Downloaded 16 times








![Recap
JSON
JSON (JavaScript Object Notation) is a
lightweight data-interchange format.
It's like if XML and JavaScript slept together and gave birth a bastard but goodlooking child.
{"timestamp": "2011-08-15 22:17:31.334057",
"track_id": "TRACCJA128F149A144",
"tags": [["Bossa Nova", "100"],
["jazz", "20"],
["acoustic", "20"],
["romantic", "20"],],
"title": "Segredo",
"artist": "Jou00e3o Gilberto"}](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-8-320.jpg)
![Recap
Python generators
From Python's wiki:
“Generators functions allow you to declare a
function that behaves like an iterator, i.e. it
can be used in a for loop.”
The difference is: a generator can be iterated (or read)
only once as you don't store things in memory but create
them on the fly [2].
You can create generators using the yield keyword.](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-9-320.jpg)








![Phases of a MapReduction
MapReduce have the following steps:
map(key, value) -> [(key1, value1), (key1, value2)]
combine
May happen in parallel, in multiple
machines!
sort + shuffle
reduce(key1, [value1, value2]) -> [(keyX, valueY)]](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-18-320.jpg)
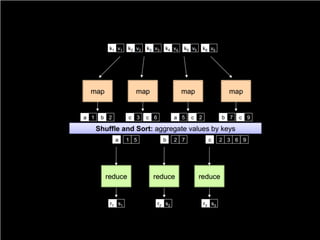




![Counting word - in Python
doc = open('input')
count = {}
for line in doc:
words = line.split()
for w in words:
count[w] = count.get(w, 0) + 1
Easy, right? Yeah... too easy. Let's split what
we do for each line and aggregate, shall we?](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-24-320.jpg)





![What's Shuffle output? or
What's Reducer input?
Key
(input) Values
correr
[1]
Notice:
gusta
[1, 1]
gustas
[1, 1]
la
[1]
lluvia
[1]
me
[1, 1, 1, 1]
tu
[1, 1]
This table represents a global
view.
"In real life", each reducer
instance only knows about its
own key and values.](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-30-320.jpg)
![What's Reducer output?
def reduce_sum_words(self, word, occurrences):
yield word, sum(occurrences)
word
occurrences
output
correr
[1]
(correr, 1)
gusta
[1, 1]
(gusta, 2)
gustas
[1, 1]
(gustas, 2)
la
[1]
(la, 1)
lluvia
[1]
(lluvia, 1)
me
[1, 1, 1, 1]
(me, 4)
tu
[1, 1]
(tu, 2)](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-31-320.jpg)




![Counting words
Full MrJob Example
from mrjob.job import MRJob
class MRWordCounter(MRJob):
def get_words(self, key, line):
for word in line.split():
yield word, 1
def sum_words(self, word, occurrences):
yield word, sum(occurrences)
def steps(self):
return [self.mr(self.get_words, self.sum_words),]
if __name__ == '__main__':
MRWordCounter.run()](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-36-320.jpg)





![zezin, fulano, [telefone, celulares, vivo]
zezin, fulano, [telefone, celulares, vivo]
Map input
zezin, fulano, [eletro, caos, furadeira]
lojaX, fulano, [livros, arte, anime]
lojaX, fulano, [livros, arte, anime]
lojaX, fulano, [livros, arte, anime]](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-42-320.jpg)
![zezin, fulano, [telefone, celulares, vivo]
zezin, fulano, [telefone, celulares, vivo]
Map input
zezin, fulano, [eletro, caos, furadeira]
lojaX, fulano, [livros, arte, anime]
lojaX, fulano, [livros, arte, anime]
lojaX, fulano, [livros, arte, anime]
Key](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-43-320.jpg)
![zezin, fulano, [telefone, celulares, vivo]
zezin, fulano, [telefone, celulares, vivo]
Map input
zezin, fulano, [eletro, caos, furadeira]
lojaX, fulano, [livros, arte, anime]
lojaX, fulano, [livros, arte, anime]
lojaX, fulano, [livros, arte, anime]
Key
Sort + Shuffle
[telefone, celulares, vivo]
(zezin, fulano)
[telefone, celulares, vivo]
[eletro, caos, furadeira]
Reduce Input
[livros, arte, anime]
(lojaX, fulano)
[livros, arte, anime]
[livros, arte, anime]](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-44-320.jpg)
![[telefone, celulares, vivo]
(zezin, fulano)
[telefone, celulares, vivo]
[eletro, caos, furadeira]
Reduce Input
[livros, arte, anime]
(lojaX, fulano)
[livros, arte, anime]
[livros, arte, anime]](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-45-320.jpg)
![[telefone, celulares, vivo]
(zezin, fulano)
[telefone, celulares, vivo]
[eletro, caos, furadeira]
Reduce Input
[livros, arte, anime]
(lojaX, fulano)
[livros, arte, anime]
[livros, arte, anime]
(zezin, fulano)
([telefone, celulares, vivo], 2)
([eletro, caos, furadeira], 1)
Reduce Output
(lojaX, fulano)
([livros, arte, anime], 3)](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-46-320.jpg)

![BuyOrders
Products
Map Input
lojaX
livro
fulano
R$ 20
lojaX
iphone
deltrano
R$ 1800
lojaX
livro
[livros, arte, anime]
lojaX
iphone
[telefone, celulares, vivo]
We have to merge
those tables above!](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-48-320.jpg)
![BuyOrders
Products
Map Input
lojaX
livro
fulano
R$ 20
lojaX
iphone
deltrano
R$ 1800
lojaX
livro
[livros, arte, anime]
lojaX
iphone
[telefone, celulares, vivo]
common
Key](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-49-320.jpg)
![BuyOrders
Products
Map Input
Map Output
lojaX
livro
fulano
R$ 20
(nada, é barato)
lojaX
iphone
deltrano
R$ 1800
{”usuario” : “deltrano”}
lojaX
livro
[livros, arte, anime]
{“cat”: [livros...]}
lojaX
iphone
[telefone, celulares, vivo]
{“cat”: [telefone...]}
Key
Value](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-50-320.jpg)
![BuyOrders
Products
Map Input
Map Output
lojaX
livro
fulano
R$ 20
(nada, é barato)
lojaX
iphone
deltrano
R$ 1800
{”usuario” : “deltrano”}
lojaX
livro
[livros, arte, anime]
{“cat”: [livros...]}
lojaX
iphone
[telefone, celulares, vivo]
{“cat”: [telefone...]}
Reduce Input
Key
Value
(lojaX, livro)
{“cat”: [livros, arte, anime]}
(lojaX, iphone)
{”usuario” : “deltrano”}
{“cat”: [telefone, celulares, vivo]}](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-51-320.jpg)
![Reduce Input
(lojaX, livro)
{“cat”: [livros, arte, anime]}
(lojaX, iphone)
{”usuario” : “deltrano”}
{“cat”: [telefone, celulares, vivo]}
Key
Values](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-52-320.jpg)
![Reduce Input
(lojaX, livro)
{“cat”: [livros, arte, anime]}
(lojaX, iphone)
{”usuario” : “deltrano”}
{“cat”: [telefone, celulares, vivo]}
Key
Values
Those are the parts we care
about!](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-53-320.jpg)
![Reduce Input
(lojaX, livro)
{“cat”: [livros, arte, anime]}
(lojaX, iphone)
{”usuario” : “deltrano”}
{“cat”: [telefone, celulares, vivo]}
Reduce Output
Key
(lojaX, deltrano)
Values
[telefone, celulares, vivo]](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-54-320.jpg)





![Million Song Dataset project's
Last.fm Dataset
JSONProcotol encodes key-pair information in
a single line using json-encoded values
separated by a tab character ( t ).
<JSON encoded data>
t
<JSON encoded data>
Exemple line:
"TRACHOZ12903CCA8B3" t {"timestamp": "2011-09-07 22:12:
47.150438", "track_id": "TRACHOZ12903CCA8B3", "tags": [],
"title": "Close Up", "artist": "Charles Williams"}](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-60-320.jpg)



![Reference & Further reading
[1] MapReduce: A Crash Course
[2] StackOverflow: The python yield keyword
explained
[3] Explicando iterables, generators e yield no
python
[4] MapReduce: Simplied Data Processing on
Large Clusters](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-64-320.jpg)
![Reference & Further reading
[5] MrJob 4.0 - Quick start
[6] Amazon EC2 Instance Types](https://image.slidesharecdn.com/ufcg-mapreduce1014-131031141404-phpapp01/85/MapReduce-teoria-e-pratica-65-320.jpg)






This document provides an overview of MapReduce, a computational model used for processing large data sets across distributed systems. It explains the structure of MapReduce tasks, including mapping and reducing phases, and discusses implementations in tools like Apache Hadoop and Amazon EMR, alongside practical examples such as counting words and analyzing real datasets. The document also includes recaps on important technologies such as Python, JSON, and AWS services commonly used in conjunction with MapReduce.





































































































