたり、データを分類分けしたり、特定データ抽出をします。 21
22.
Copyright © Skywill
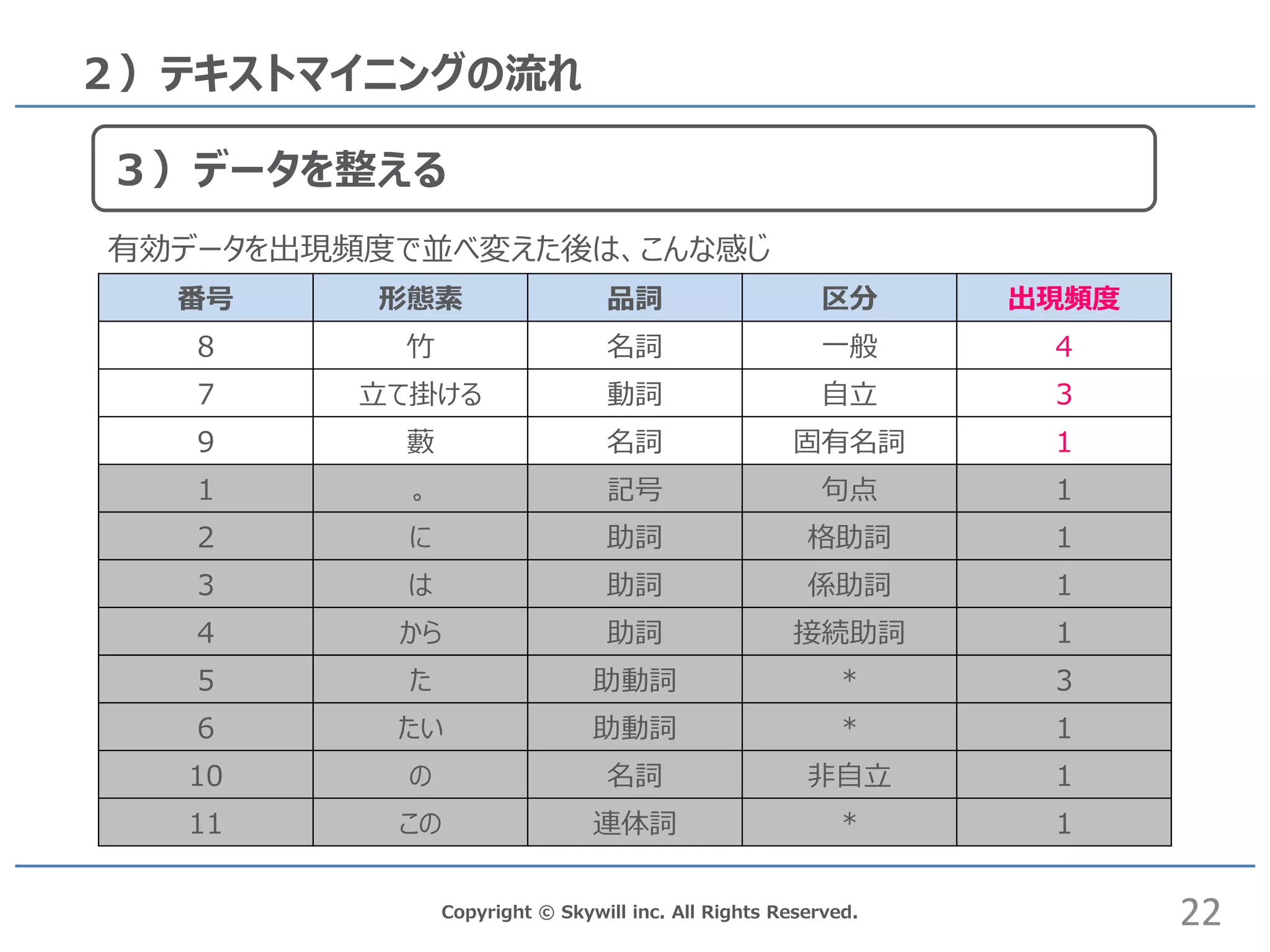
inc. All Rights Reserved. 2)テキストマイニングの流れ 番号 形態素 品詞 区分 出現頻度 8 竹 名詞 一般 4 7 立て掛ける 動詞 自立 3 9 藪 名詞 固有名詞 1 1 。 記号 句点 1 2 に 助詞 格助詞 1 3 は 助詞 係助詞 1 4 から 助詞 接続助詞 1 5 た 助動詞 * 3 6 たい 助動詞 * 1 10 の 名詞 非自立 1 11 この 連体詞 * 1 有効データを出現頻度で並べ変えた後は、こんな感じ 22 3)データを整える
23.
Copyright © Skywill
inc. All Rights Reserved. 2)テキストマイニングの流れ 4)データをマイニングする マイニング 竹 藪 立て掛ける 4回 3回 1回 0 1 2 3 4 23 データを統計グラフ化する。 竹 立て掛ける 藪 竹 立て掛 ける 藪
24.
Copyright © Skywill
inc. All Rights Reserved. 2)テキストマイニングの流れ R言語には、データを統計グラフ化するためのライブラリが豊富にある。 プログラマは、このライブラリを使うだけ(楽ちん)。 今回使用するライブラリは、後ほど紹介。 24 4)データをマイニングする
25.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 1)テキストマイニングの紹介 内容 3)プログラムを紹介 2)テキストマイニングの流れ 25
26.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 まず、準備として、紹介するプログラムの中で使用する ライブラリパッケージをインストールします。 【注意】 本スライドの対象者は、R言語の初級者なので、すでにプログラミング環境がある事を 前提として話を進めます。 RMecab wordcloud igraph 形態素解析の機能を提供 ワードクラウドの機能を提供 共起ネットワークの機能を提供 26 > install.packages("RMeCab", repos = "http://rmecab.jp/R") > install.packages("wordcloud") > install.packages(“igraph") インストールコマンド あーるめかぶ あいぐらふ
27.
Copyright © Skywill
inc. All Rights Reserved. ① ワードクラウド 3)プログラムを紹介 紹介するプログラムは、以下の2つ。 ② 共起ネットワーク 登場ワードの出現頻度を解析してワードクラウド表示する。 登場ワードの関係性をネットワーク表示する。 27
28.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 テキスト化した自社のホームページ情報をマイニングして、 登場頻度の高いワードをワードクラウドで直感的に表現する。 SKYWILLってこんな会社 28 ① ワードクラウド
29.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 「ワードクラウド」の流れ 1)文章を分解してデータを得る 3)データを整える (頻度の高いワードを抽出、並び変え) 2)データからゴミを取り除く(名詞以外の情報を取り除く) 4)データをマイニングする (ワードクラウドで表示する) 29
30.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 # ライブラリパッケージ読み込み library(RMeCab) library(wordcloud) # 1)文章を分解してデータを得る word <- RMeCabFreq("./SkyWill.txt") # 2)データからゴミを取り除く word <- subset(word, Info1 == "名詞") type <- c("数","非自立","接尾") word <- subset(word, !Info2 %in% type) # 3)データを整える word <- word[order(word$Freq, decreasing=T), ] word <- head(word, n=30) # 4)データをマイニングする(ワードクラウド表示) patern <- brewer.pal(8, "Dark2") wordcloud(word$Term, word$Freq, min.freq = 1, colors=patern) WordCloud.R 30
31.
Copyright © Skywill
inc. All Rights Reserved. # 1)文字列を分解してデータを得る word <- RMeCabFreq("./SkyWill.txt") 3)プログラムを紹介 【①ワードクラウド】 RMeCabFreq() WordCloud.R テキストを形態素に分解し、形態素ごとの出現頻度を取得する関数。 番号 形態素 品詞 区分 出現頻度 以下のフォーマットのデータ(データフレーム型)が得られる RMecabライブラリが提供する関数。 31 1)文章を分解してデータを得る 対象テキスト
32.
1)文章を分解してデータを得る Copyright © Skywill
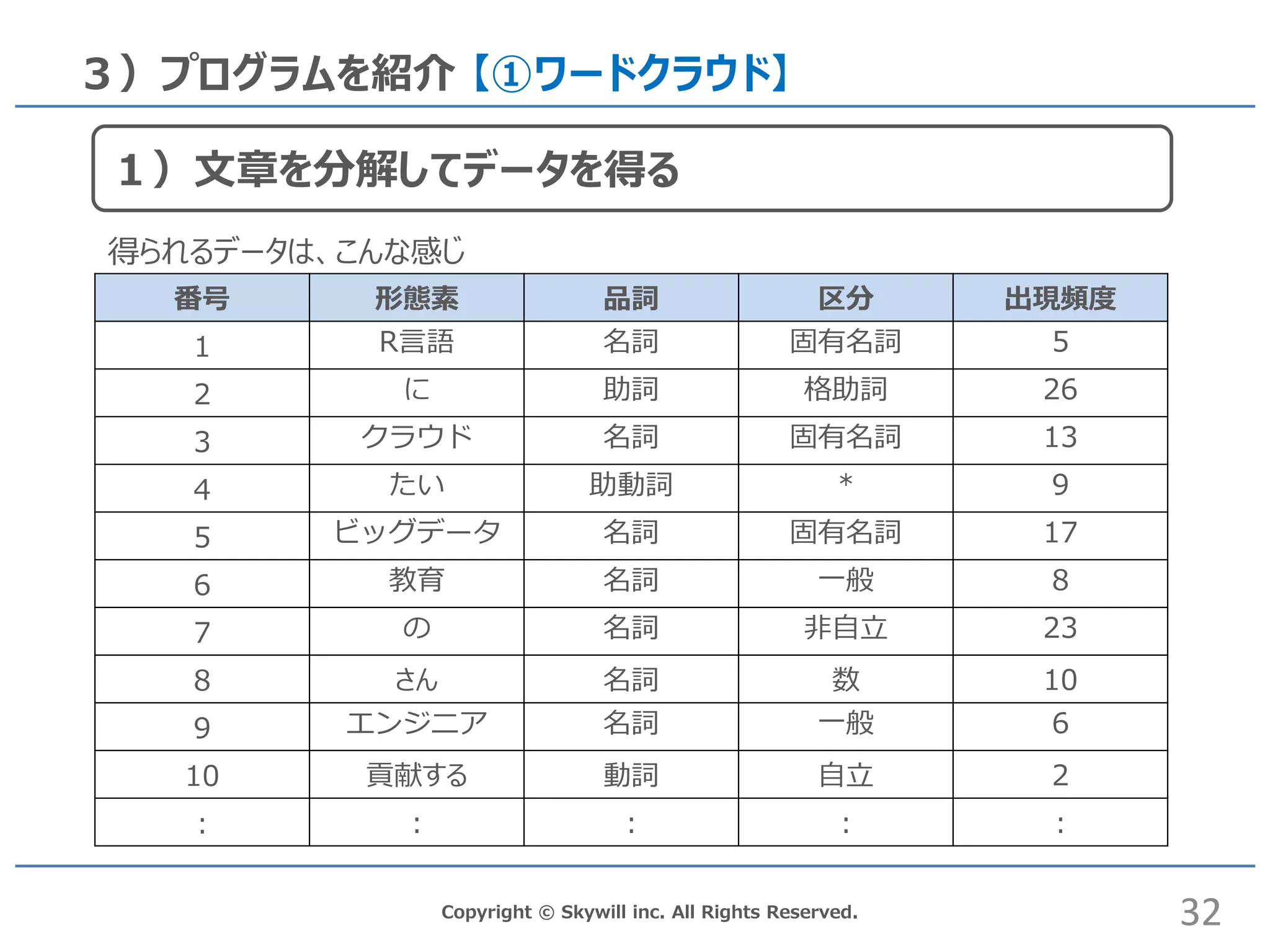
inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 得られるデータは、こんな感じ 番号 形態素 品詞 区分 出現頻度 1 R言語 名詞 固有名詞 5 2 に 助詞 格助詞 26 3 クラウド 名詞 固有名詞 13 4 たい 助動詞 * 9 5 ビッグデータ 名詞 固有名詞 17 6 教育 名詞 一般 8 7 の 名詞 非自立 23 8 さん 名詞 数 10 9 エンジニア 名詞 一般 6 10 貢献する 動詞 自立 2 : : : : : 32
33.
# 2)データからゴミを取り除く word <-
subset(word, Info1 == "名詞") type <- c("数","非自立","接尾") word <- subset(word, !Info2 %in% type) Copyright © Skywill inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 WordCloud.R 得られたデータから名詞以外をゴミ情報として取り除く。 33 2)データからゴミを取り除く
34.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 番号 形態素 品詞 区分 出現頻度 1 R言語 名詞 固有名詞 5 2 に 助詞 格助詞 26 3 クラウド 名詞 固有名詞 13 4 たい 助動詞 * 9 5 ビッグデータ 名詞 固有名詞 17 6 教育 名詞 一般 8 7 の 名詞 非自立 23 8 さん 名詞 数 10 9 エンジニア 名詞 一般 6 10 貢献する 動詞 自立 2 : : : : : 34 2)データからゴミを取り除く ゴミを取り除いた後のデータは、こんな感じ
35.
# 2)データからゴミを取り除く word <-
subset(word, Info1 == "名詞") type <- c("数","非自立","接尾") word <- subset(word, !Info2 %in% type) Copyright © Skywill inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 WordCloud.R さらに、名詞のうち、”数“、“非自立”、“接尾”に該当するデータを ゴミ情報として取り除く。 35 2)データからゴミを取り除く
36.
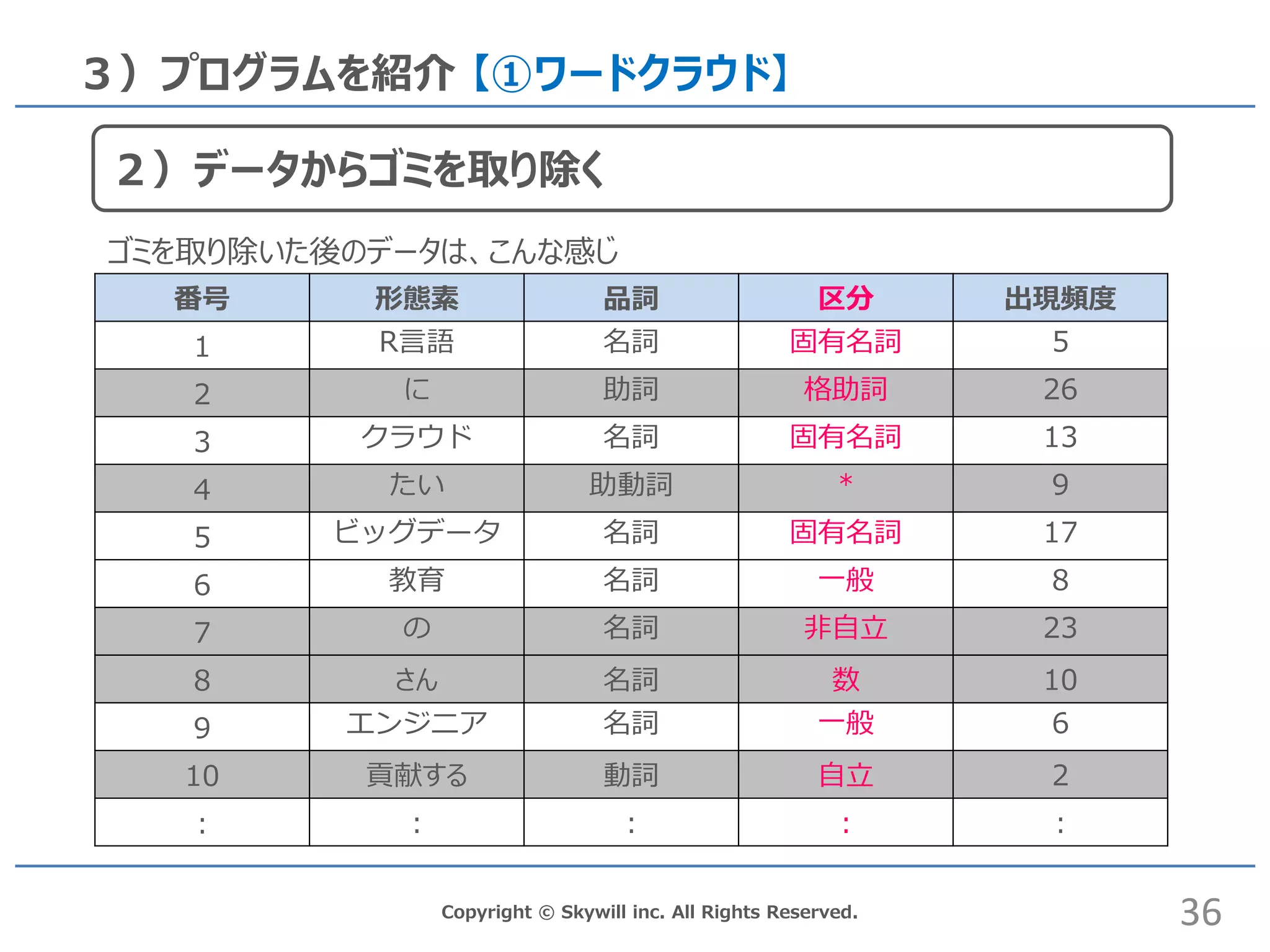
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 番号 形態素 品詞 区分 出現頻度 1 R言語 名詞 固有名詞 5 2 に 助詞 格助詞 26 3 クラウド 名詞 固有名詞 13 4 たい 助動詞 * 9 5 ビッグデータ 名詞 固有名詞 17 6 教育 名詞 一般 8 7 の 名詞 非自立 23 8 さん 名詞 数 10 9 エンジニア 名詞 一般 6 10 貢献する 動詞 自立 2 : : : : : 36 2)データからゴミを取り除く ゴミを取り除いた後のデータは、こんな感じ
37.
# 3)データを整える word <-
word[order(word$Freq, decreasing=T), ] word <- head(word, n=30) Copyright © Skywill inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 WordCloud.R 登場頻度の高い順で並べ替える。 登場頻度の上位30個のデータを抽出する。 37 3)データを整える
38.
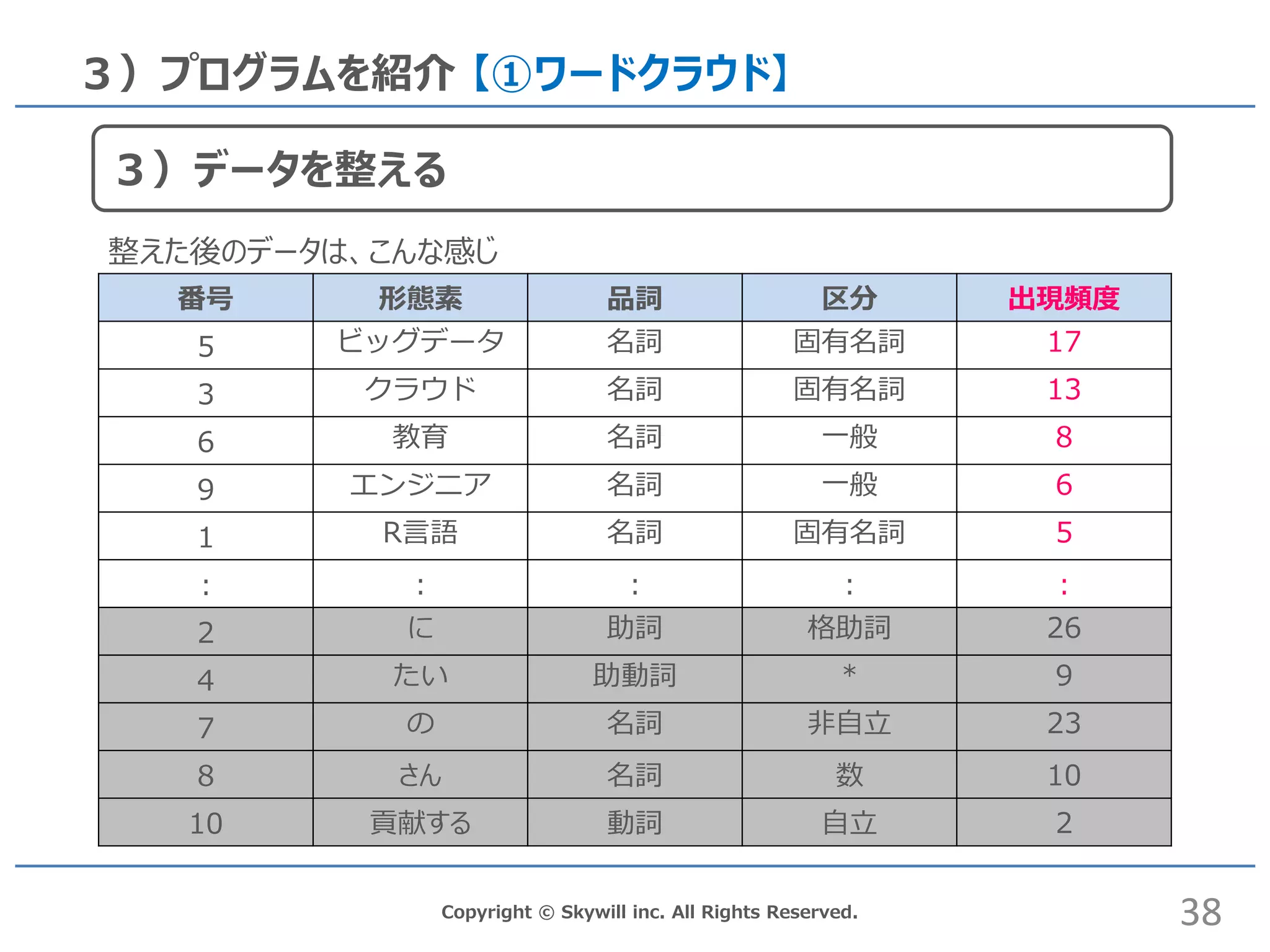
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 番号 形態素 品詞 区分 出現頻度 5 ビッグデータ 名詞 固有名詞 17 3 クラウド 名詞 固有名詞 13 6 教育 名詞 一般 8 9 エンジニア 名詞 一般 6 1 R言語 名詞 固有名詞 5 : : : : : 2 に 助詞 格助詞 26 4 たい 助動詞 * 9 7 の 名詞 非自立 23 8 さん 名詞 数 10 10 貢献する 動詞 自立 2 38 3)データを整える 整えた後のデータは、こんな感じ
39.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 WordCloud.R # 4)データをマイニングする(ワードクラウド) patern <- brewer.pal(8, "Dark2") wordcloud(word$Term, word$Freq, min.freq = 1, colors=patern) wordcloud() wordcloudライブラリが提供する関数。 39 4)データをマイニングする 形態素データを使って、統計解析(ワードクラウド表示)する。 形態素名 出現頻度 対象を出現頻度 1回以上の形態素とする 色の表示パターン
40.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【①ワードクラウド】 表示されるデータは、こんな感じ 40 4)データをマイニングする
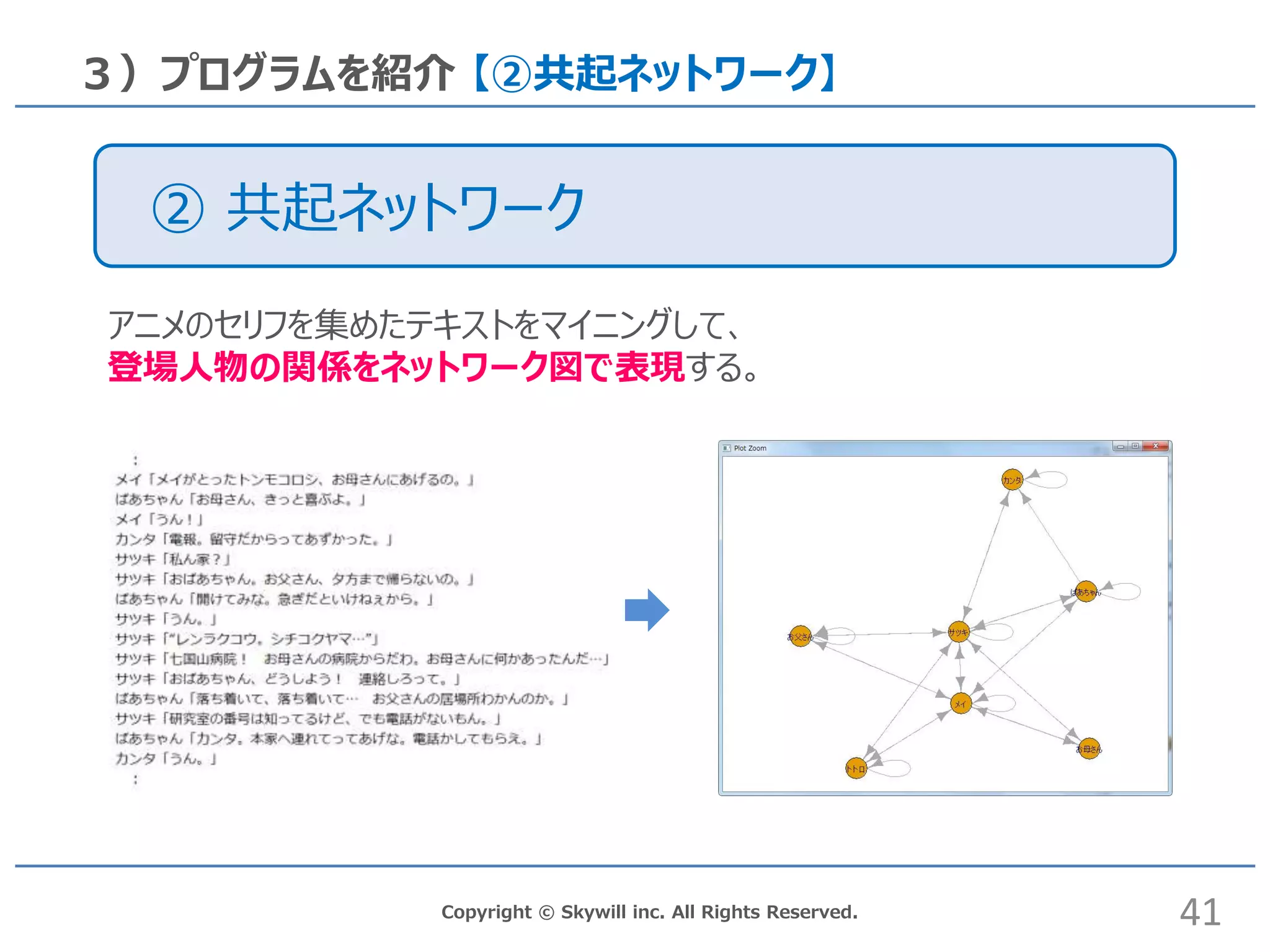
41.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 アニメのセリフを集めたテキストをマイニングして、 登場人物の関係をネットワーク図で表現する。 41 ② 共起ネットワーク
42.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 「共起ネットワーク」の流れ 1)文章を分解してデータを得る 3)データを整える (共起性の強いデータを抽出する) 2)データからゴミを取り除く(登場人物以外を取り除く) 4)データをマイニングする (ネットワーク図で表示する) 42
43.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 # ライブラリパッケージ読み込み library(RMeCab) library(igraph) # 1)文章を分解してデータを得る ngram <- NgramDF("./Totoro.txt", type=1, pos=c("名詞"), N=2) # 2)データからゴミを取り除く char= c("トトロ", "サツキ", "メイ", "お父さん", "お母さん", "カンタ", "ばあちゃん") ngram <- subset(ngram, (Ngram1 %in% char)&(Ngram2 %in% char)) # 3)データを整える ngram <- subset(ngram, Freq>=4) # 4)データをマイニングする(ネットワーク図表示) graph <- graph.data.frame(ngram) plot(graph, vertex.label=V(graph)$name, vertex.size=15) Network.R 43
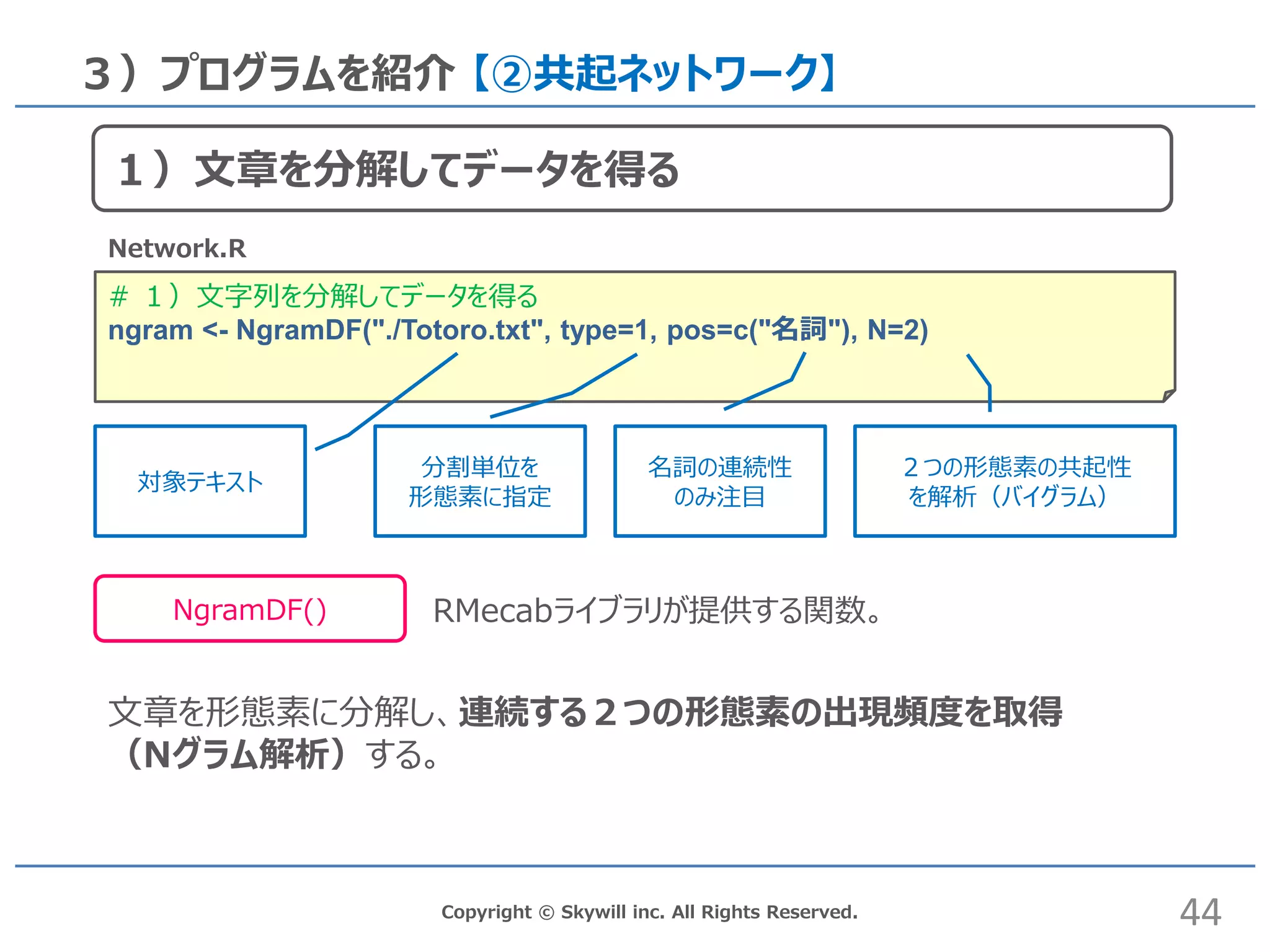
44.
Copyright © Skywill
inc. All Rights Reserved. # 1)文字列を分解してデータを得る ngram <- NgramDF("./Totoro.txt", type=1, pos=c("名詞"), N=2) 3)プログラムを紹介 【②共起ネットワーク】 NgramDF() Network.R 文章を形態素に分解し、連続する2つの形態素の出現頻度を取得 (Nグラム解析)する。 RMecabライブラリが提供する関数。 44 1)文章を分解してデータを得る 対象テキスト 分割単位を 形態素に指定 名詞の連続性 のみ注目 2つの形態素の共起性 を解析(バイグラム)
45.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 バス停で、サツキはトトロに出会った。 バス停 で サツキ は トトロ 出会ったに バス停 サツキ トトロ 形態素に分解 名詞の連続性だけに注目 45 1)文章を分解してデータを得る 番号 形態素1 形態素2 出現頻度 1 バス停 サツキ 1 2 サツキ トトロ 1 連続する2つの形態素の出現頻度を取得 バイグラムデータ
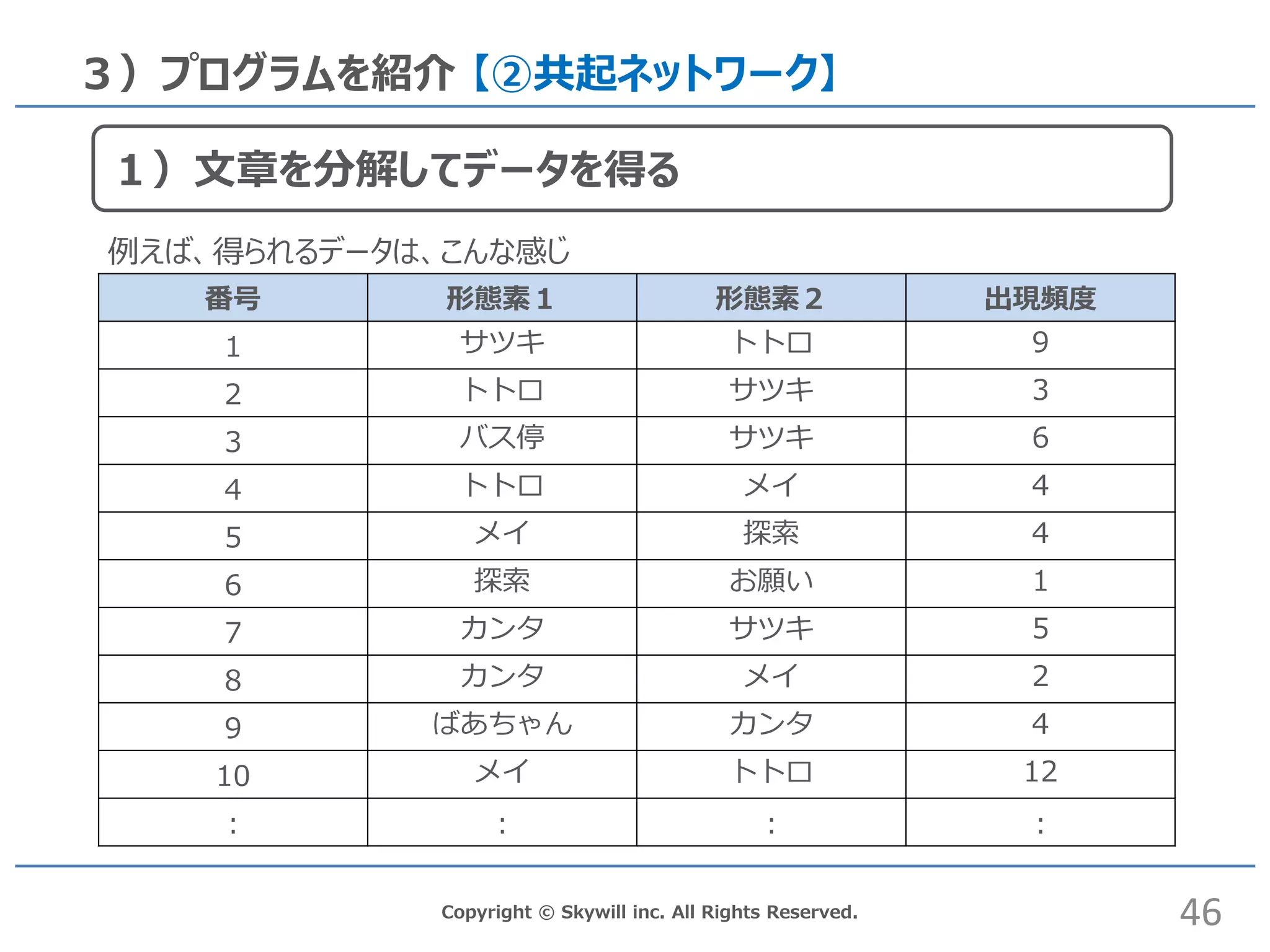
46.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 番号 形態素1 形態素2 出現頻度 1 サツキ トトロ 9 2 トトロ サツキ 3 3 バス停 サツキ 6 4 トトロ メイ 4 5 メイ 探索 4 6 探索 お願い 1 7 カンタ サツキ 5 8 カンタ メイ 2 9 ばあちゃん カンタ 4 10 メイ トトロ 12 : : : : 46 1)文章を分解してデータを得る 例えば、得られるデータは、こんな感じ
47.
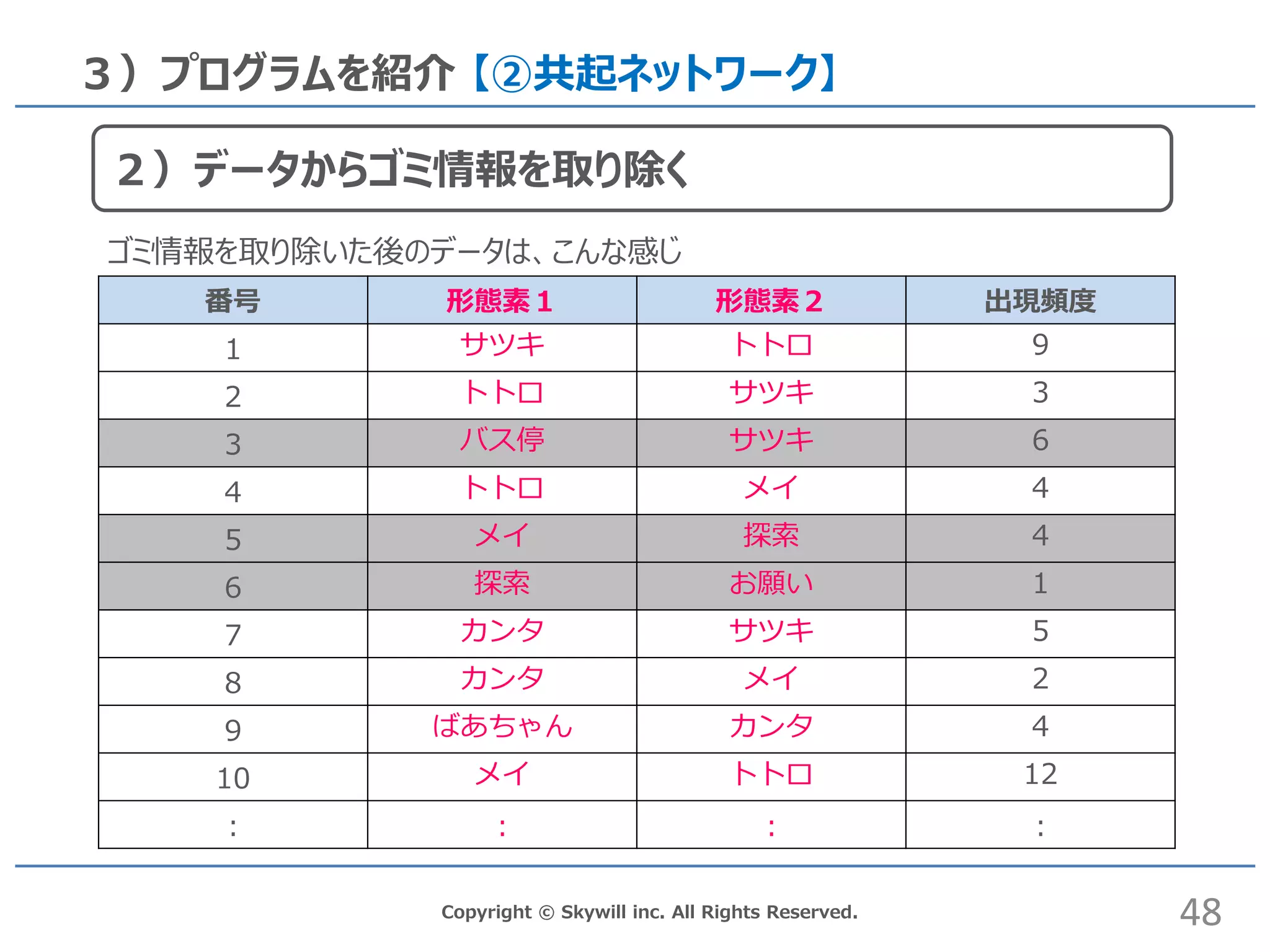
# 2)データからゴミを取り除く char= c("トトロ",
"サツキ", "メイ", "お父さん", "お母さん", "カンタ", "ばあちゃん") ngram <- subset(ngram, (Ngram1 %in% char)&(Ngram2 %in% char)) Copyright © Skywill inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 Network.R 得られたデータから登場人物以外をゴミ情報として取り除く。 形態素1、形態素2共に、登場人物に該当するデータだけを 有効データとみなす。 47 2)データからゴミ情報を取り除く
48.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 番号 形態素1 形態素2 出現頻度 1 サツキ トトロ 9 2 トトロ サツキ 3 3 バス停 サツキ 6 4 トトロ メイ 4 5 メイ 探索 4 6 探索 お願い 1 7 カンタ サツキ 5 8 カンタ メイ 2 9 ばあちゃん カンタ 4 10 メイ トトロ 12 : : : : 48 2)データからゴミ情報を取り除く ゴミ情報を取り除いた後のデータは、こんな感じ
49.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 登場人物で絞り込みしないで、ネットワーク図を表示すると 情報が多すぎて、ぐちゃぐちゃに Σ( ̄ロ ̄lll) orz 49 2)データからゴミ情報を取り除く
50.
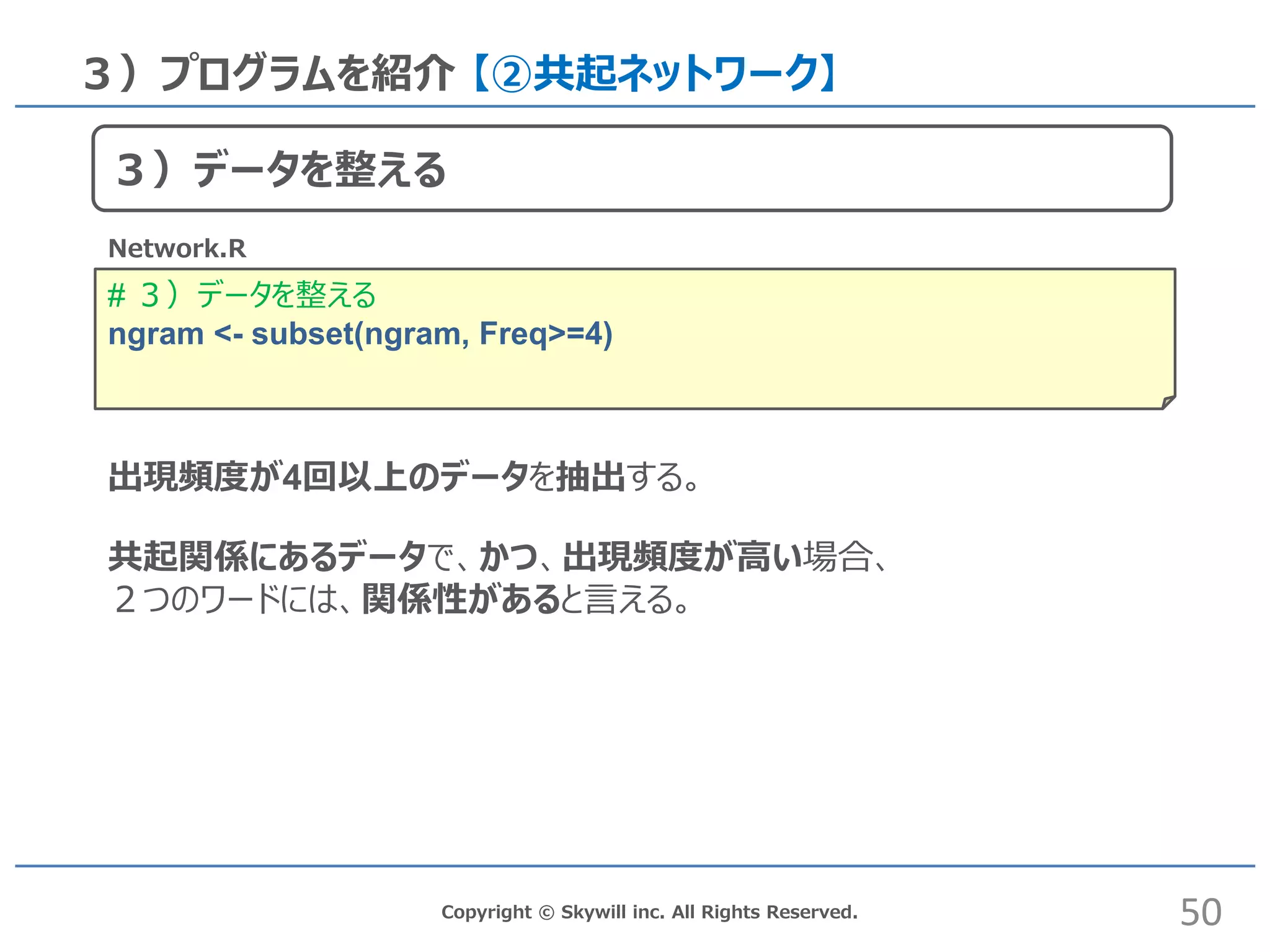
# 3)データを整える ngram <-
subset(ngram, Freq>=4) Copyright © Skywill inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 Network.R 出現頻度が4回以上のデータを抽出する。 共起関係にあるデータで、かつ、出現頻度が高い場合、 2つのワードには、関係性があると言える。 50 3)データを整える
51.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 番号 形態素1 形態素2 出現頻度 1 サツキ トトロ 9 2 トトロ サツキ 3 3 バス停 サツキ 6 4 トトロ メイ 4 5 メイ 探索 4 6 探索 お願い 1 7 カンタ サツキ 5 8 カンタ メイ 2 9 ばあちゃん カンタ 4 10 メイ トトロ 12 : : : : 51 3)データを整える 整えた後のデータは、こんな感じ
52.
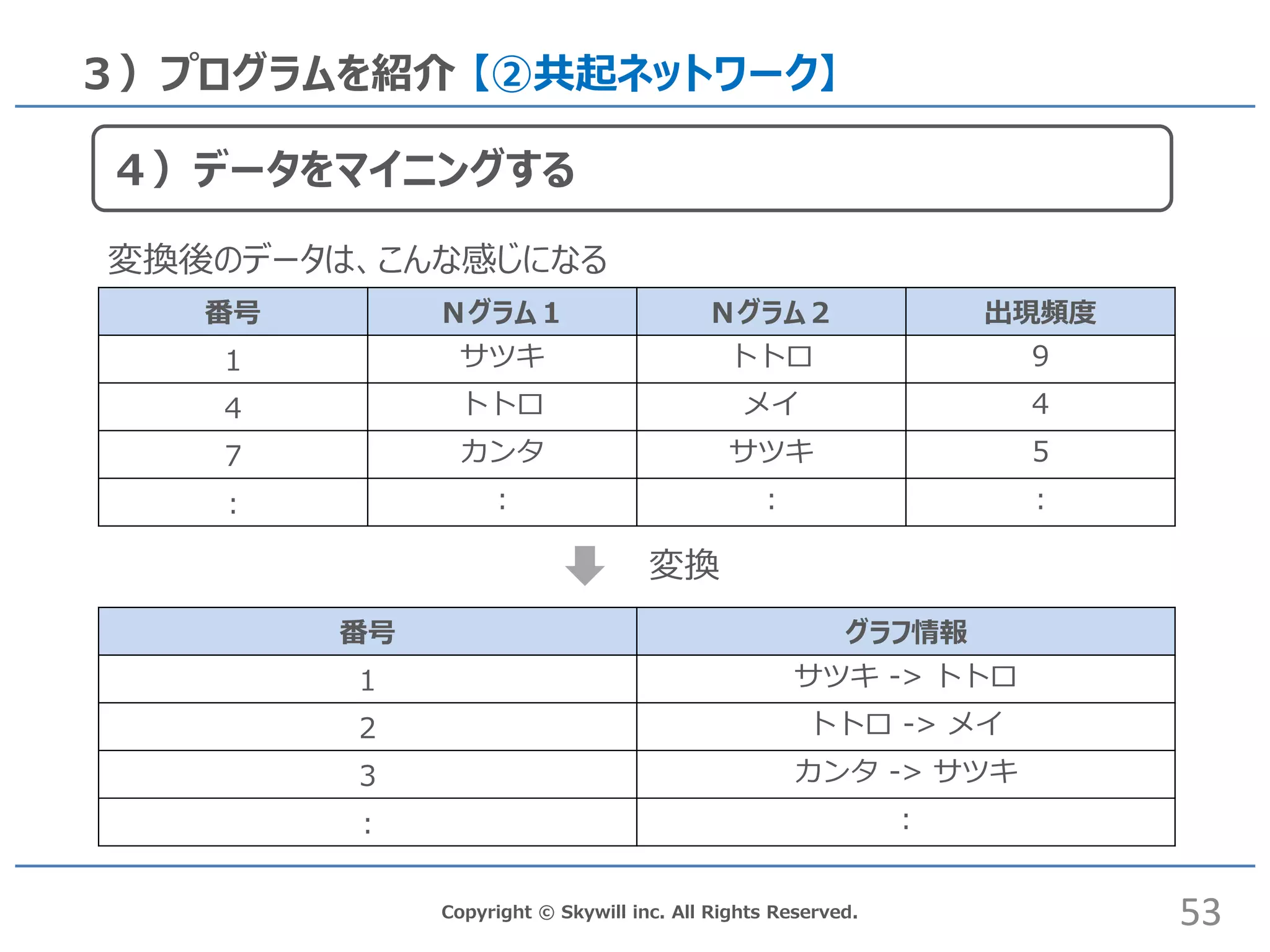
# 4)データをマイニングする(ネットワーク図表示) graph <-
graph.data.frame(ngram) plot(graph, vertex.label=V(graph)$name, vertex.size=15) Copyright © Skywill inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 Network.R graph.data.frame() バイグラムデータをグラフ表示用データに変換する。 52 4)データをマイニングする igraphライブラリが提供する関数。 バイグラムデータ
53.
Copyright © Skywill
inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 番号 Nグラム1 Nグラム2 出現頻度 1 サツキ トトロ 9 4 トトロ メイ 4 7 カンタ サツキ 5 : : : : 番号 グラフ情報 1 サツキ -> トトロ 2 トトロ -> メイ 3 カンタ -> サツキ : : 変換 53 4)データをマイニングする 変換後のデータは、こんな感じになる
54.
# 4)データをマイニングする(ネットワーク図表示) graph <-
graph.data.frame(ngram) plot(graph, vertex.label=V(graph)$name, vertex.size=15) Copyright © Skywill inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 Network.R plot() R言語の組み込み関数。 グラフ表示用データを使って、統計解析(ネットワーク図表示)する。 54 4)データをマイニングする グラフデータのノード名 (トトロ、サツキなど) ネットワーク図の ノード(丸)のサイズ
55.
Copyright © Skywill
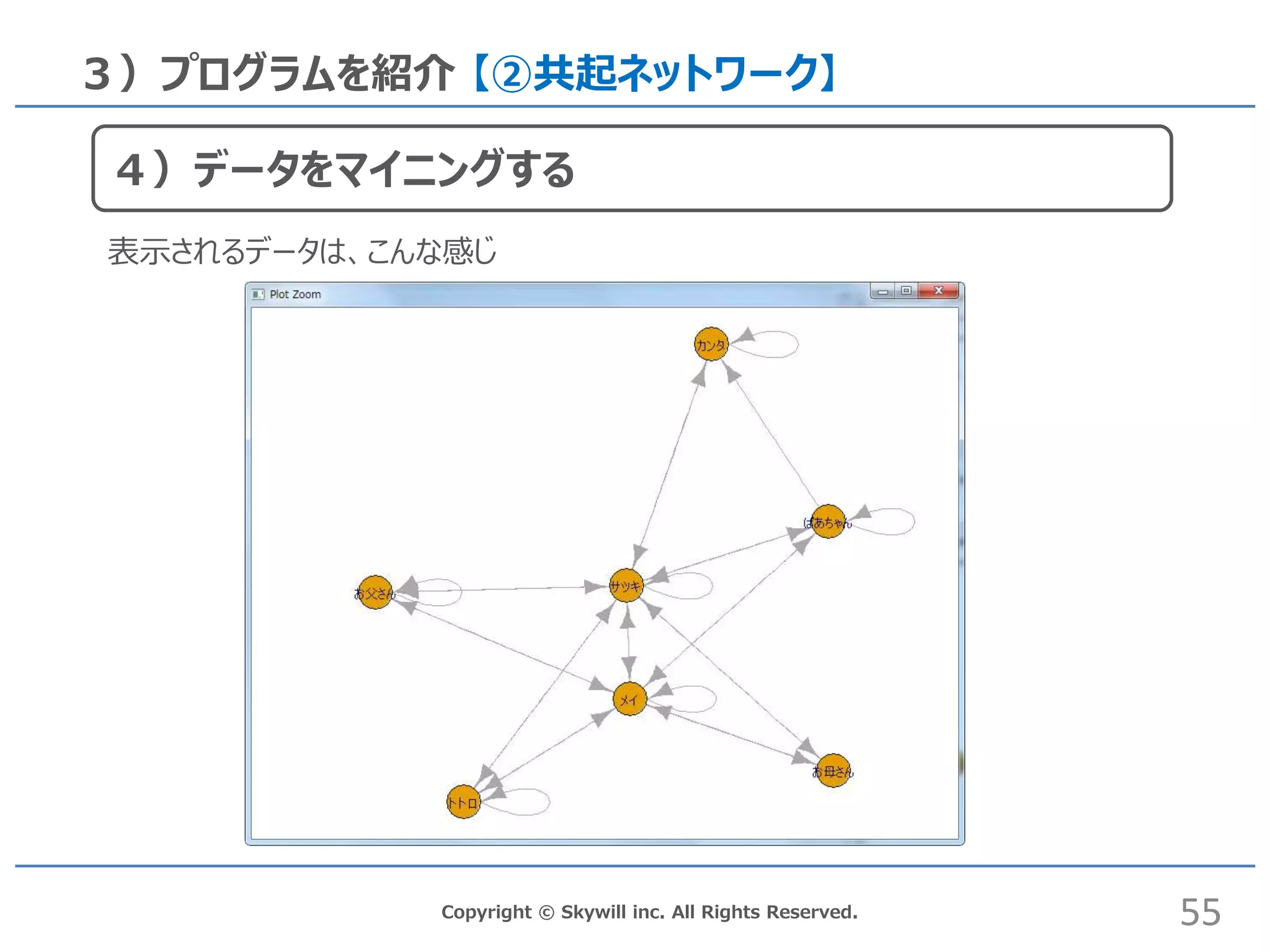
inc. All Rights Reserved. 3)プログラムを紹介 【②共起ネットワーク】 55 4)データをマイニングする 表示されるデータは、こんな感じ
56.
Copyright © Skywill
inc. All Rights Reserved. まとめ (おさえるべきポイント) 形態素解析を理解すること テキストマイニング処理の流れを理解すること 文章を最小構成要素(形態素)に分解する技術 (8ページ参照)。 R言語では、RMecabライブラリで実現できる。 56 1)文章を分解してデータを得る 3)データを整える 2)データからゴミを取り除く 4)データをマイニングする 流れは、以下の4段階(16~24ページ参照)。 形態素解析、Nグラム解析 データクレンジング(ノイズ除去) 並べ替え、抽出、分類分けなど ワードクラウド、ネットワーク図など
57.
Copyright © Skywill
inc. All Rights Reserved. 参考文献 Rで学ぶ日本語テキストマイニング 石田基広・小林雄一郎 著 みんなのR データ分析と統計解析の新しい教科書 Jared P. Lander [著] 高柳慎一、牧山幸史、簑田高志 [訳] Tokyo.R [協力] 57
Download














![Copyright © Skywill inc. All Rights Reserved.
3)プログラムを紹介 【①ワードクラウド】
# ライブラリパッケージ読み込み
library(RMeCab)
library(wordcloud)
# 1)文章を分解してデータを得る
word <- RMeCabFreq("./SkyWill.txt")
# 2)データからゴミを取り除く
word <- subset(word, Info1 == "名詞")
type <- c("数","非自立","接尾")
word <- subset(word, !Info2 %in% type)
# 3)データを整える
word <- word[order(word$Freq, decreasing=T), ]
word <- head(word, n=30)
# 4)データをマイニングする(ワードクラウド表示)
patern <- brewer.pal(8, "Dark2")
wordcloud(word$Term, word$Freq, min.freq = 1, colors=patern)
WordCloud.R
30](https://image.slidesharecdn.com/textminingrstartupv1-160303135137/75/R-30-2048.jpg)



![# 3)データを整える
word <- word[order(word$Freq, decreasing=T), ]
word <- head(word, n=30)
Copyright © Skywill inc. All Rights Reserved.
3)プログラムを紹介 【①ワードクラウド】
WordCloud.R
登場頻度の高い順で並べ替える。
登場頻度の上位30個のデータを抽出する。
37
3)データを整える](https://image.slidesharecdn.com/textminingrstartupv1-160303135137/75/R-37-2048.jpg)










![Copyright © Skywill inc. All Rights Reserved.
参考文献
Rで学ぶ日本語テキストマイニング
石田基広・小林雄一郎 著
みんなのR
データ分析と統計解析の新しい教科書
Jared P. Lander [著]
高柳慎一、牧山幸史、簑田高志 [訳]
Tokyo.R [協力]
57](https://image.slidesharecdn.com/textminingrstartupv1-160303135137/75/R-57-2048.jpg)






































































