Download as PDF, PPTX

















![Adapter
Implement SchemaFactory interface
Connect to a data source using
parameters
Extract schema - return a list of tables
Push down processing to the data
source:
● A set of planner rules
● Calling convention (optional)
● Query model & query generator
(optional)
{
"schemas": [
{
"name": "HR",
"type": "custom",
"factory":
"org.apache.calcite.adapter.file.FileSchemaFactory",
"operand": {
"directory": "hr-csv"
}
}
]
]
$ ls -l hr-csv
-rw-r--r-- 1 jhyde staff 62 Mar 29 12:57 DEPTS.csv
-rw-r--r-- 1 jhyde staff 262 Mar 29 12:57 EMPS.csv.gz
$ ./sqlline -u jdbc:calcite:model=hr.json -n scott -p
tiger
sqlline> select count(*) as c from emp;
'C'
'5'
1 row selected (0.135 seconds)](https://image.slidesharecdn.com/boss21-calcite-slides-210816081009/85/Apache-Calcite-a-tutorial-given-at-BOSS-21-20-320.jpg)
![Adapter
Implement SchemaFactory interface
Connect to a data source using
parameters
Extract schema - return a list of tables
Push down processing to the data
source:
● A set of planner rules
● Calling convention (optional)
● Query model & query generator
(optional)
{
"schemas": [
{
"name": "BOOKSTORE",
"type": "custom",
"factory":
"org.apache.calcite.adapter.file.FileSchemaFactory",
"operand": {
"directory": "bookstore"
}
}
]
]](https://image.slidesharecdn.com/boss21-calcite-slides-210816081009/85/Apache-Calcite-a-tutorial-given-at-BOSS-21-21-320.jpg)



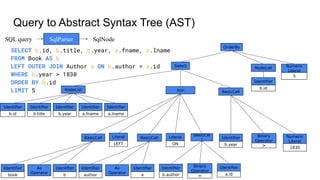
![AST to logical plan
SqlNode
Join
Select
b.id, b.title, b.year, a.fname, a.lname
BasicCall
b.author = a.id
BasicCall
book AS b
BasicCall
author AS a
Literal
LEFT
Literal
ON
LogicalJoin
[$3==$4,type=left]
LogicalTableScan
[Book]
LogicalTableScan
[Author]
LogicalFilter
[$2>1830]
LogicalProject
[ID=$0,TITLE=$1,YEAR=$2,
FNAME=$5,LNAME=$6]
LogicalSort
[sort0=$0,dir=ASC,fetch=5]
SqlValidator SqlToRelConverter
SqlNode RelNode
OrderBy
b.id FETCH 5
BasicCall
b.year > 1830](https://image.slidesharecdn.com/boss21-calcite-slides-210816081009/85/Apache-Calcite-a-tutorial-given-at-BOSS-21-26-320.jpg)
![Logical to physical plan
RelRule
EnumerableSortRule
EnumerableProjectRule
EnumerableFilterRule
EnumerableJoinRule
EnumerableTableScanRule
RelOptPlanner RelNode
RelNode
LogicalJoin
[$3==$4,type=left]
LogicalTableScan
[Book]
LogicalTableScan
[Author]
LogicalFilter
[$2>1830]
LogicalProject
[ID=$0,TITLE=$1,YEAR=$2,
FNAME=$5,LNAME=$6]
LogicalSort
[sort0=$0,dir=ASC,fetch=5]
EnumerableJoin
[$3==$4,type=left]
EnumerableTableScan
[Book]
EnumerableTableScan
[Author]
EnumerableFilter
[$2>1830]
EnumerableProject
[ID=$0,TITLE=$1,YEAR=$2,
FNAME=$5,LNAME=$6]
EnumerableSort
[sort0=$0,dir=ASC,fetch=5]](https://image.slidesharecdn.com/boss21-calcite-slides-210816081009/85/Apache-Calcite-a-tutorial-given-at-BOSS-21-27-320.jpg)
![Physical to Executable plan
EnumerableInterpretable Java code
RelNode
EnumerableJoin
[$3==$4,type=left]
EnumerableTableScan
[Book]
EnumerableTableScan
[Author]
EnumerableFilter
[$2>1830]
EnumerableProject
[ID=$0,TITLE=$1,YEAR=$2,
FNAME=$5,LNAME=$6]
EnumerableSort
[sort0=$0,dir=ASC,fetch=5]](https://image.slidesharecdn.com/boss21-calcite-slides-210816081009/85/Apache-Calcite-a-tutorial-given-at-BOSS-21-28-320.jpg)




![Exercise II: Improve performance by applying more
optimization rules
LogicalJoin
[$0=$9,type=inner]
LogicalTableScan
[CUSTOMER]
LogicalTableScan
[ORDERS]
LogicalFilter
[$0<3]
LogicalProject
[C_NAME=$1,O_ORDERKEY=$8,
O_ORDERDATE=$12]
LogicalSort
[sort0=$0,dir0=ASC,sort1=$1,dir1=ASC]
RelRule
FilterIntoJoinRule
LogicalJoin
[$0=$9,type=inner]
LogicalTableScan
[CUSTOMER]
LogicalTableScan
[ORDERS]
LogicalFilter
[$0<3]
LogicalProject
[C_NAME=$1,O_ORDERKEY=$8,
O_ORDERDATE=$12]
LogicalSort
[sort0=$0,dir0=ASC,sort1=$1,dir1=ASC]](https://image.slidesharecdn.com/boss21-calcite-slides-210816081009/85/Apache-Calcite-a-tutorial-given-at-BOSS-21-34-320.jpg)









![What we want to achieve?
EnumerableJoin
[$0=$9,type=inner]
EnumerableTableScan
[CUSTOMER]
EnumerableCalc
[$0<3]
EnumerableCalc
[C_NAME=$1,O_ORDERKEY=$8,
O_ORDERDATE=$12]
EnumerableSort
[sort0=$0,dir0=ASC,sort1=$1,dir1=ASC]
EnumerableTableScan
[ORDERS]
EnumerableJoin
[$0=$9,type=inner]
LuceneTableScan
[CUSTOMER]
LuceneFilter
[$0<3]
EnumerableCalc
[C_NAME=$1,O_ORDERKEY=$8,
O_ORDERDATE=$12]
EnumerableSort
[sort0=$0,dir0=ASC,sort1=$1,dir1=ASC]
LuceneTableScan
[ORDERS]
LuceneToEnumerableConverter
LuceneToEnumerableConverter](https://image.slidesharecdn.com/boss21-calcite-slides-210816081009/85/Apache-Calcite-a-tutorial-given-at-BOSS-21-47-320.jpg)
![What do we need?
EnumerableJoin
[$0=$9,type=inner]
LuceneTableScan
[CUSTOMER]
LuceneFilter
[$0<3]
EnumerableCalc
[C_NAME=$1,O_ORDERKEY=$8,
O_ORDERDATE=$12]
EnumerableSort
[sort0=$0,dir0=ASC,sort1=$1,dir1=ASC]
LuceneTableScan
[ORDERS]
LuceneToEnumerableConverter
LuceneToEnumerableConverter
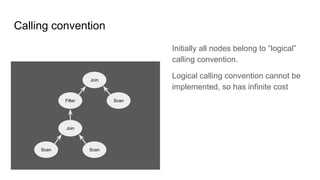
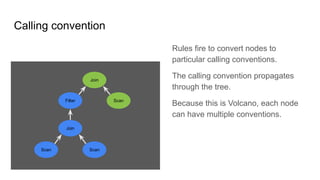
Two calling conventions:
1. Enumerable
2. Lucene
Three custom operators:
1. LuceneTableScan
2. LuceneToEnumerableConverter
3. LuceneFilter
Three custom conversion rules:
1. LogicalTableScan →
LuceneTableScan
2. LogicalFilter → LuceneFilter
3. LuceneANY →
LuceneToEnumerableConverter](https://image.slidesharecdn.com/boss21-calcite-slides-210816081009/85/Apache-Calcite-a-tutorial-given-at-BOSS-21-48-320.jpg)
![What do we need?
EnumerableJoin
[$0=$9,type=inner]
LuceneTableScan
[CUSTOMER]
LuceneFilter
[$0<3]
EnumerableCalc
[C_NAME=$1,O_ORDERKEY=$8,
O_ORDERDATE=$12]
EnumerableSort
[sort0=$0,dir0=ASC,sort1=$1,dir1=ASC]
LuceneTableScan
[ORDERS]
LuceneToEnumerableConverter
LuceneToEnumerableConverter
Two calling conventions:
1. Enumerable
2. Lucene
Three custom operators:
1. LuceneTableScan
2. LuceneToEnumerableConverter
3. LuceneFilter
Three custom conversion rules:
1. LogicalTableScan →
LuceneTableScan
2. LogicalFilter → LuceneFilter
3. LuceneANY →
LuceneToEnumerableConverter
STEP 1
STEP 2
STEP 3
STEP 4
STEP 5
STEP 6](https://image.slidesharecdn.com/boss21-calcite-slides-210816081009/85/Apache-Calcite-a-tutorial-given-at-BOSS-21-49-320.jpg)





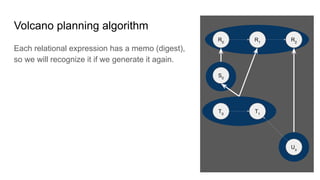
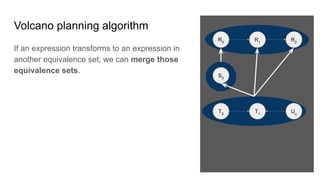





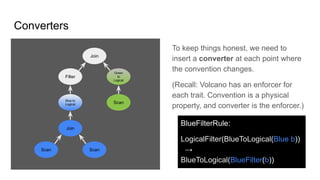
![Parsing & validating SQL -
what knobs can I turn?
SELECT deptno AS d,
SUM(sal) AS [sumSal]
FROM [HR].[Emp]
WHERE ename NOT ILIKE "A%"
GROUP BY d
ORDER BY 1, 2 DESC SqlConformance.isGroupByAlias() = true
SqlConformance.isSortByOrdinal() = true
Lex.quoting = Quoting.BRACKET
Lex.charLiteralStyle =
CharLiteralStyle.BQ_DOUBLE
SqlValidator.Config.defaultNullCollation =
HIGH
Lex.unquotedCasing = Casing.TO_UPPER
Lex.quotedCasing = Casing.UNCHANGED
PARSER_FACTORY =
"org.apache.calcite.sql.parser.impl.SqlParserImpl.FACTORY"
FUN = "postgres" (ILIKE is not standard SQL)](https://image.slidesharecdn.com/boss21-calcite-slides-210816081009/85/Apache-Calcite-a-tutorial-given-at-BOSS-21-65-320.jpg)





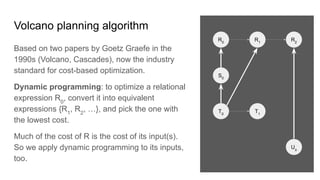
![Materialized views in Calcite
{
"schemas": {
"name": "HR",
"tables": [ {
"name": "emp"
} ],
"materializations": [ {
"table": "i_emp_job",
"sql": "SELECT job, empno
FROM emp
ORDER BY job, empno"
}, {
"table": "add_emp_deptno",
"sql": "SELECT deptno,
SUM(sal) AS ss, COUNT(*) AS c
FROM emp
GROUP BY deptno"
} ]
}
}
/** Transforms a relational expression into a
* semantically equivalent relational expression,
* according to a given set of rules and a cost
* model. */
public interface RelOptPlanner {
/** Defines an equivalence between a table and
* a query. */
void addMaterialization(
RelOptMaterialization materialization);
/** Finds the most efficient expression to
* implement this query. */
RelNode findBestExp();
}
/** Records that a particular query is materialized
* by a particular table. */
public class RelOptMaterialization {
public final RelNode tableRel;
public final List<String> qualifiedTableName;
public final RelNode queryRel;
}
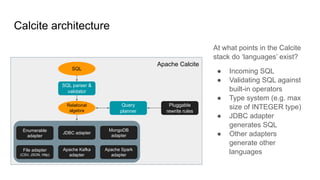
You can define materializations in a JSON model, via the planner API, or via
CREATE MATERIALIZED VIEW DDL (not shown).](https://image.slidesharecdn.com/boss21-calcite-slides-210816081009/85/Apache-Calcite-a-tutorial-given-at-BOSS-21-73-320.jpg)
















The document provides instructions for setting up the environment and coding tutorial for the BOSS'21 Copenhagen tutorial on Apache Calcite. It includes the following steps: 1. Clone the GitHub repository containing sample code and dependencies. 2. Compile the project. 3. It outlines the draft schedule for the tutorial, which will cover topics like Calcite introduction, demonstration of SQL queries on CSV files, setting up the coding environment, using Lucene for indexing, and coding exercises to build parts of the logical and physical query plans in Calcite. 4. The tutorial will be led by Stamatis Zampetakis from Cloudera and Julian Hyde from Google, who are both committers to























































































