Downloaded 15 times




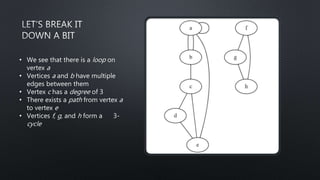

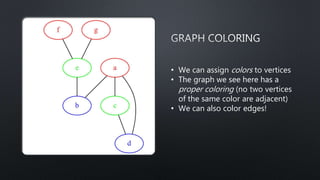






![import networkx as nx
import matplotlib.pyplot as plt
G = nx.Graph()
vertices = []
for x in range(1, 6):
vertices.append(x)
G.add_nodes_from(vertices)
G.add_edges_from([(1, 2), (2, 3), (5, 4),
(4, 2), (1, 3), (5, 1), (5, 2), (3, 4)])
pos = nx.spring_layout(G)
nx.draw_networkx_nodes(G, pos, node_size=20)
nx.draw_networkx_edges(G, pos, width=5)
nx.draw_networkx_labels(G, pos,
font_size=14)
nx.draw(G, pos)
plt.show()](https://image.slidesharecdn.com/pydatanyc-190110221035/85/Graph-Analytics-From-the-Whiteboard-to-Your-Toolbox-Sam-Lerma-28-320.jpg)
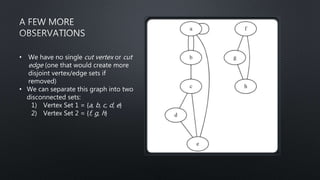
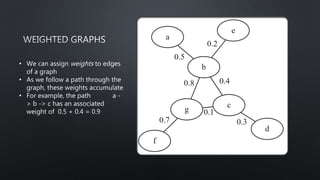
![import networkx as nx
import matplotlib.pyplot as plt
G = nx.Graph()
G.add_nodes_from(['a', 'b', 'c'])
G.add_edge('a', 'b', weight=0.5)
G.add_edge('b', 'c', weight=0.2)
G.add_edge('c', 'a', weight=0.7)
pos = nx.spring_layout(G)
nx.draw_networkx_nodes(G, pos, node_size=500)
nx.draw_networkx_edges(G, pos, width=6)
nx.draw_networkx_labels(G, pos, font_size=14)
nx.draw_networkx_edge_labels(G, pos,
font_size=14)
nx.draw(G, pos)
plt.show()](https://image.slidesharecdn.com/pydatanyc-190110221035/85/Graph-Analytics-From-the-Whiteboard-to-Your-Toolbox-Sam-Lerma-29-320.jpg)
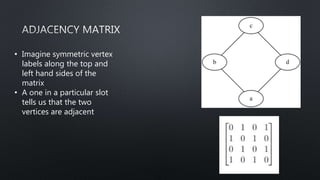
![>>> G.nodes()
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20]
>>> nx.shortest_path(G, 1, 18)
[1, 3, 18]
>>> G.degree()
{1: 4, 2: 3, 3: 4, 4: 4, 5: 4, 6: 3,
7: 3, 8: 3, 9: 4, 10: 3, 11: 2,
12: 2, 13: 2, 14: 4, 15: 3, 16: 3,
17: 2, 18: 3, 19: 3, 20: 3}](https://image.slidesharecdn.com/pydatanyc-190110221035/85/Graph-Analytics-From-the-Whiteboard-to-Your-Toolbox-Sam-Lerma-30-320.jpg)
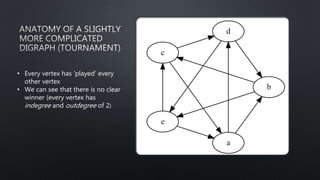
![import networkx as nx
import matplotlib.pyplot as plt
G = nx.DiGraph([(1, 2), (1, 3), (4, 1),
(1, 5), (2, 3), (2, 4), (2, 5), (3, 4),
(3, 5), (4, 5)])
pos = nx.circular_layout(G)
nx.draw_networkx_nodes(G, pos,
node_size=200)
nx.draw_networkx_edges(G, pos)
nx.draw_networkx_labels(G, pos,
fontsize=14)
>>> nx.has_path(G, 1, 5)
True
>>> nx.has_path(G, 5, 1)
False
>>> nx.shortest_path(G, 1, 4)
[1, 2, 4]](https://image.slidesharecdn.com/pydatanyc-190110221035/85/Graph-Analytics-From-the-Whiteboard-to-Your-Toolbox-Sam-Lerma-33-320.jpg)
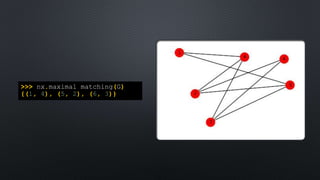


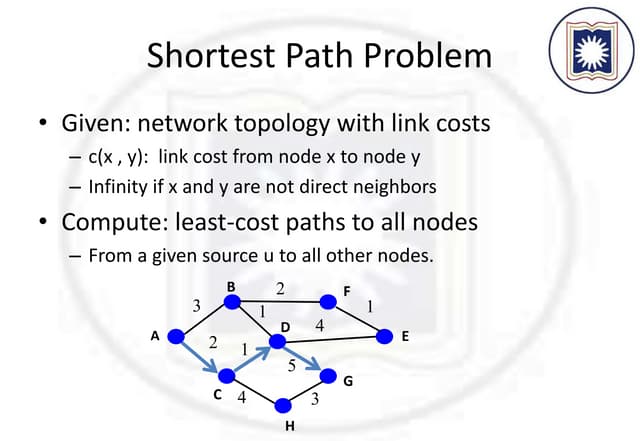
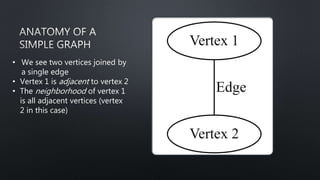
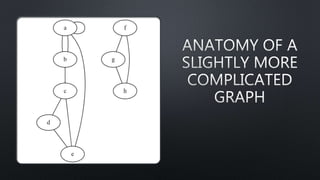
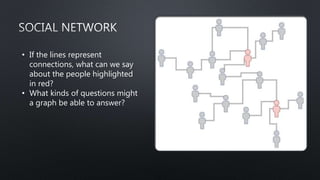
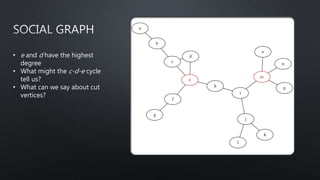
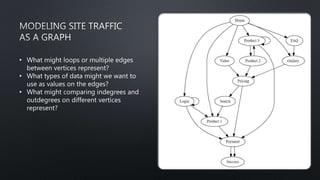
This document provides an introduction to graph theory concepts and working with graph data in Python. It begins with basic graph definitions and real-world graph examples. Various graph concepts are then demonstrated visually, such as vertices, edges, paths, cycles, and graph properties. Finally, it discusses working with graph data structures and algorithms in the NetworkX library in Python, including graph generation, analysis, and visualization. The overall goal is to introduce readers to graph theory and spark their interest in further exploration.