







![๏ Easy to use GDB-like debugger [ICSE 16] (not covered in this talk)
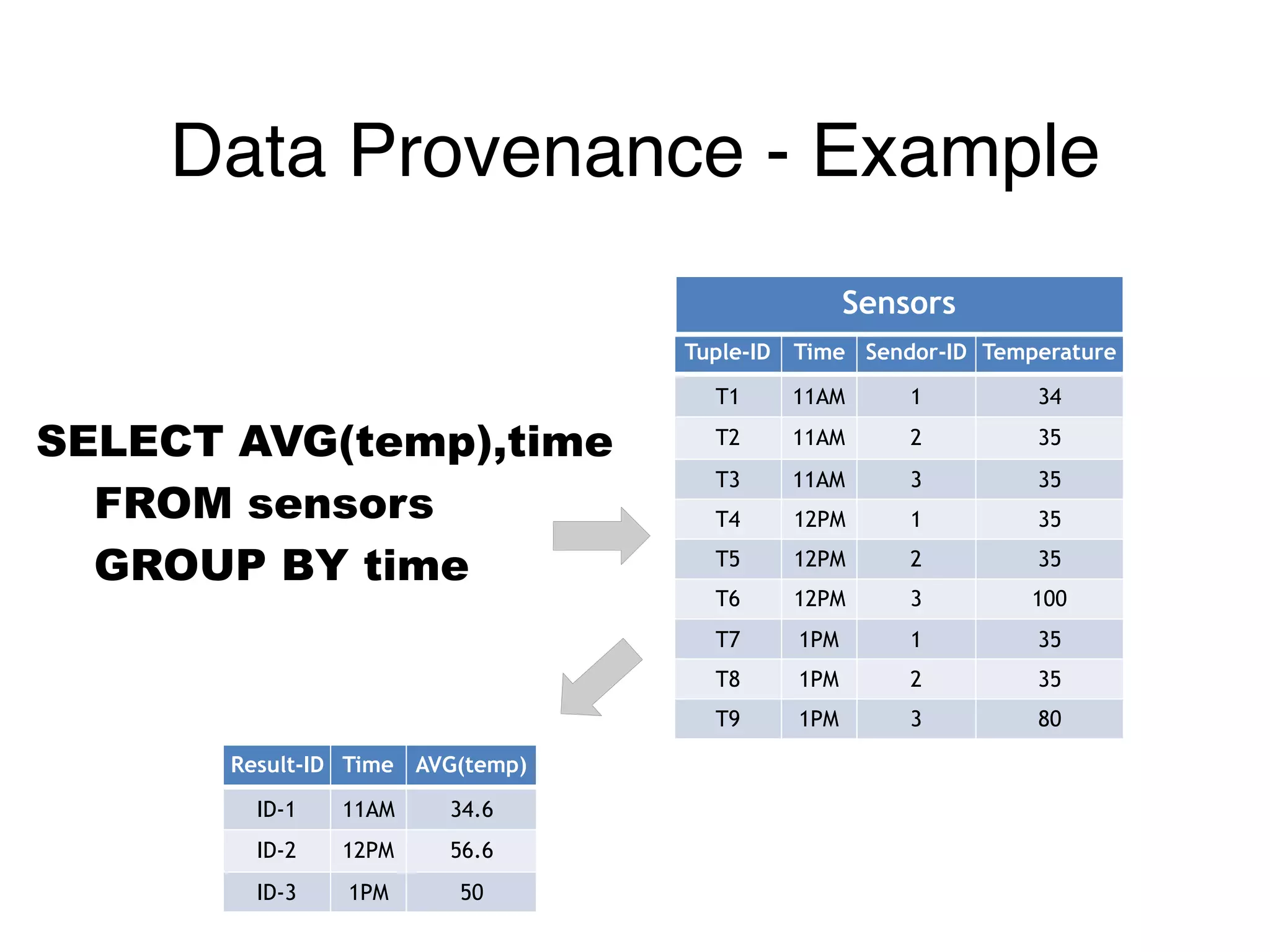
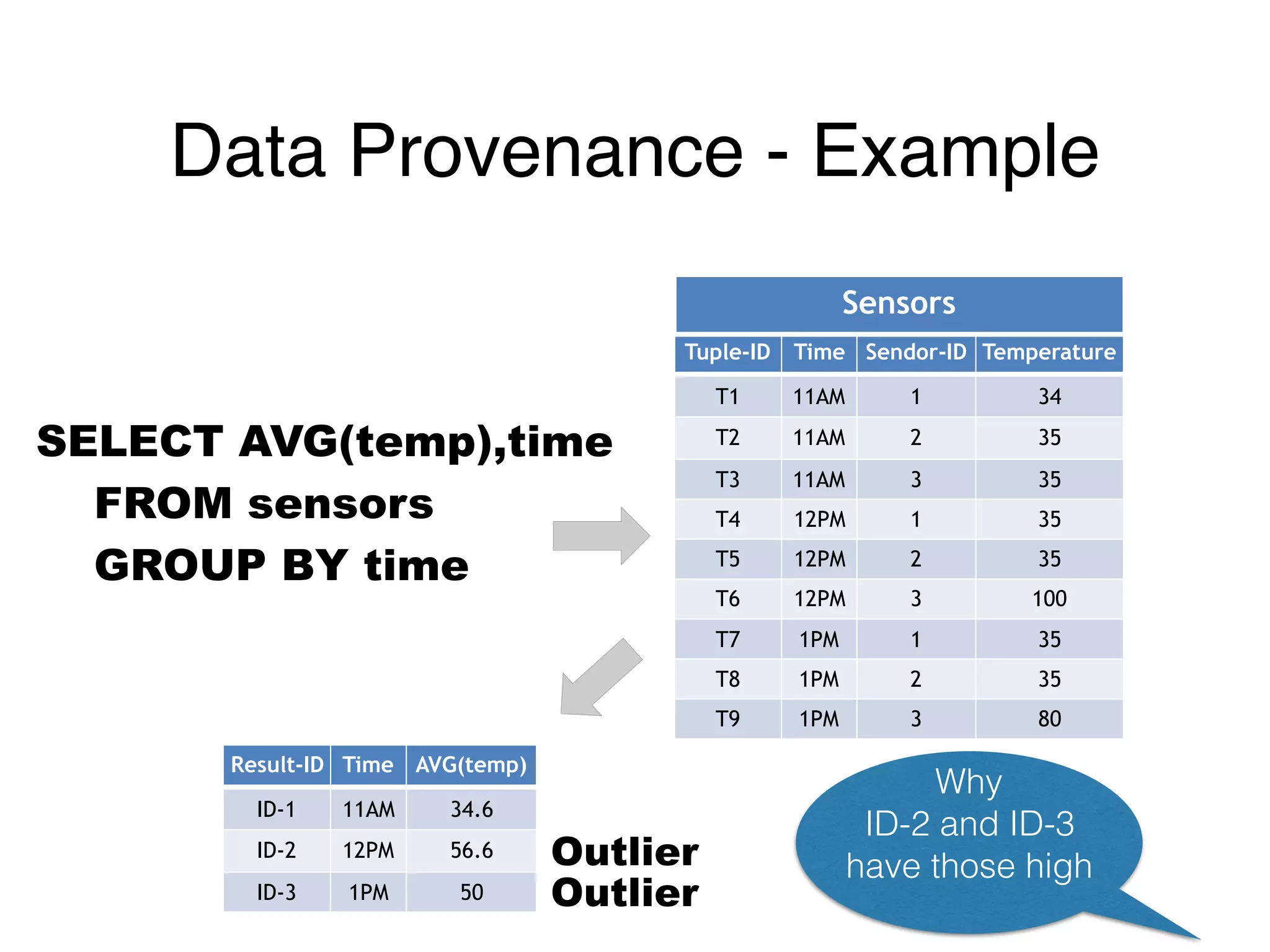
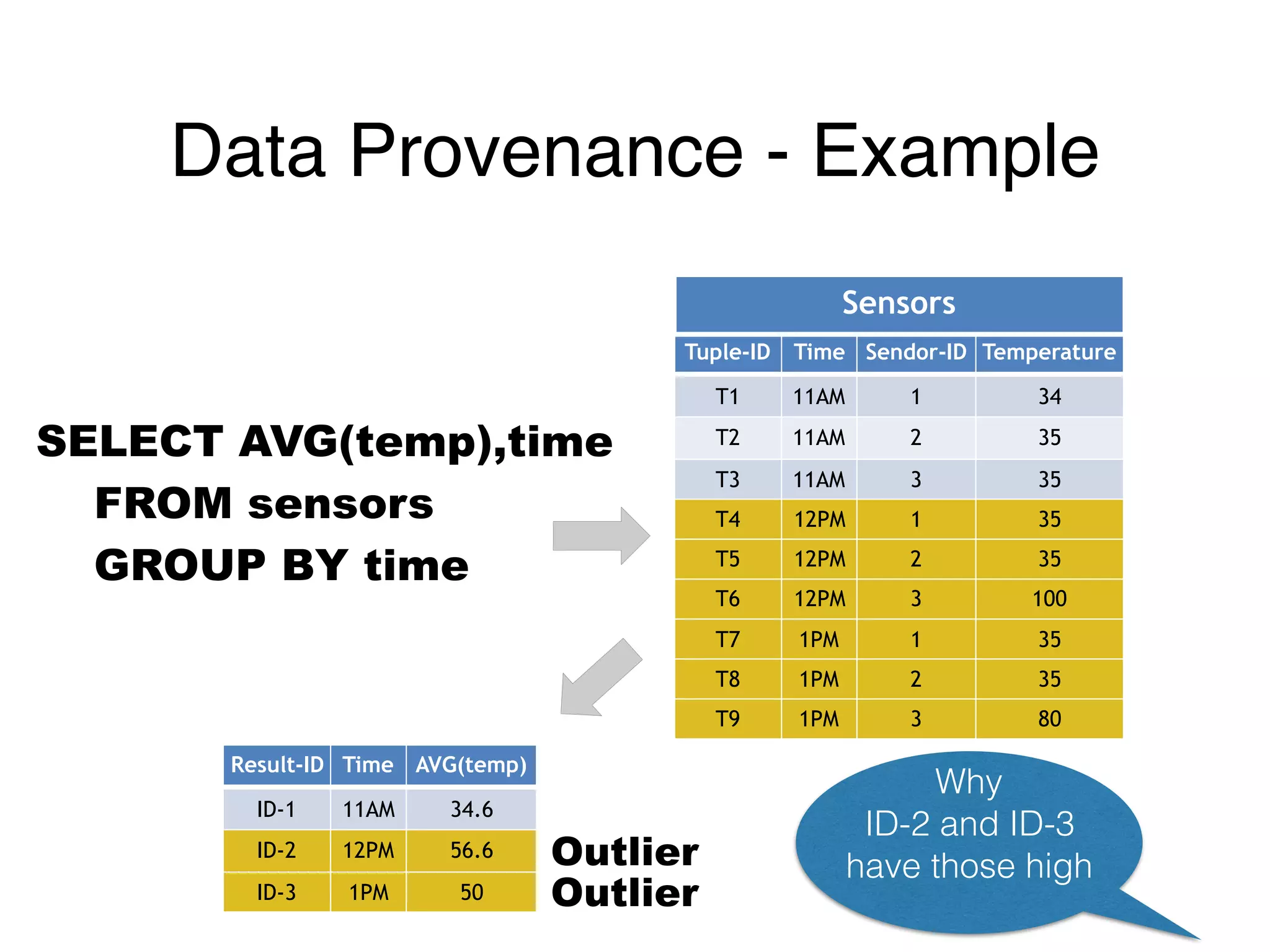
๏ Visibility of data into running workflow
• E.g., what (input) data led to this (outlier) result?
๏ Selectively replaying a portion of the data processing steps on subsets
of intermediate data leading to outliers results
๏ Interactive program analysis
Big Data Debugging - Desiderata](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-10-2048.jpg)


![๏ They use external storage systems (HDFS in
RAMP [CIDR-11], DBMS in Newt [SOCC-13]) to
retain lineage data
๏ Data provenance queries are supported in a
separate programming interface
Previous Data Provenance DISC Systems](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-16-2048.jpg)
![๏ They use external storage systems (HDFS in
RAMP [CIDR-11], DBMS in Newt [SOCC-13]) to
retain lineage data
๏ Data provenance queries are supported in a
separate programming interface
High overhead
Previous Data Provenance DISC Systems](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-17-2048.jpg)
![๏ They use external storage systems (HDFS in
RAMP [CIDR-11], DBMS in Newt [SOCC-13]) to
retain lineage data
๏ Data provenance queries are supported in a
separate programming interface
High overhead
Low interactivity
Previous Data Provenance DISC Systems](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-18-2048.jpg)










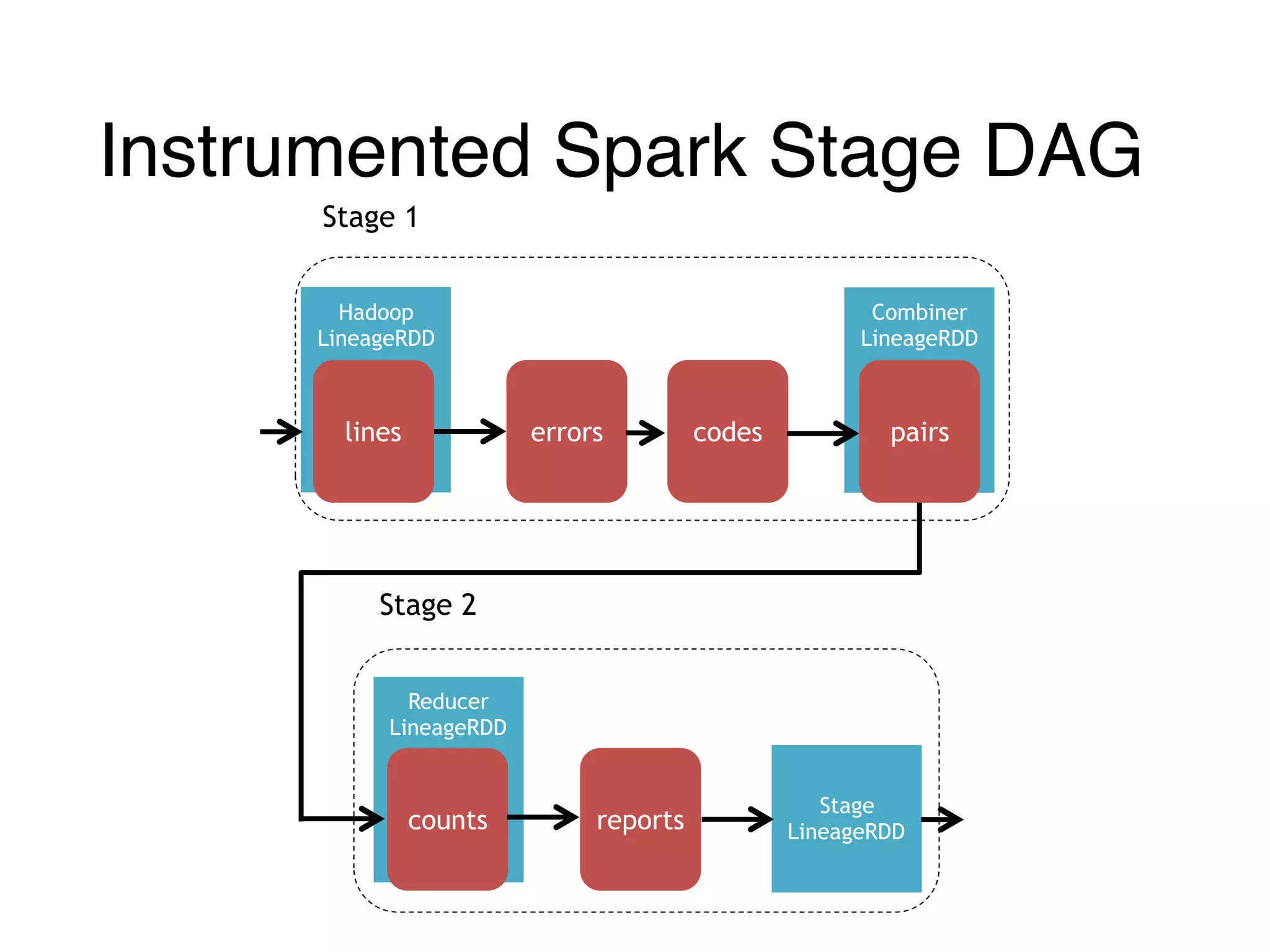
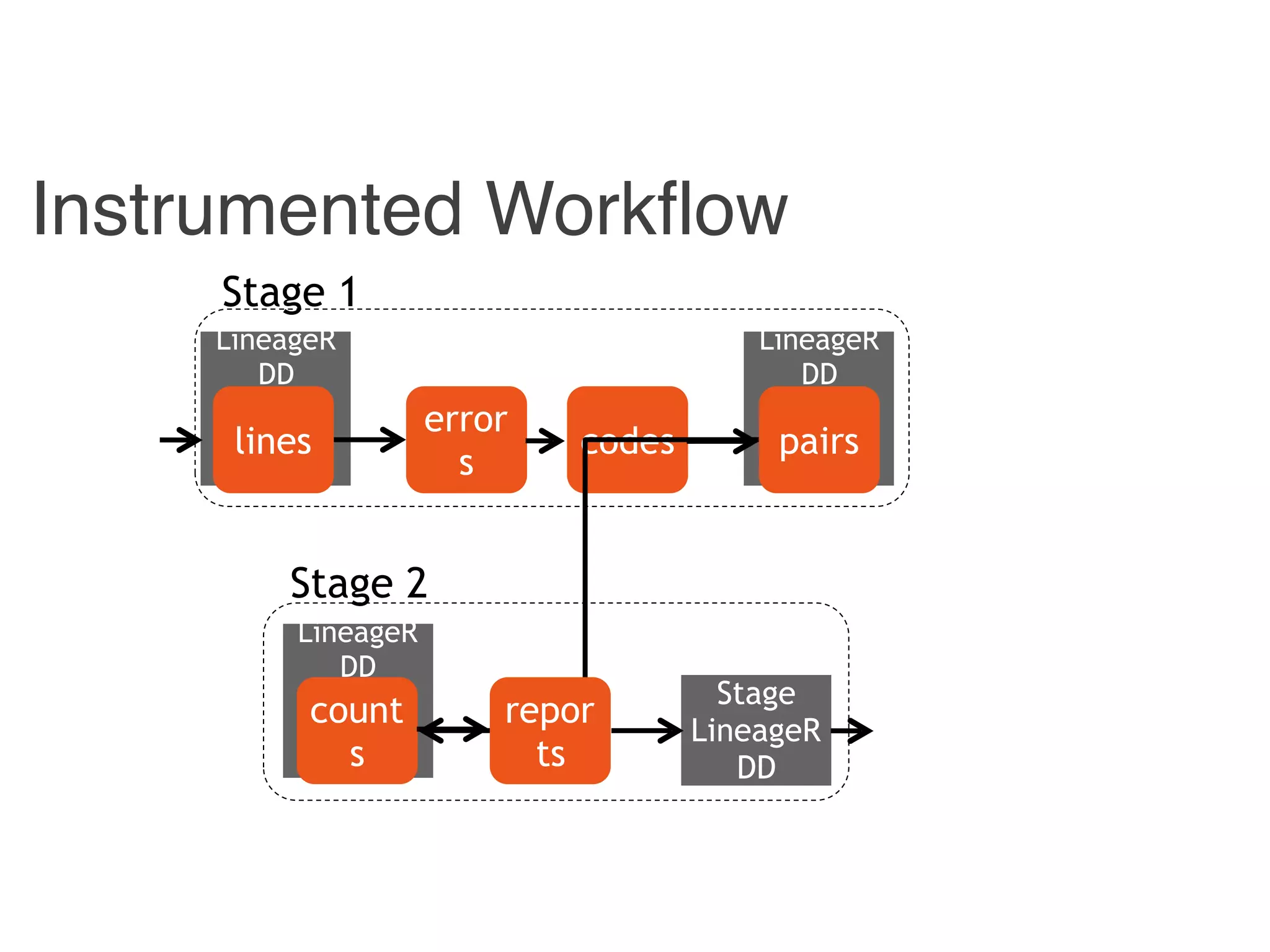
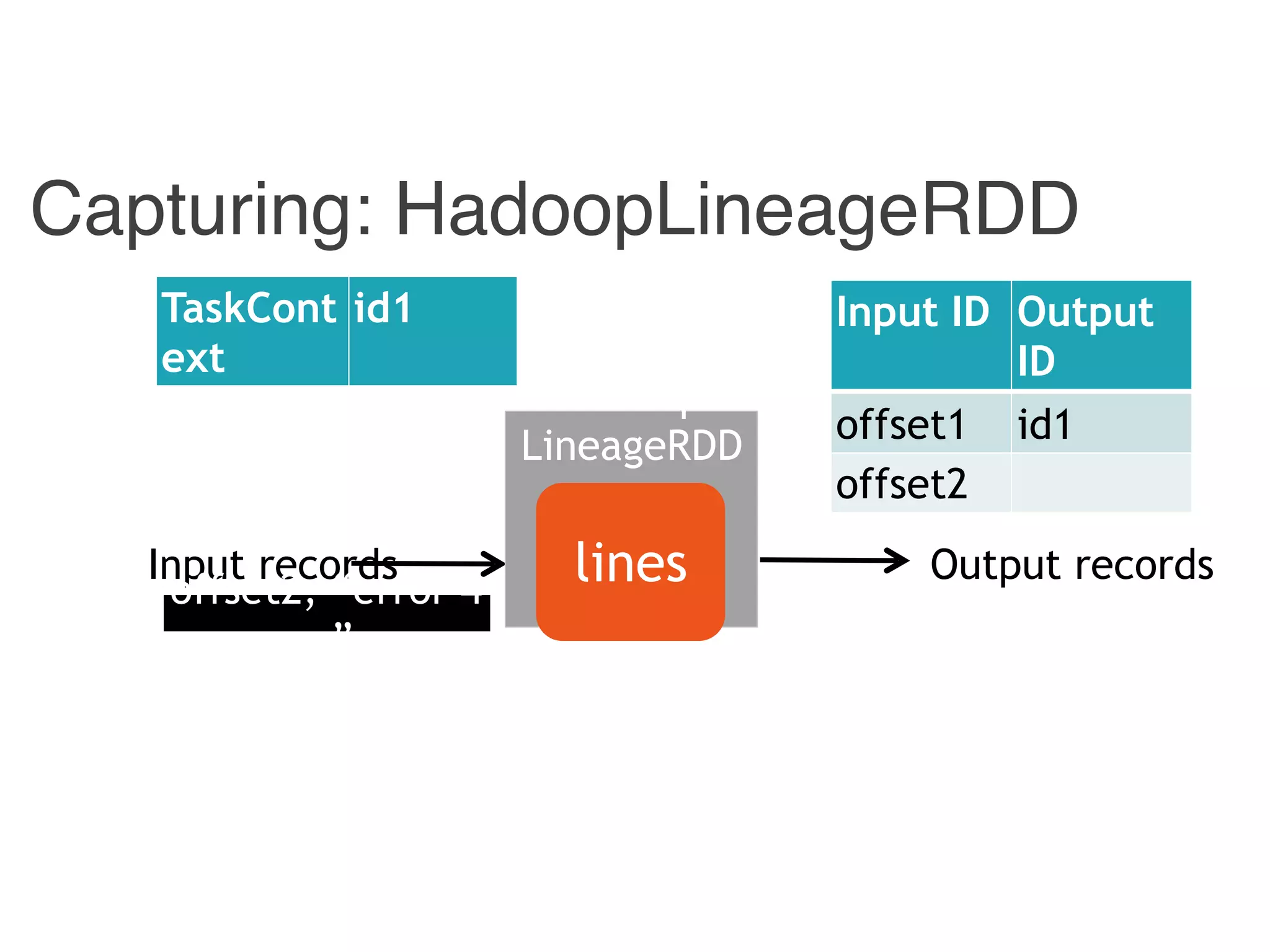
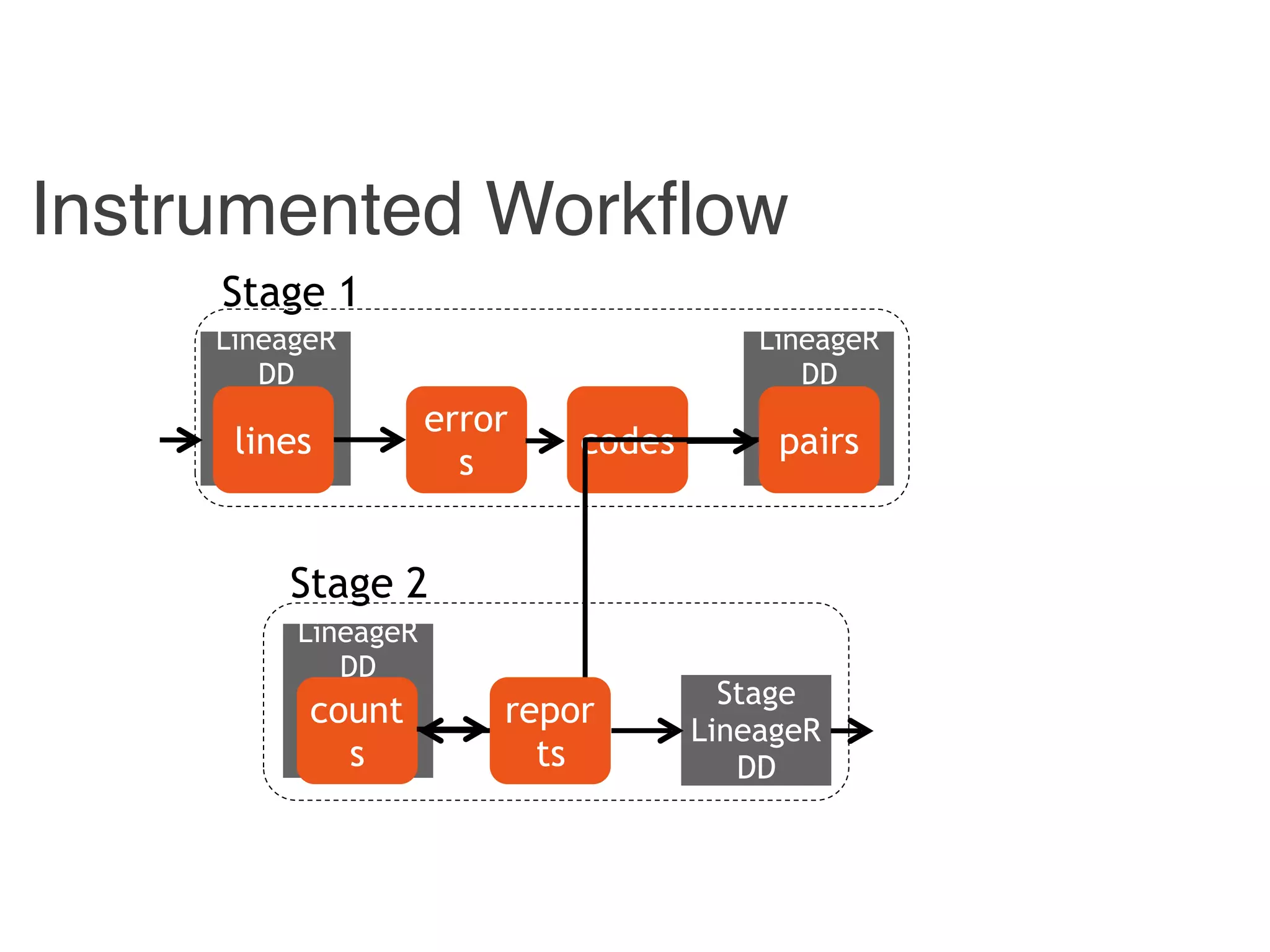
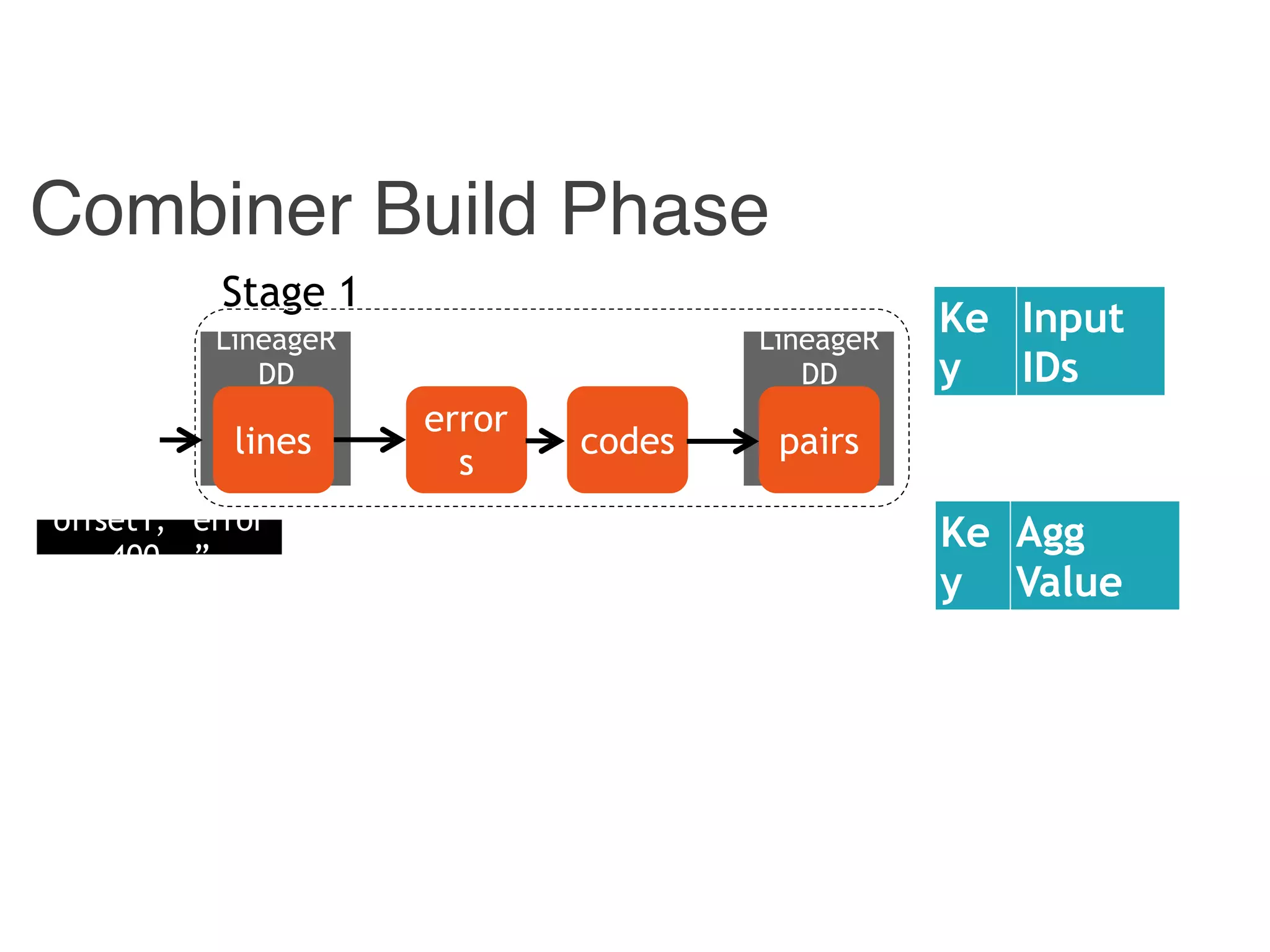
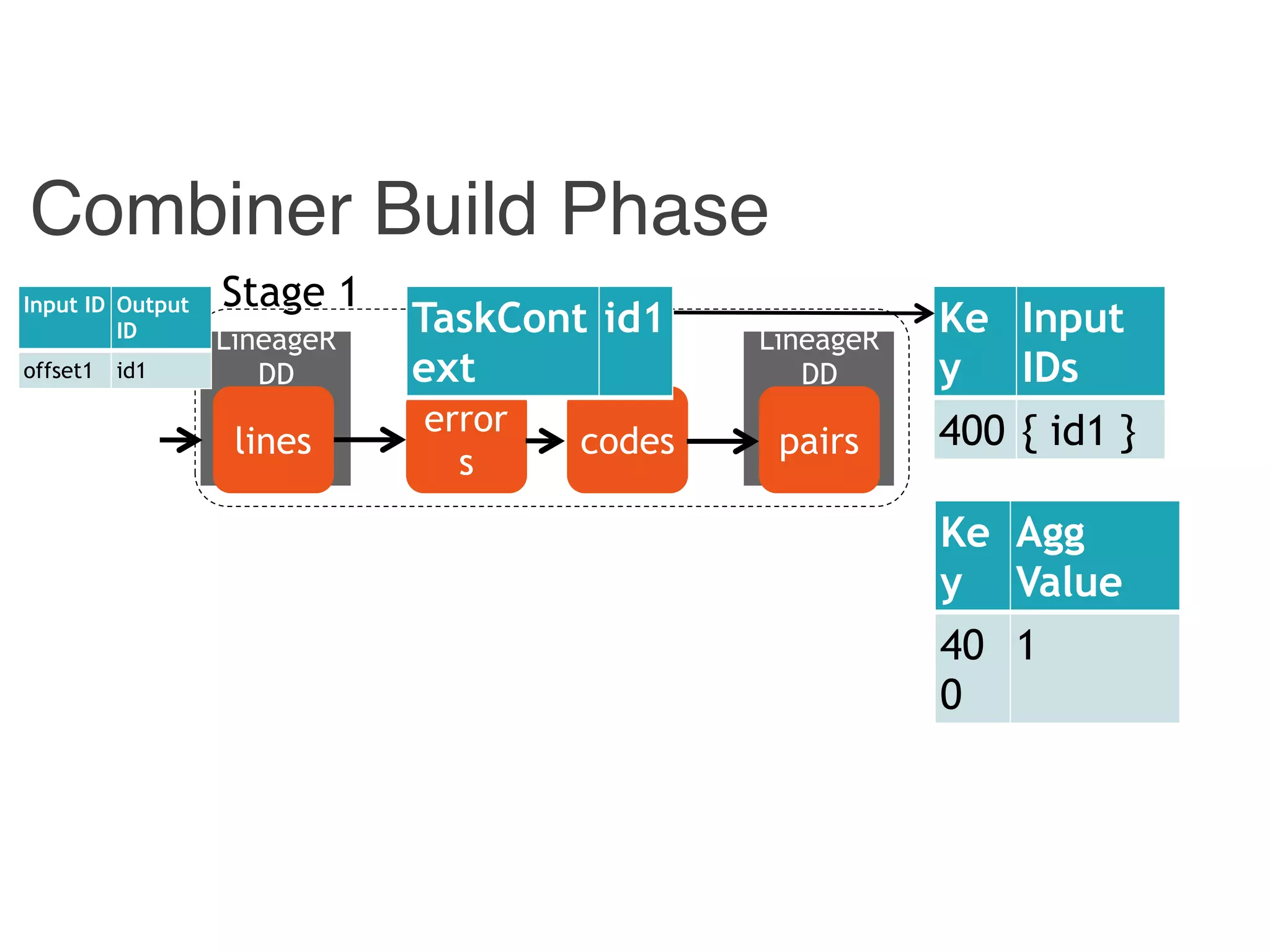
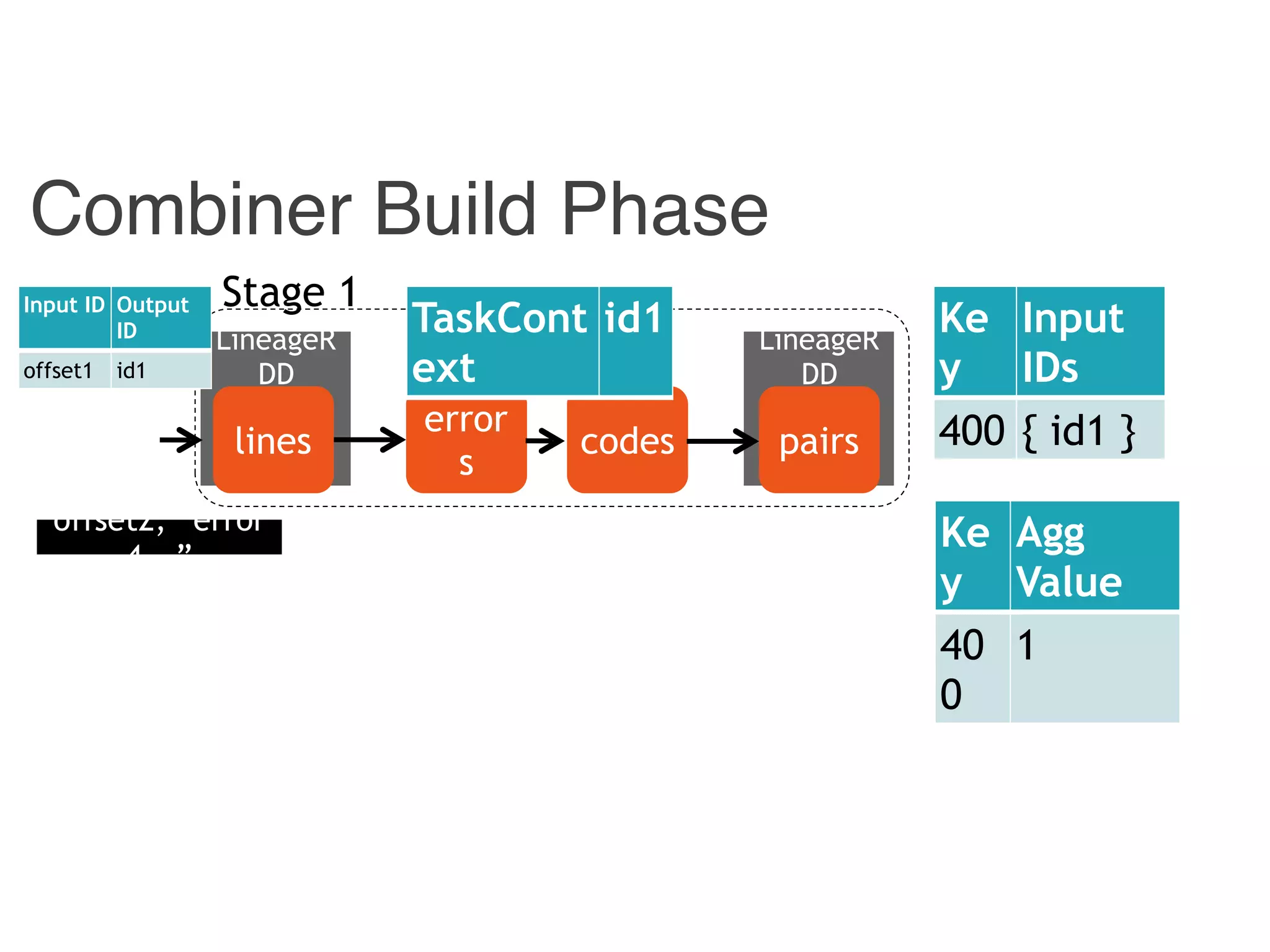
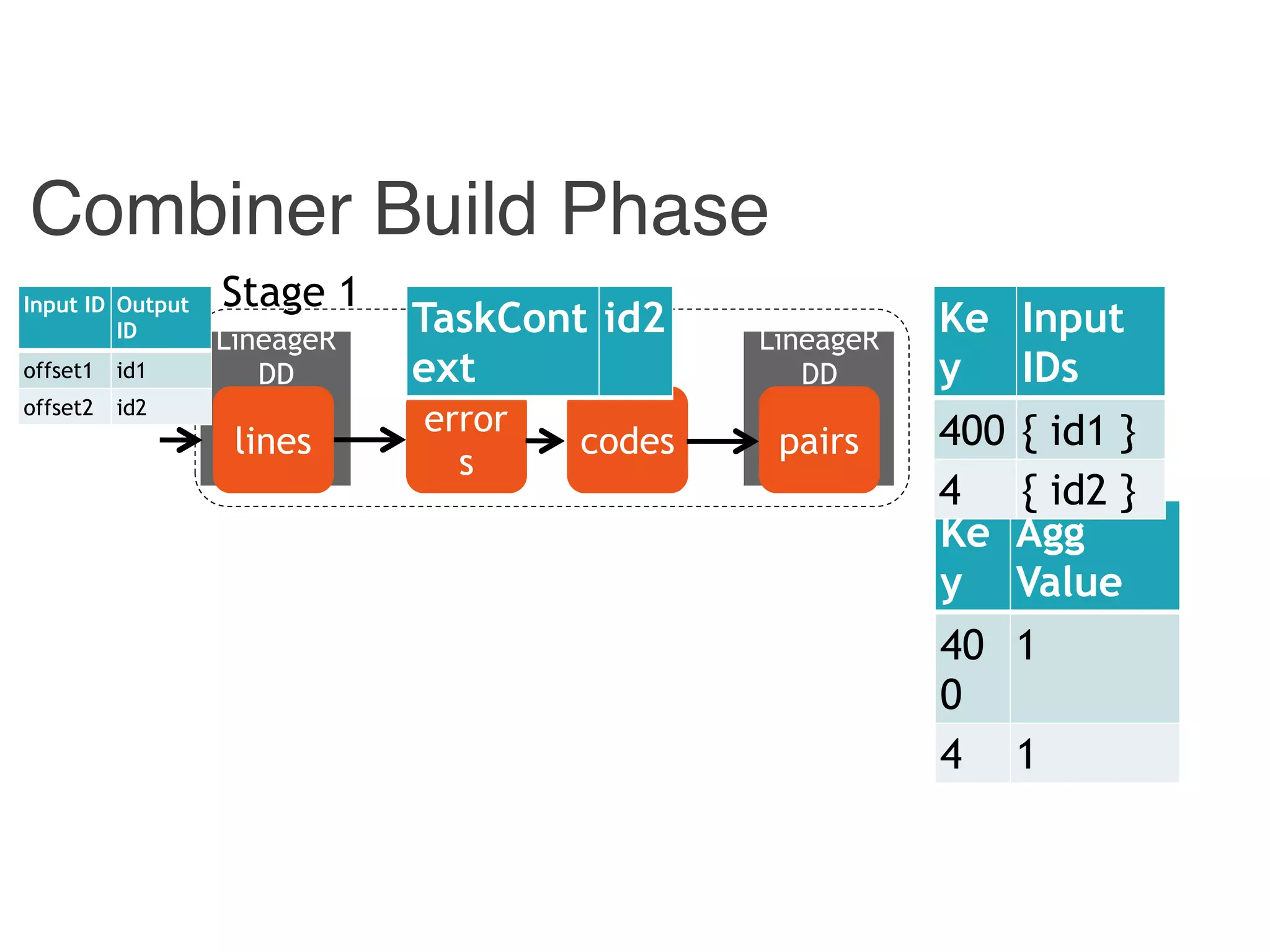
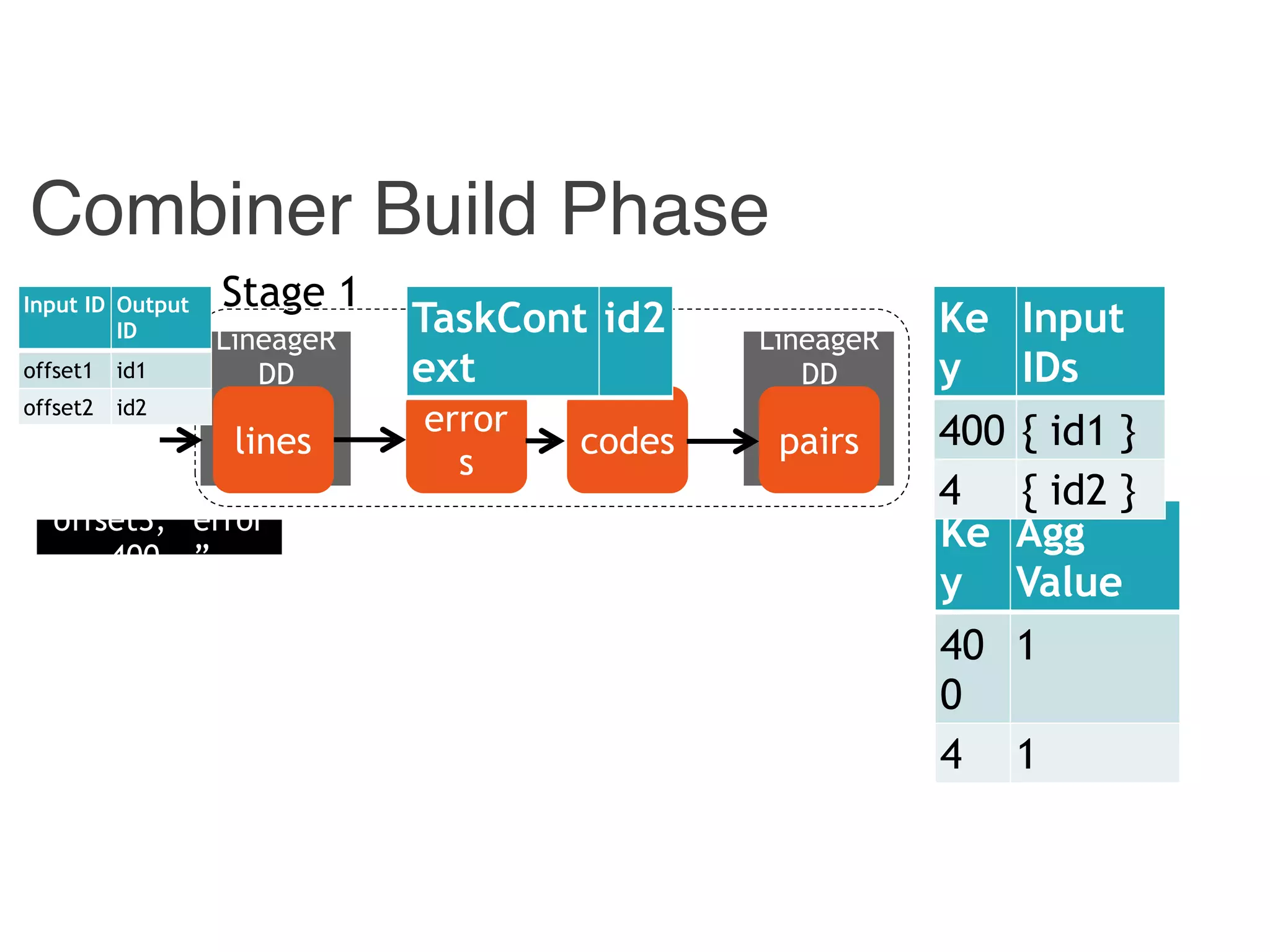
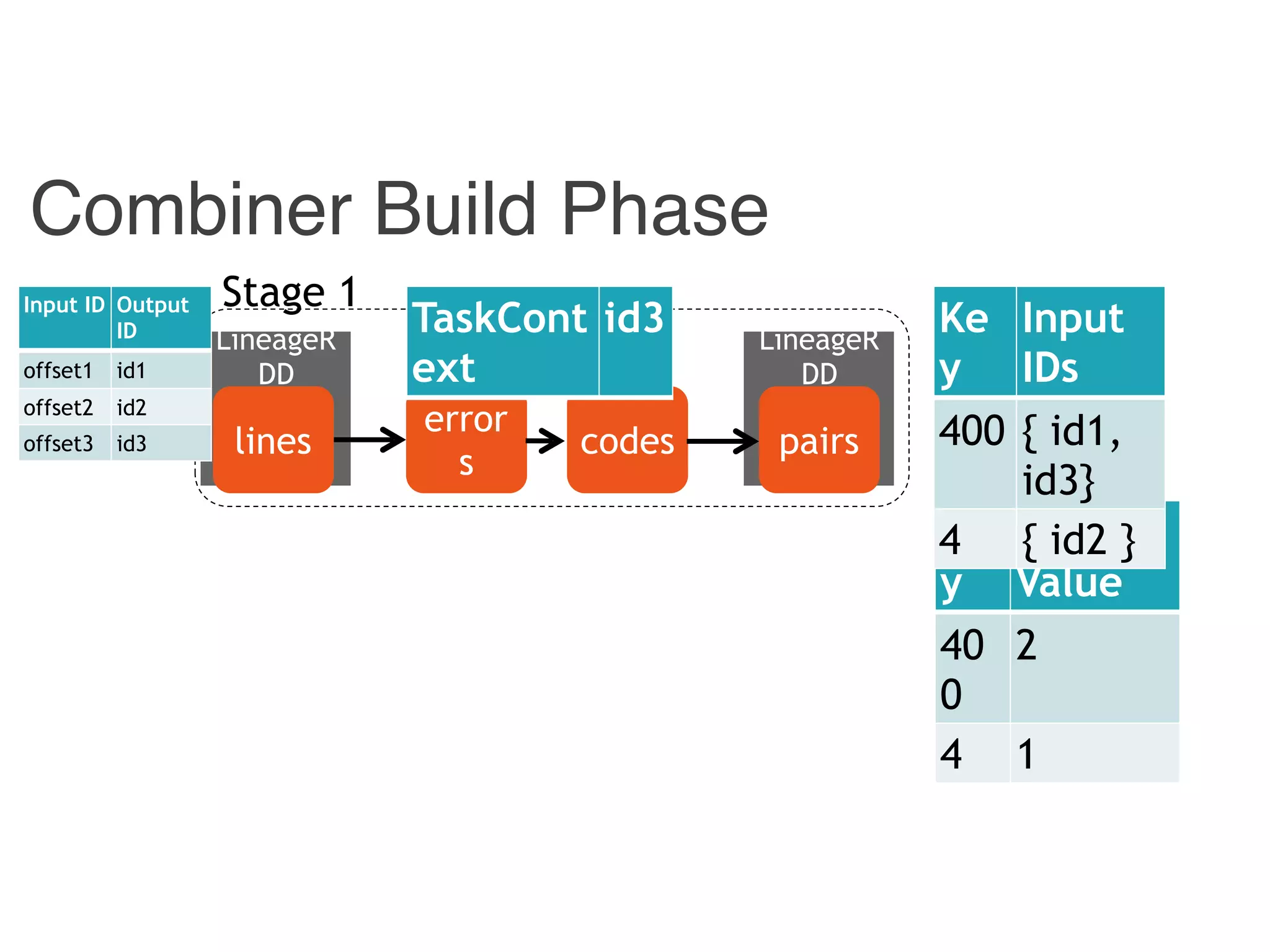
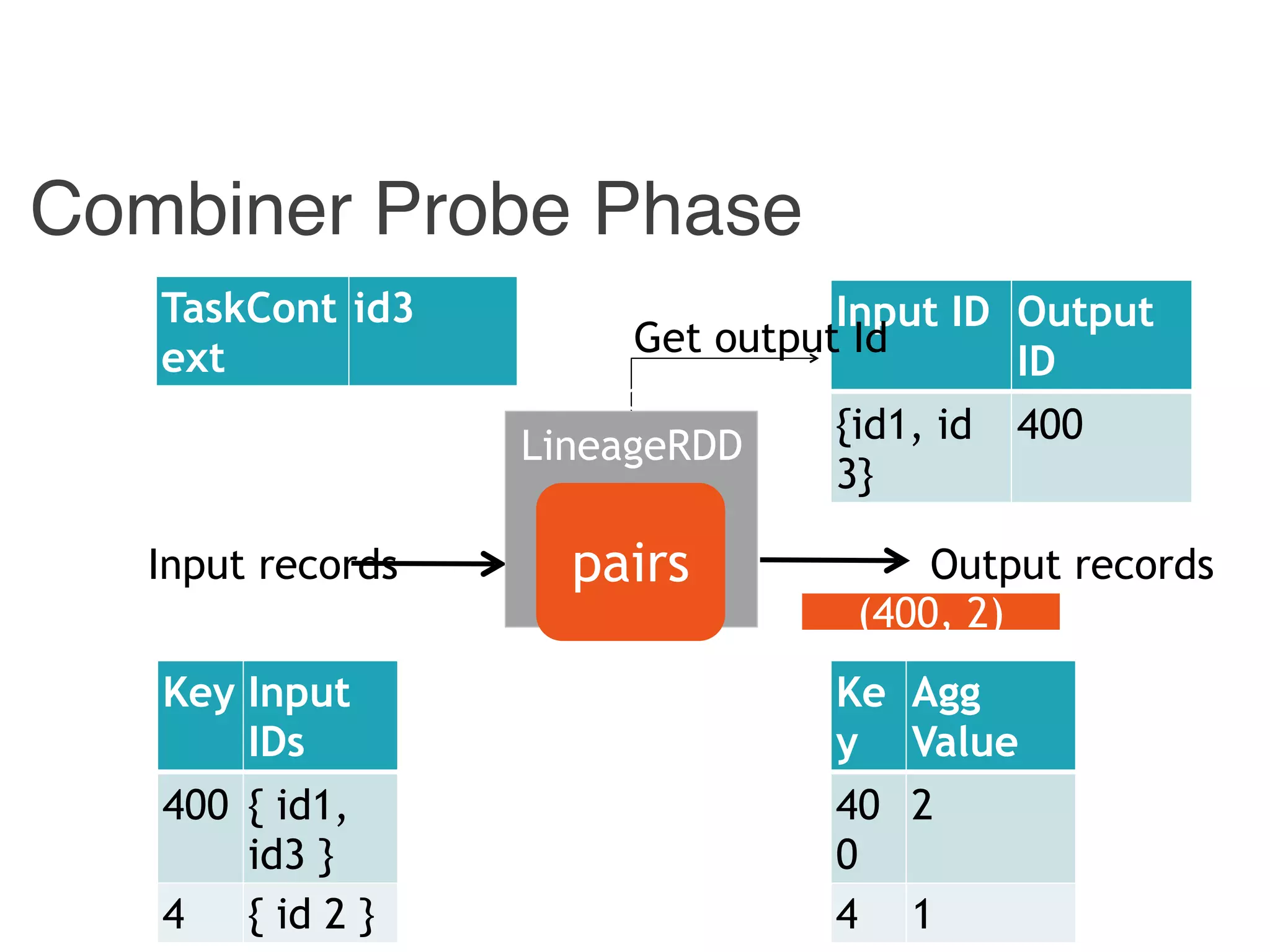
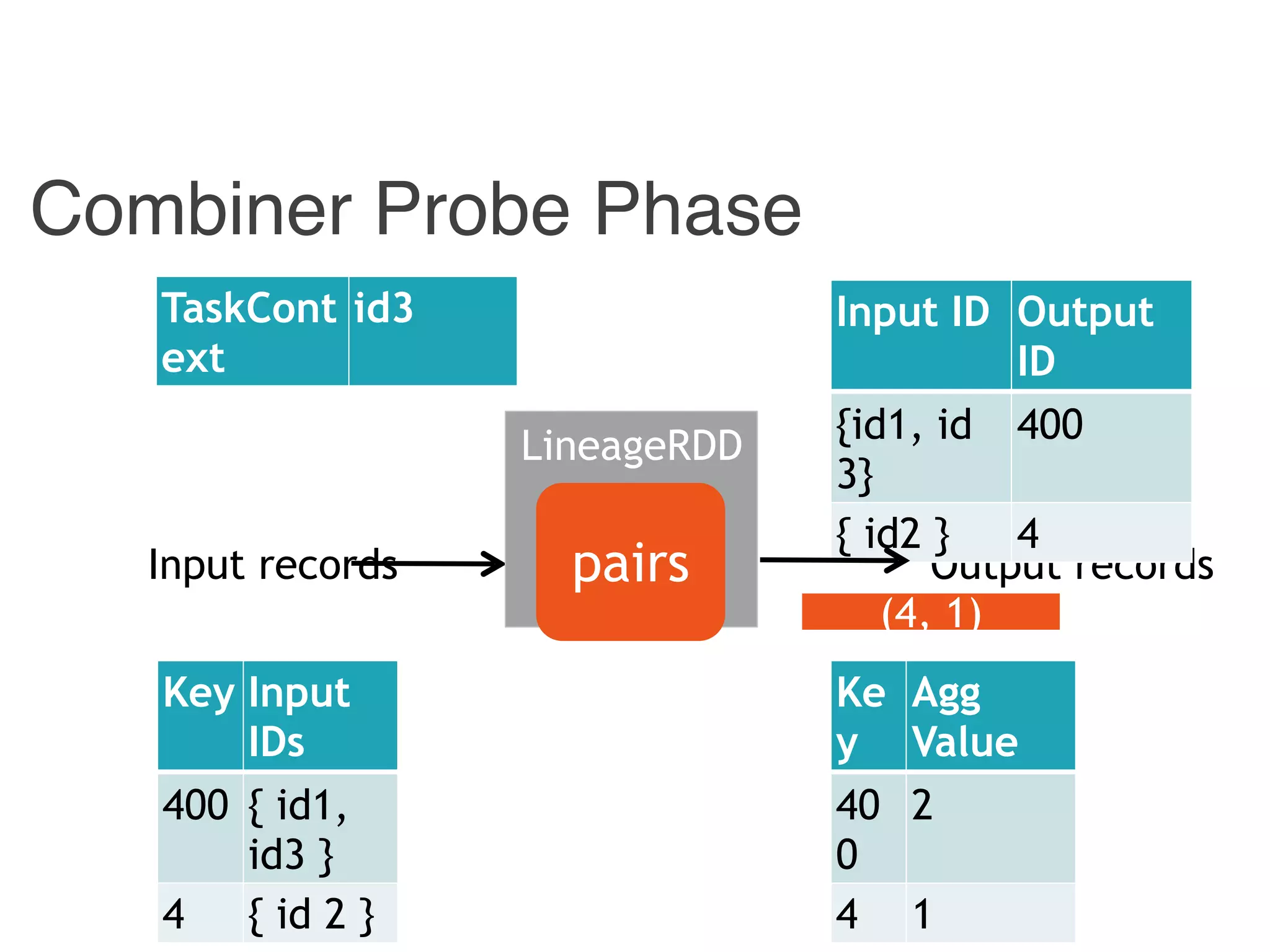
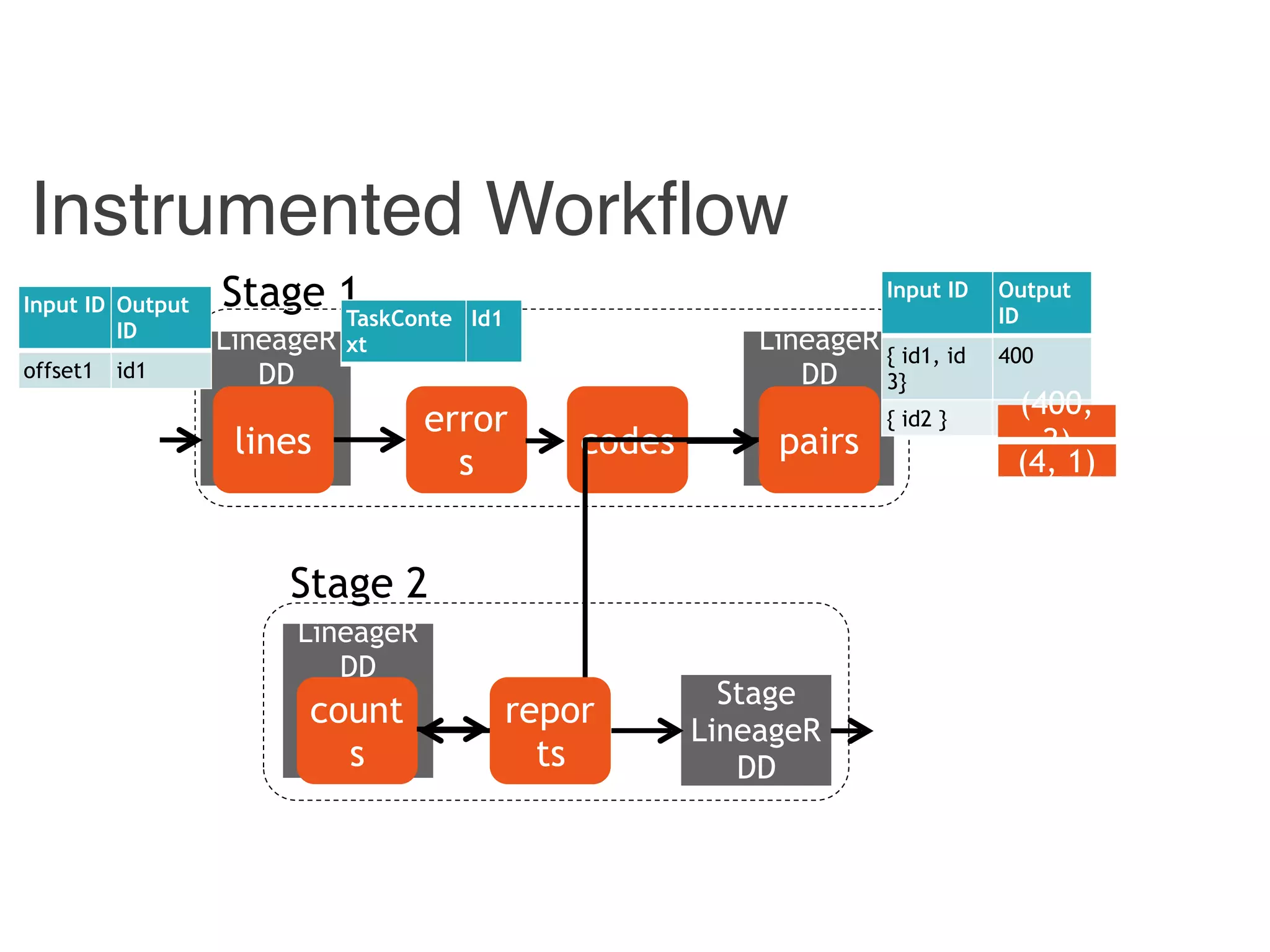
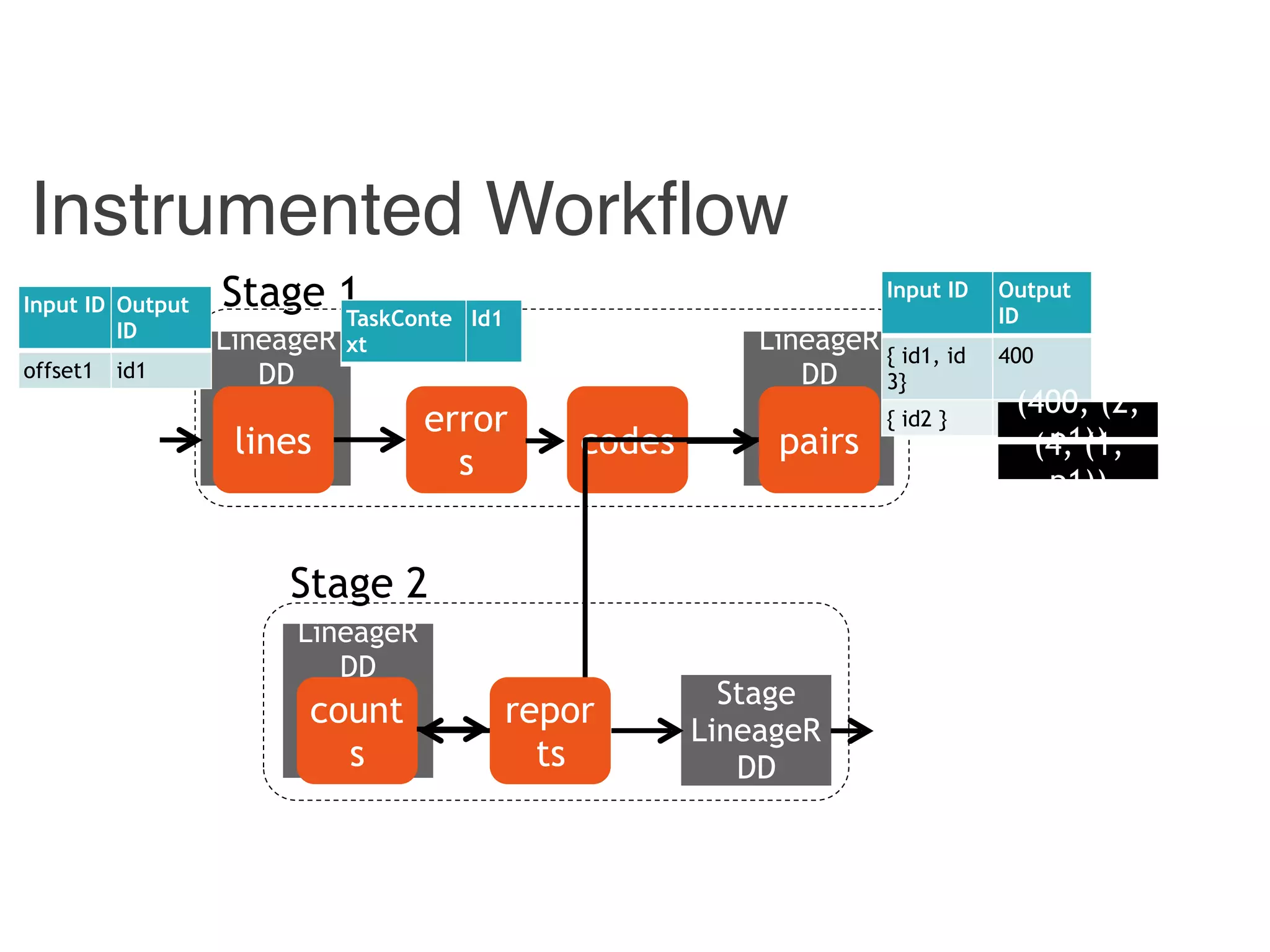
![Instrumented Workflow
Combiner
LineageRDD
Reducer
LineageRDD
Hadoop
LineageRDD
counts
pairscodeserrorslines
Stage 1
Stage 2
reports
Stage
LineageRDD
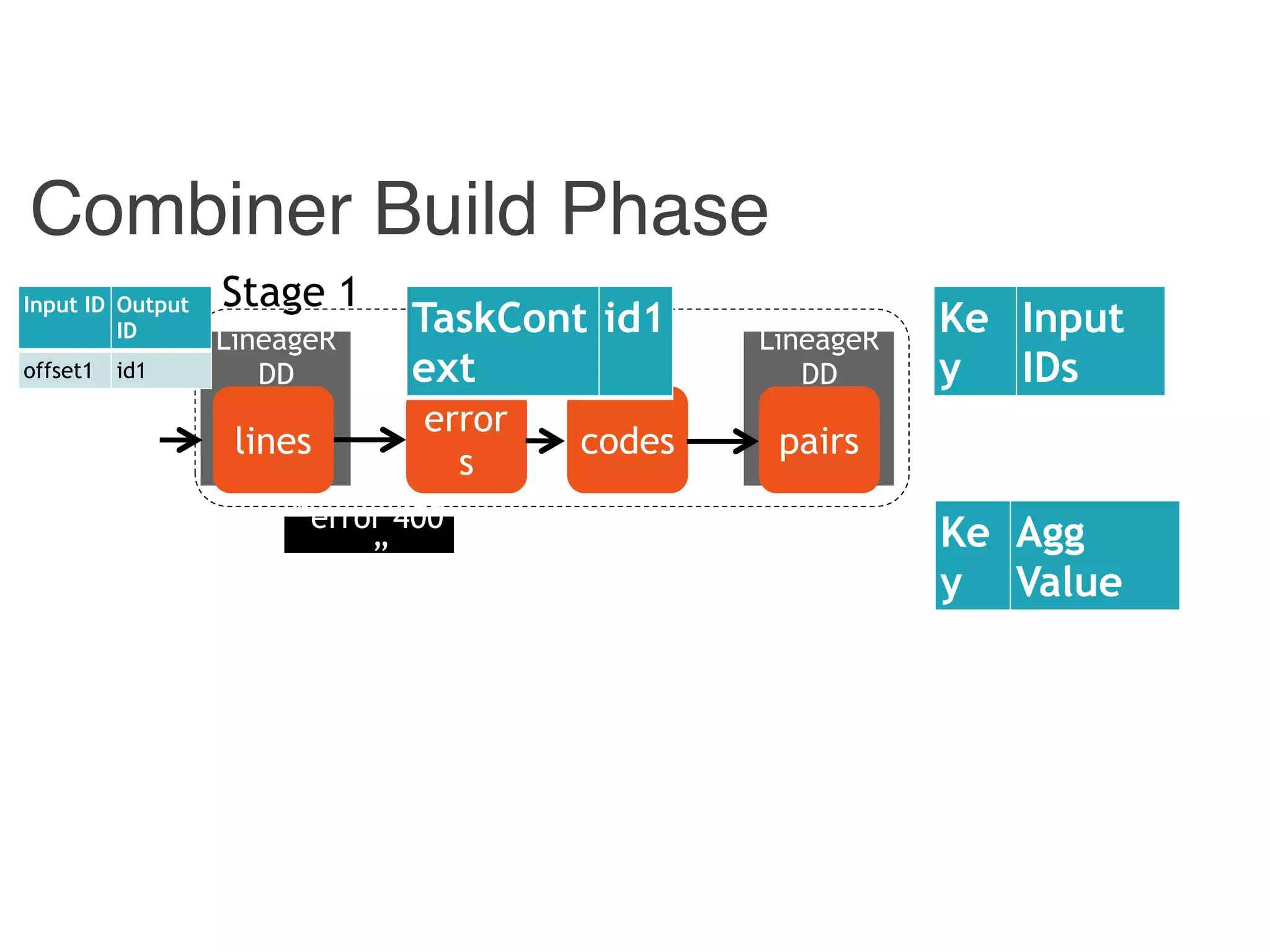
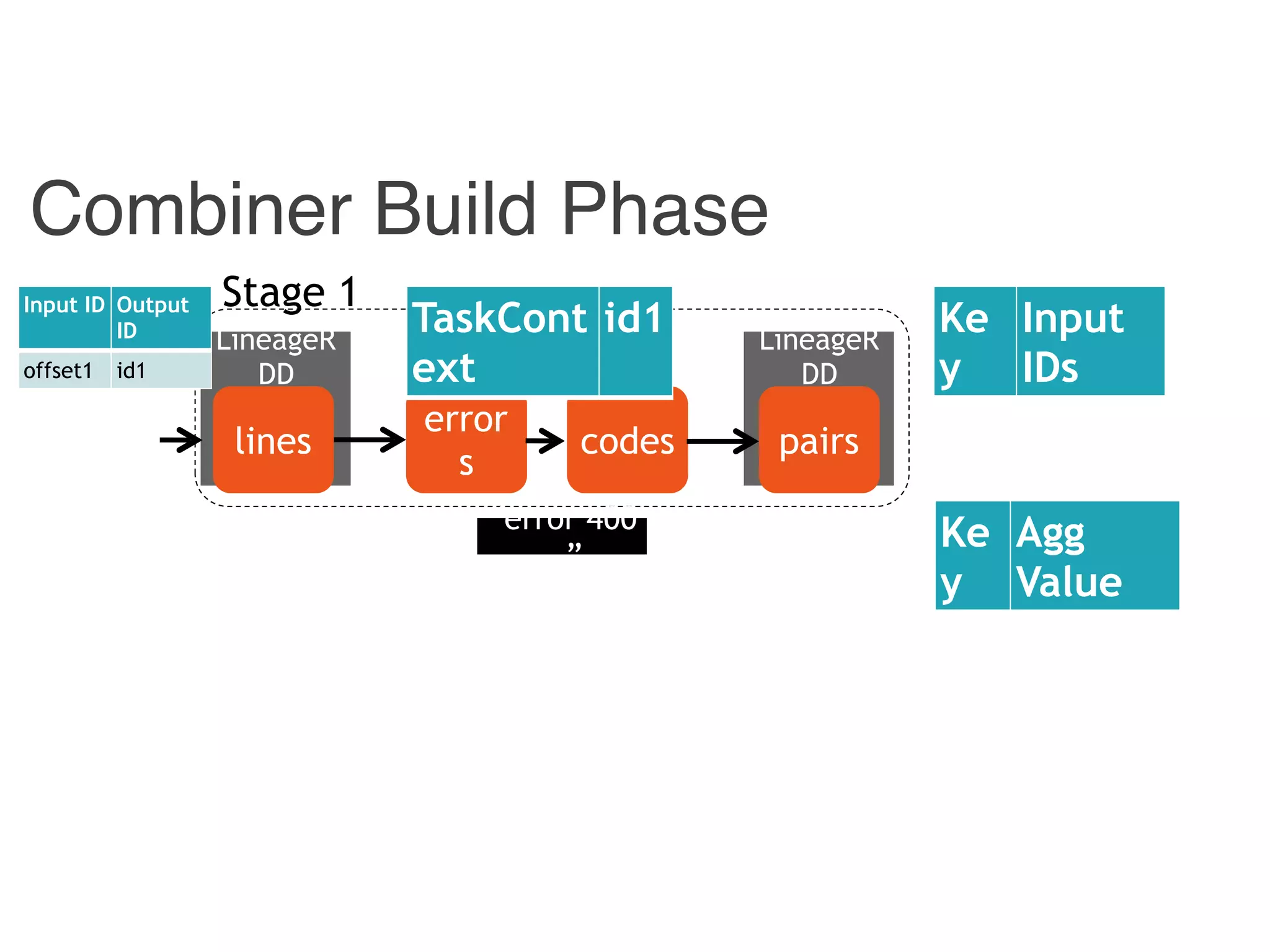
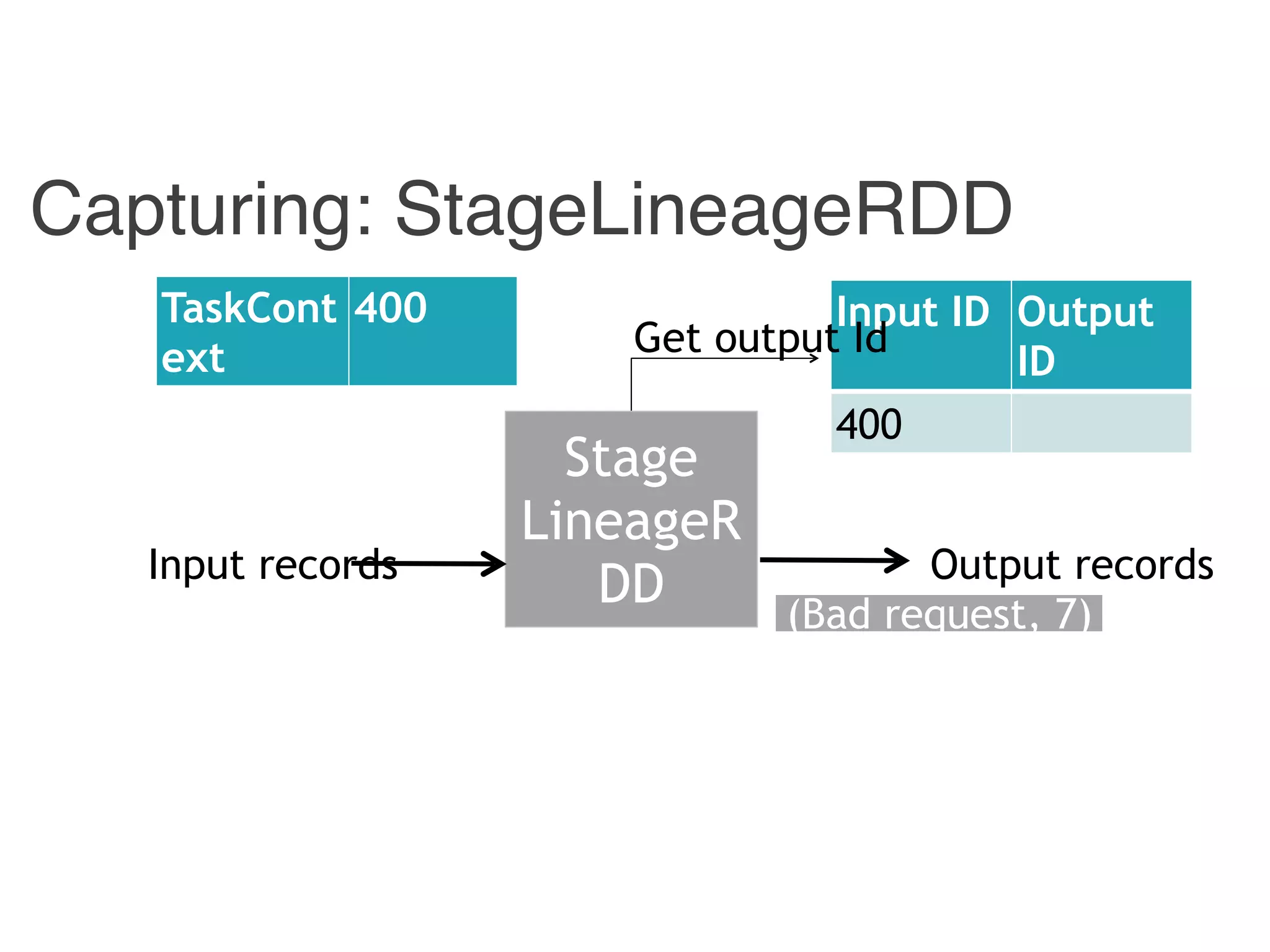
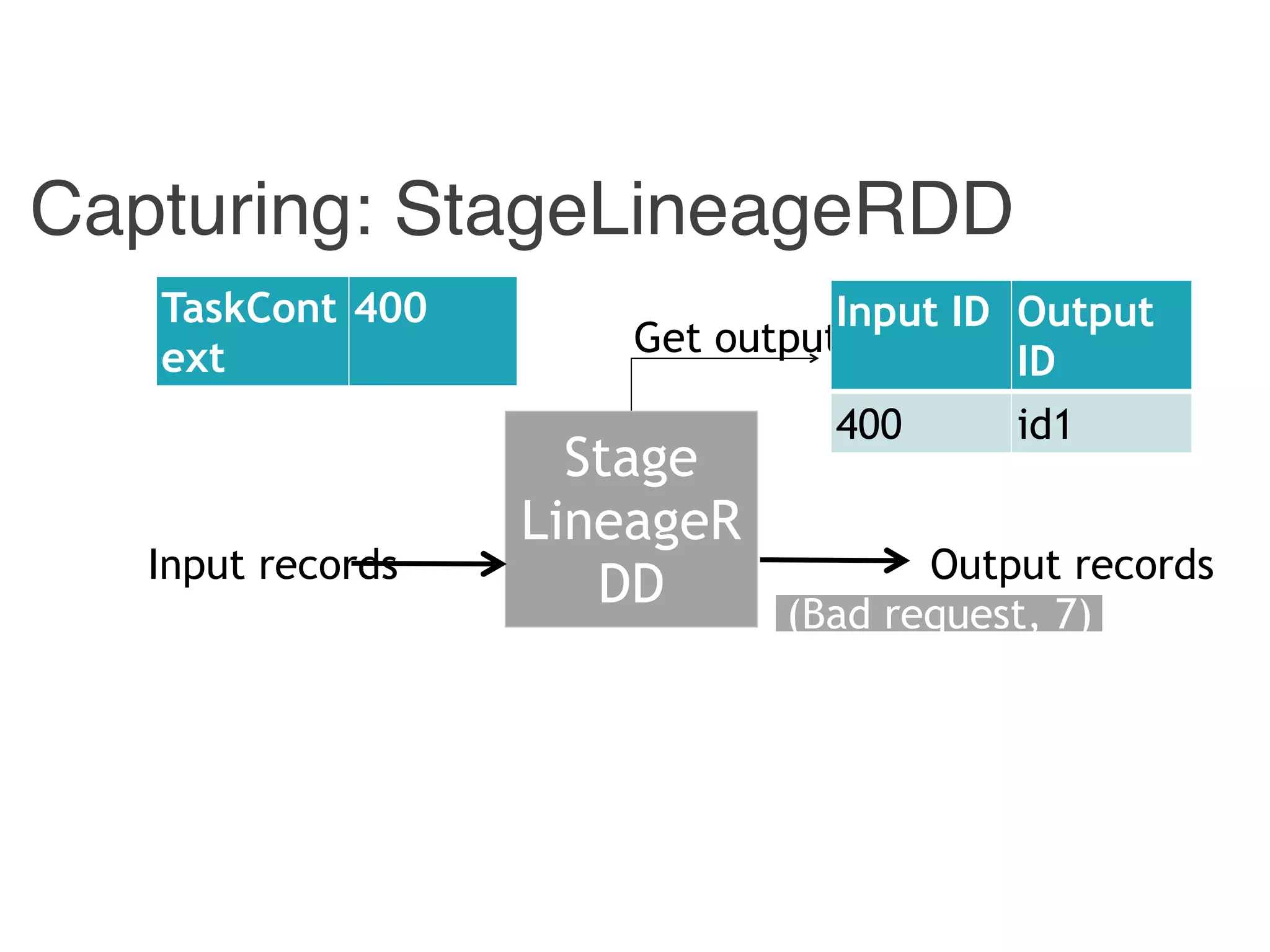
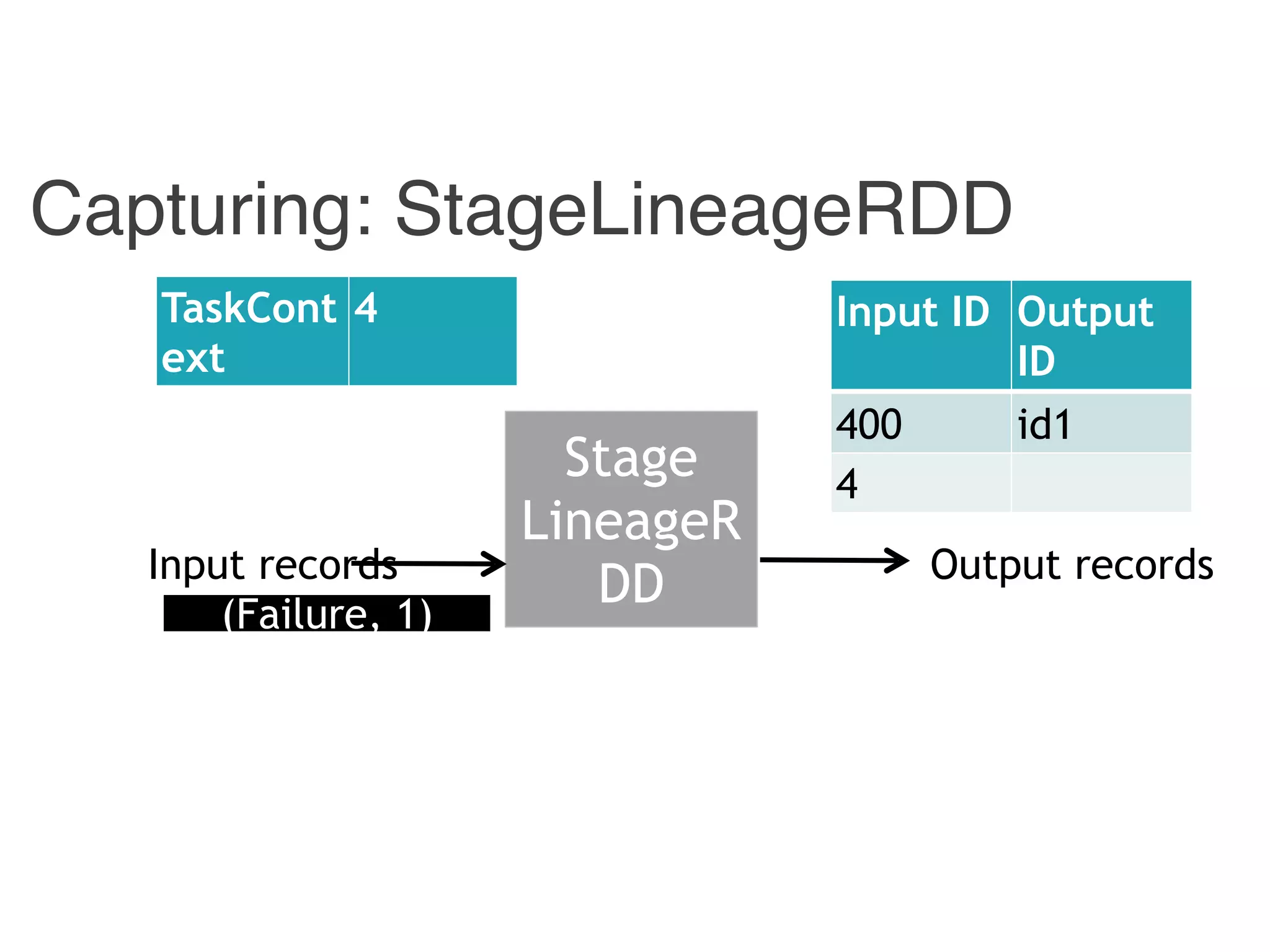
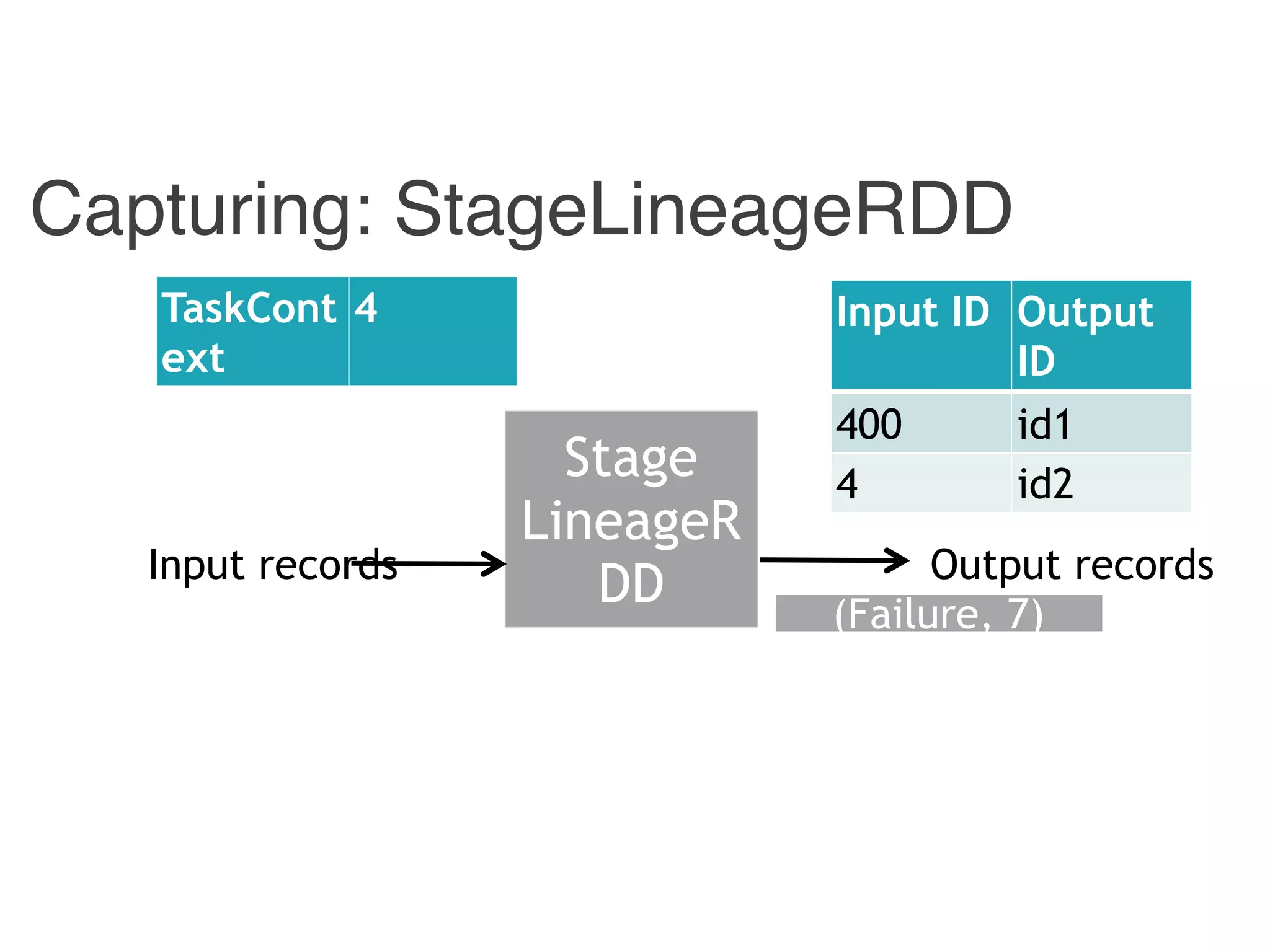
Input ID Output ID
{ id1, id 3} 400
{ id2 } 4
Input
ID
Output
ID
offset1 id1
offset2 id2
offset3 id3
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-32-2048.jpg)
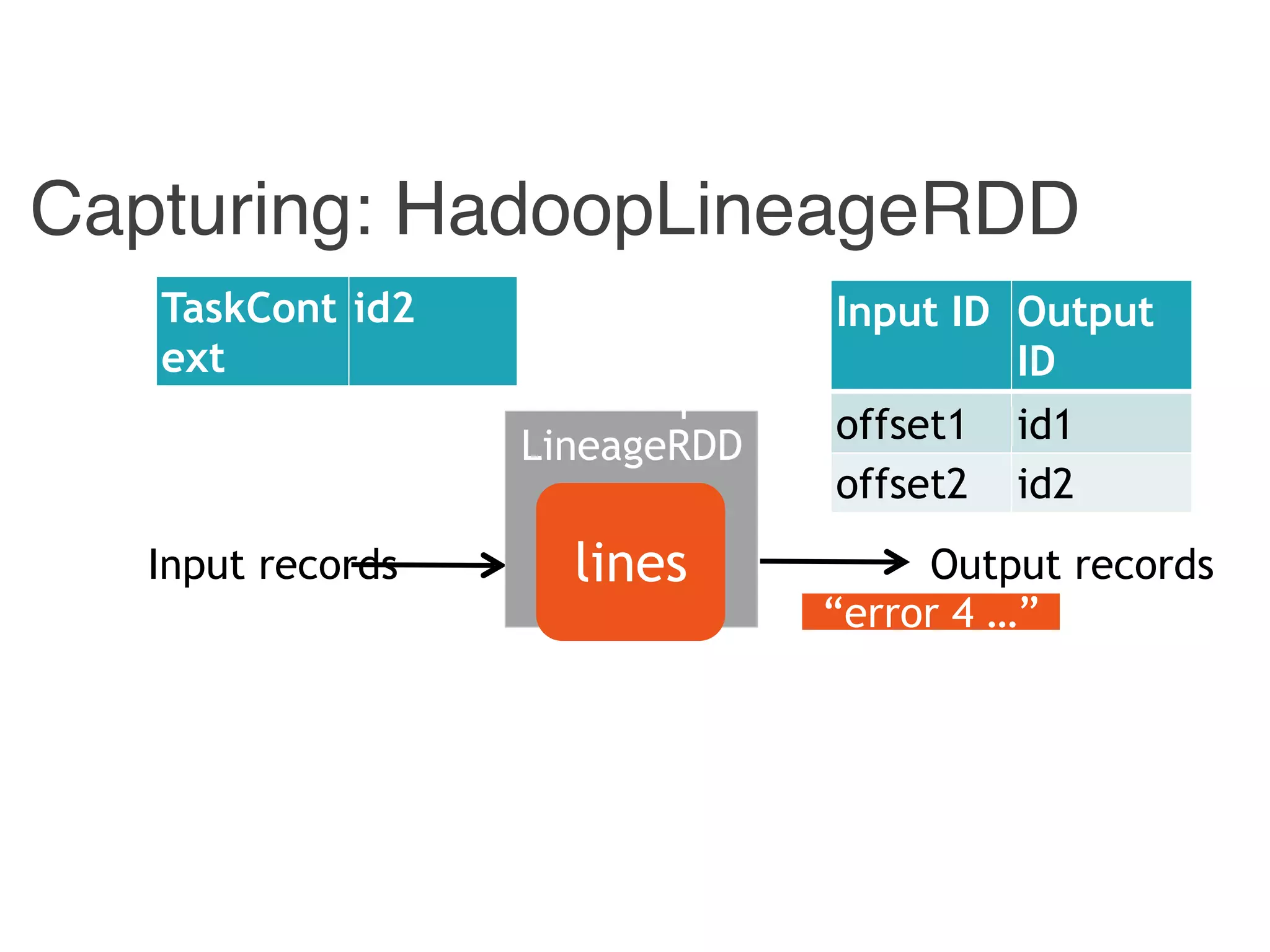
![Input ID Output ID
offset1 id1
offset2 id2
offset3 id3
Input ID Output ID
{ id1, id 3} 400
{ id2 } 4
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Hadoop Combiner Reducer Stage
Example: Captured Data Lineage](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-34-2048.jpg)
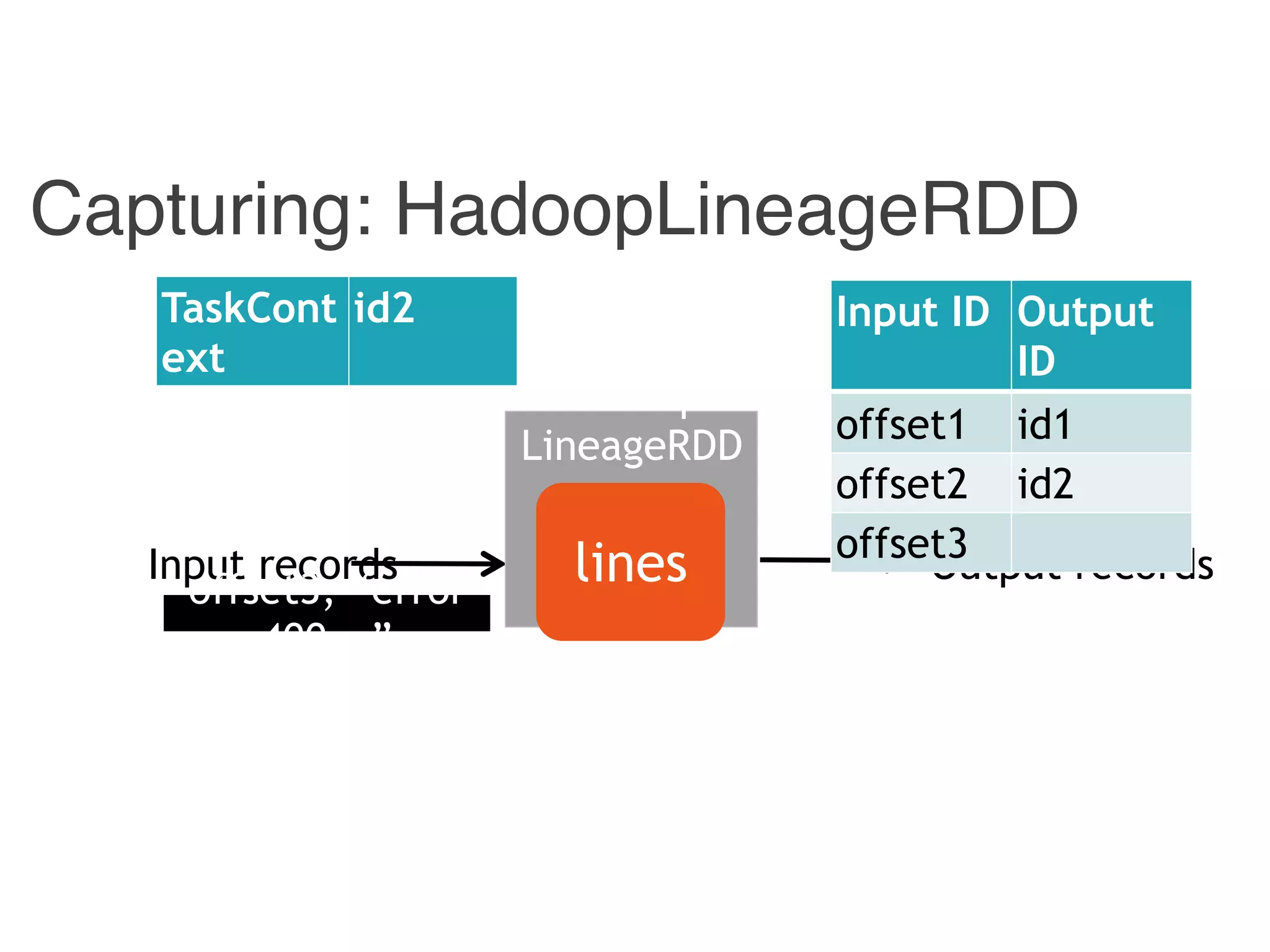
![Input ID Output ID
offset1 id1
offset2 id2
offset3 id3
Input ID Output ID
{ id1, id 3} 400
{ id2 } 4
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Hadoop Combiner Reducer Stage
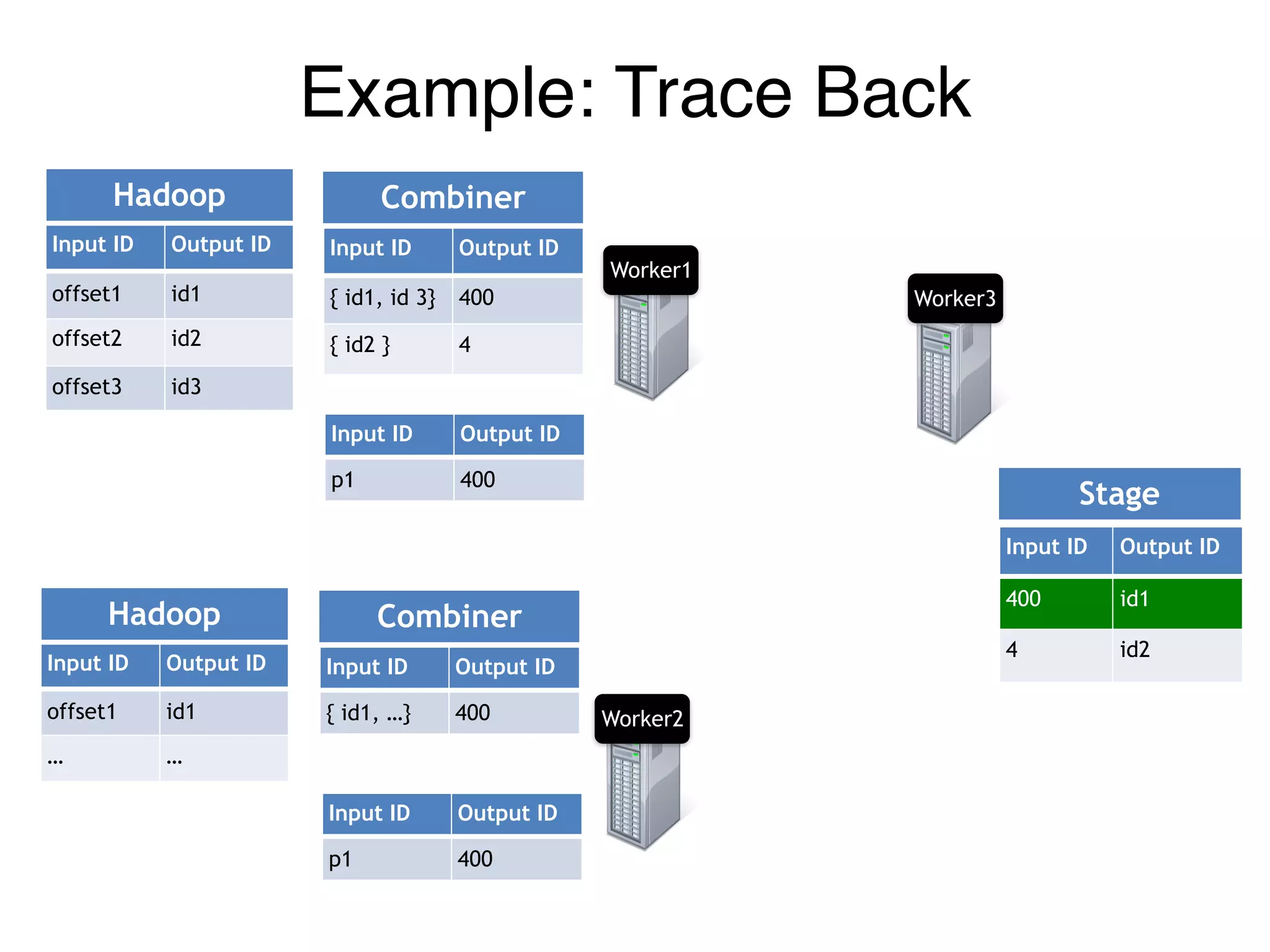
Example: Trace Back](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-35-2048.jpg)
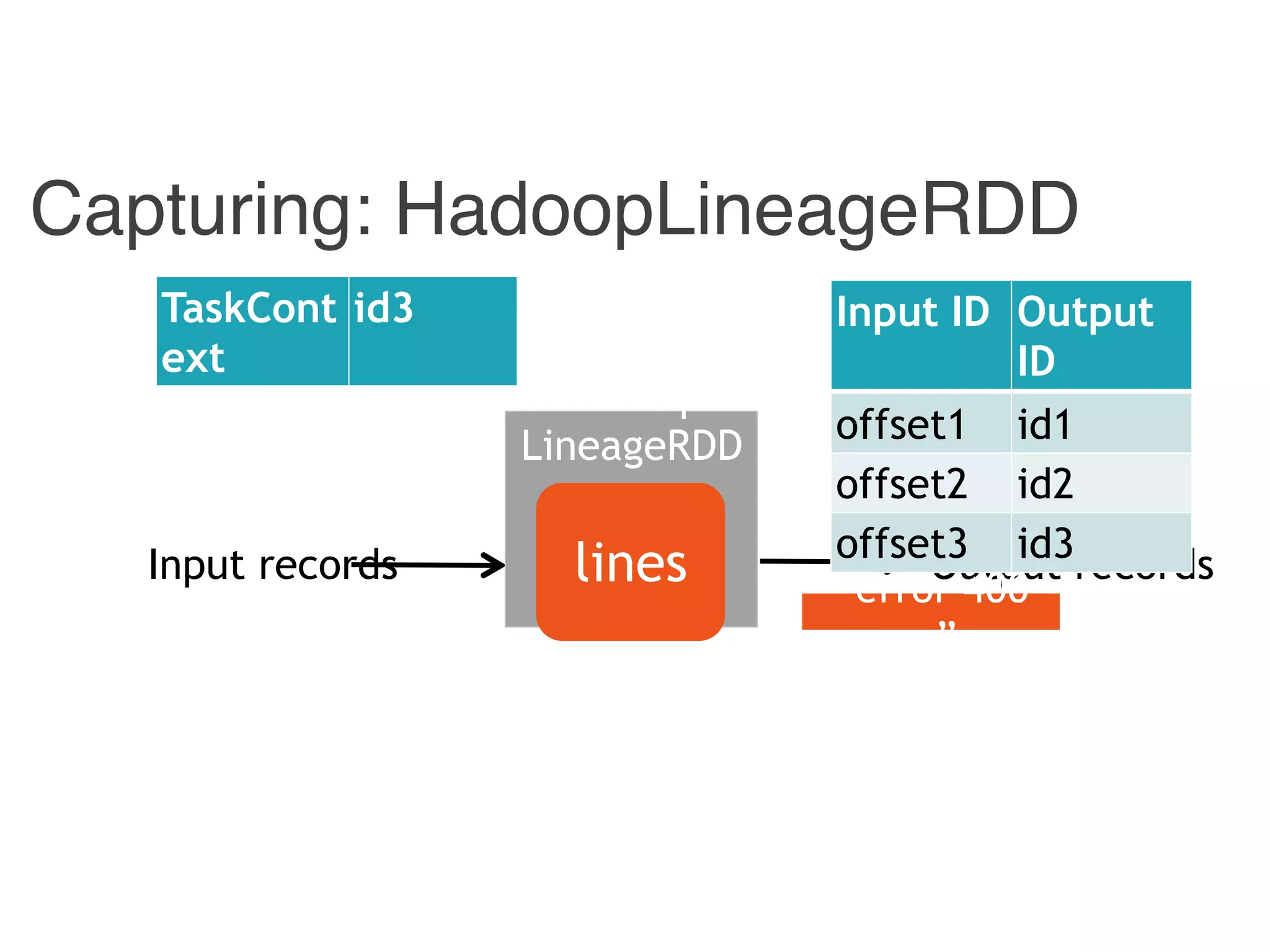
![Input ID Output ID
offset1 id1
offset2 id2
offset3 id3
Input ID Output ID
{ id1, id 3} 400
{ id2 } 4
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Hadoop Combiner Reducer Stage
Example: Trace Back
Stage.Input IDReducer.Output ID](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-36-2048.jpg)
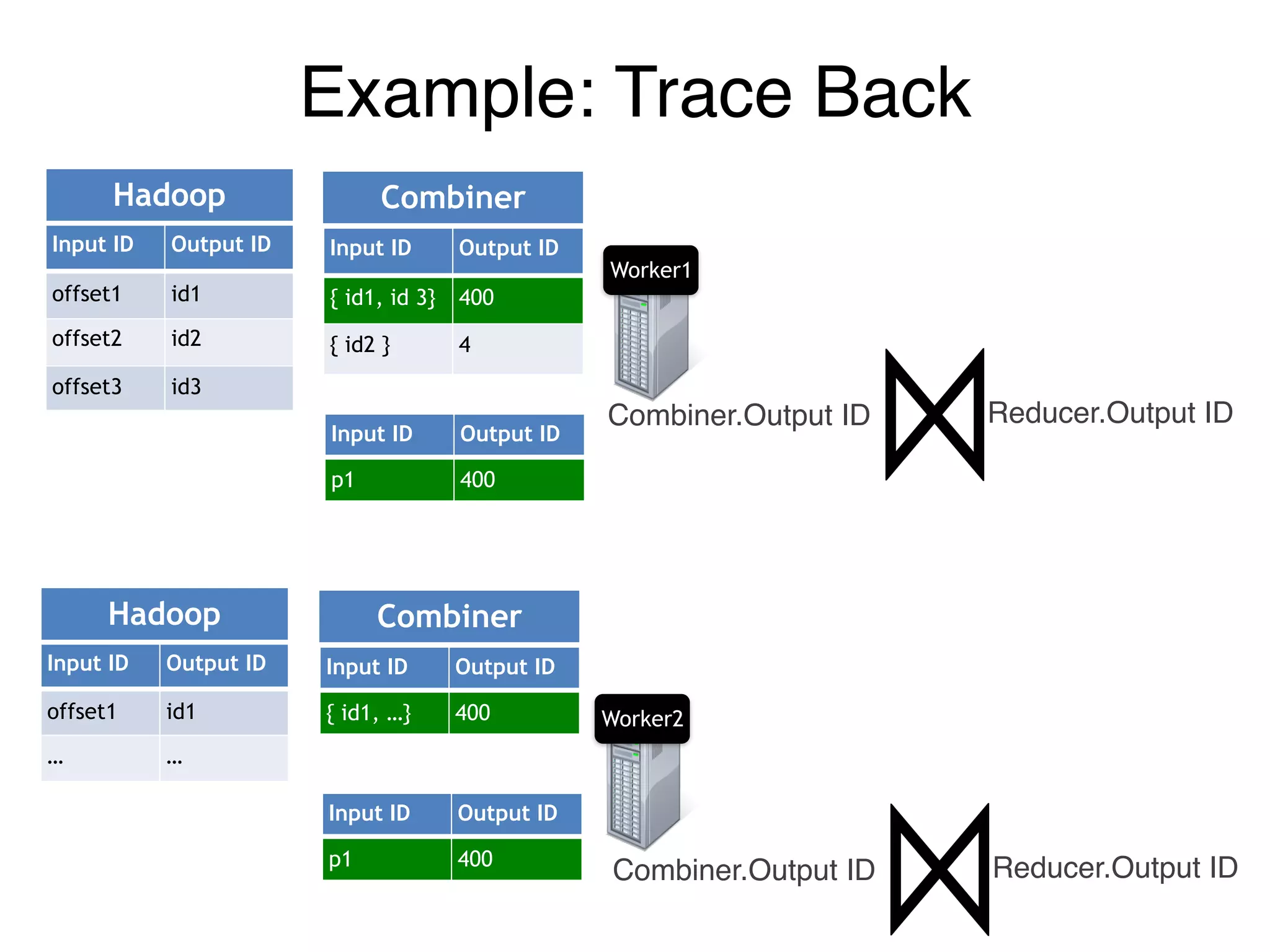
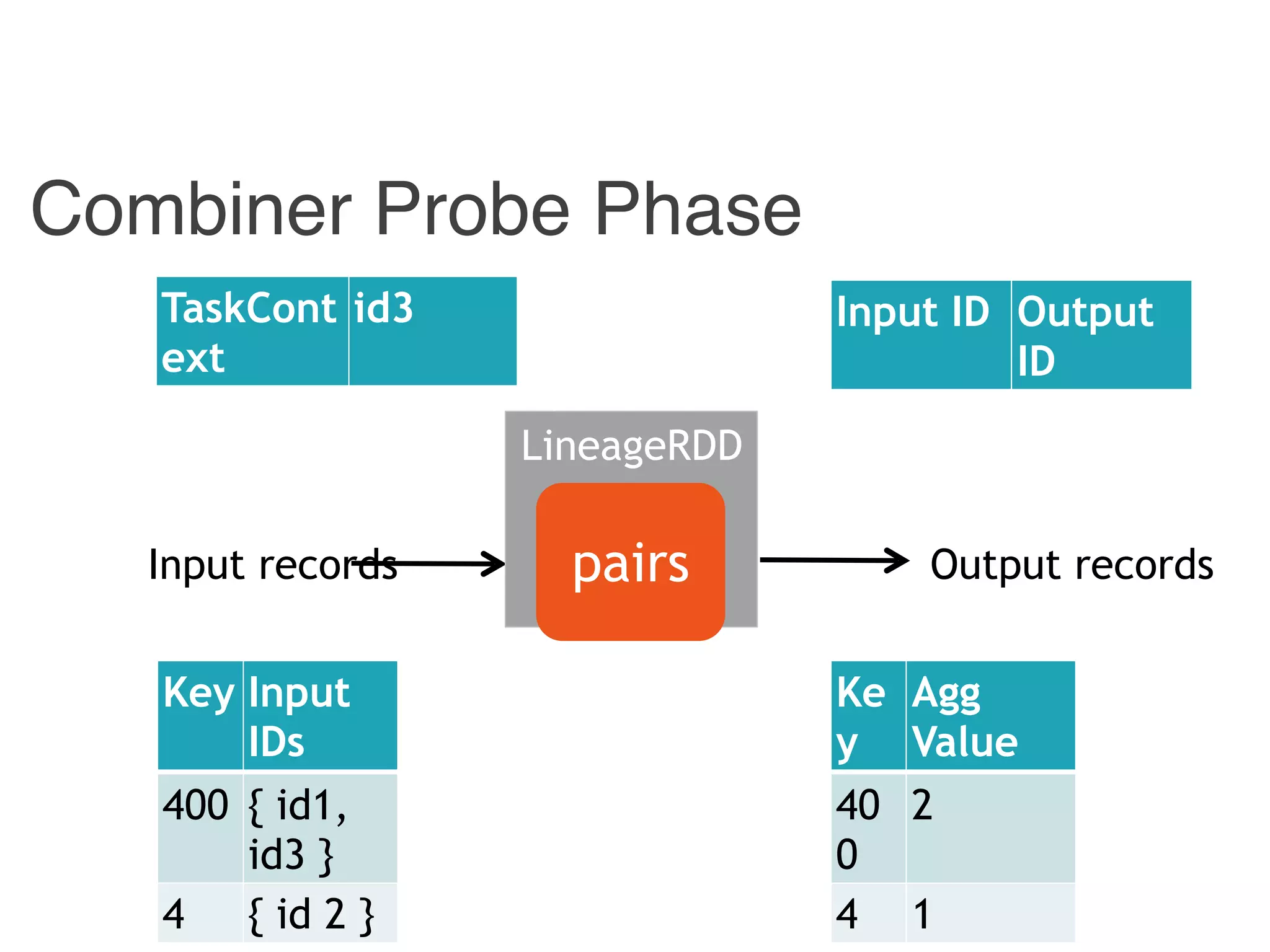
![Reducer.Output IDCombiner.Output ID
Example: Trace Back
Input ID Output ID
offset1 id1
offset2 id2
offset3 id3
Input ID Output ID
{ id1, id 3} 400
{ id2 } 4
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Hadoop Combiner Reducer Stage](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-37-2048.jpg)
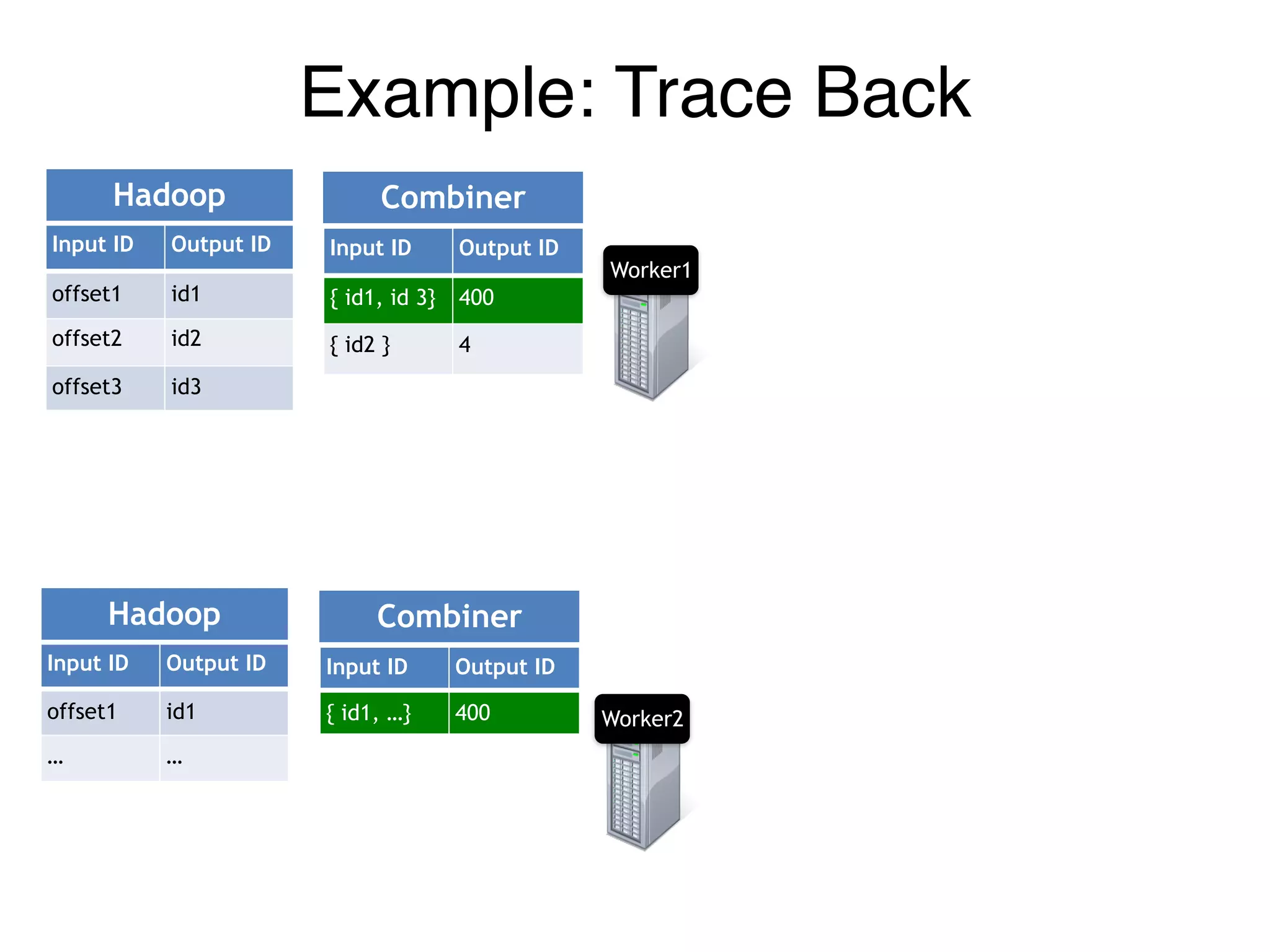
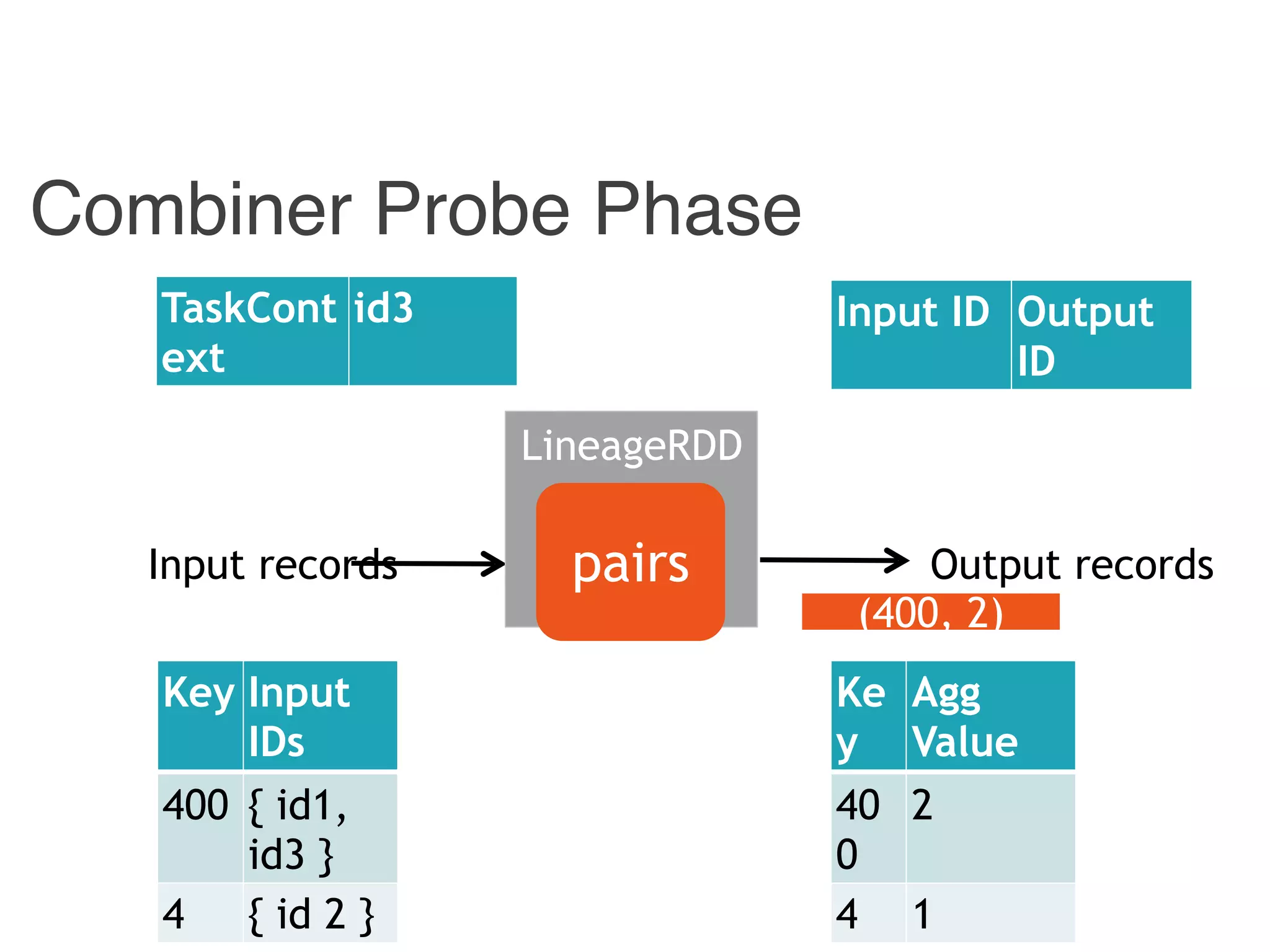
![Example: Trace Back
Input ID Output ID
offset1 id1
offset2 id2
offset3 id3
Input ID Output ID
{ id1, id 3} 400
{ id2 } 4
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Hadoop Combiner Reducer Stage
Combiner.Input IDHadoop.Output ID
Now let’s do it for real!](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-38-2048.jpg)
![Worker1
Worker2
Worker3
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Reducer Stage
Input ID Output ID
offset1 id1
offset2 id2
offset3 id3
Input ID Output ID
{ id1, id 3} 400
{ id2 } 4
Hadoop Combiner
Input ID Output ID
offset1 id1
… …
Input ID Output ID
{ id1, …} 400
Hadoop Combiner
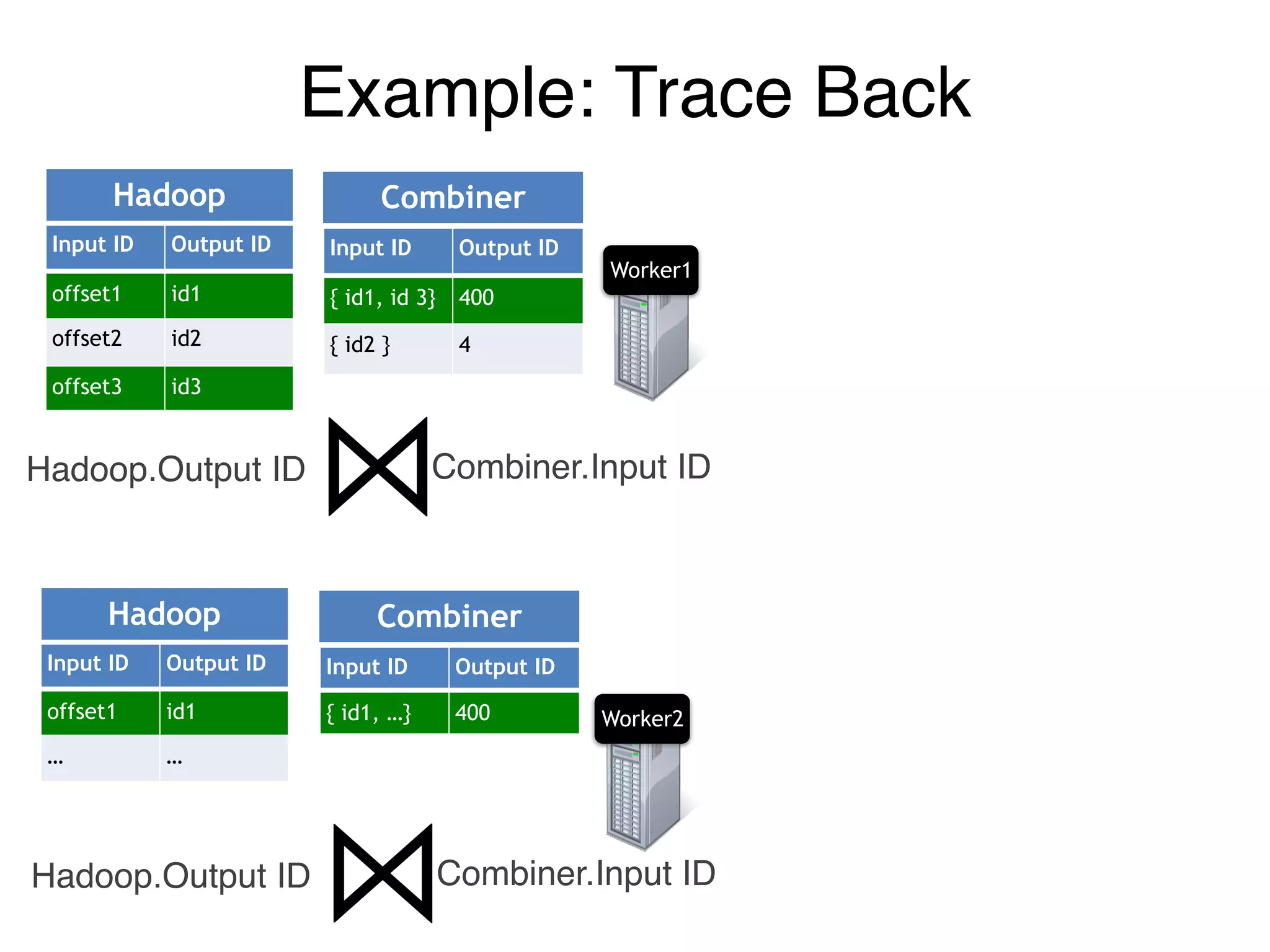
Example: Trace Back](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-39-2048.jpg)
![Example: Trace Back
Worker1
Worker2
Worker3
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Reducer Stage
Input ID Output ID
offset1 id1
offset2 id2
offset3 id3
Input ID Output ID
{ id1, id 3} 400
{ id2 } 4
Hadoop Combiner
Input ID Output ID
offset1 id1
… …
Input ID Output ID
{ id1, …} 400
Hadoop Combiner](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-40-2048.jpg)
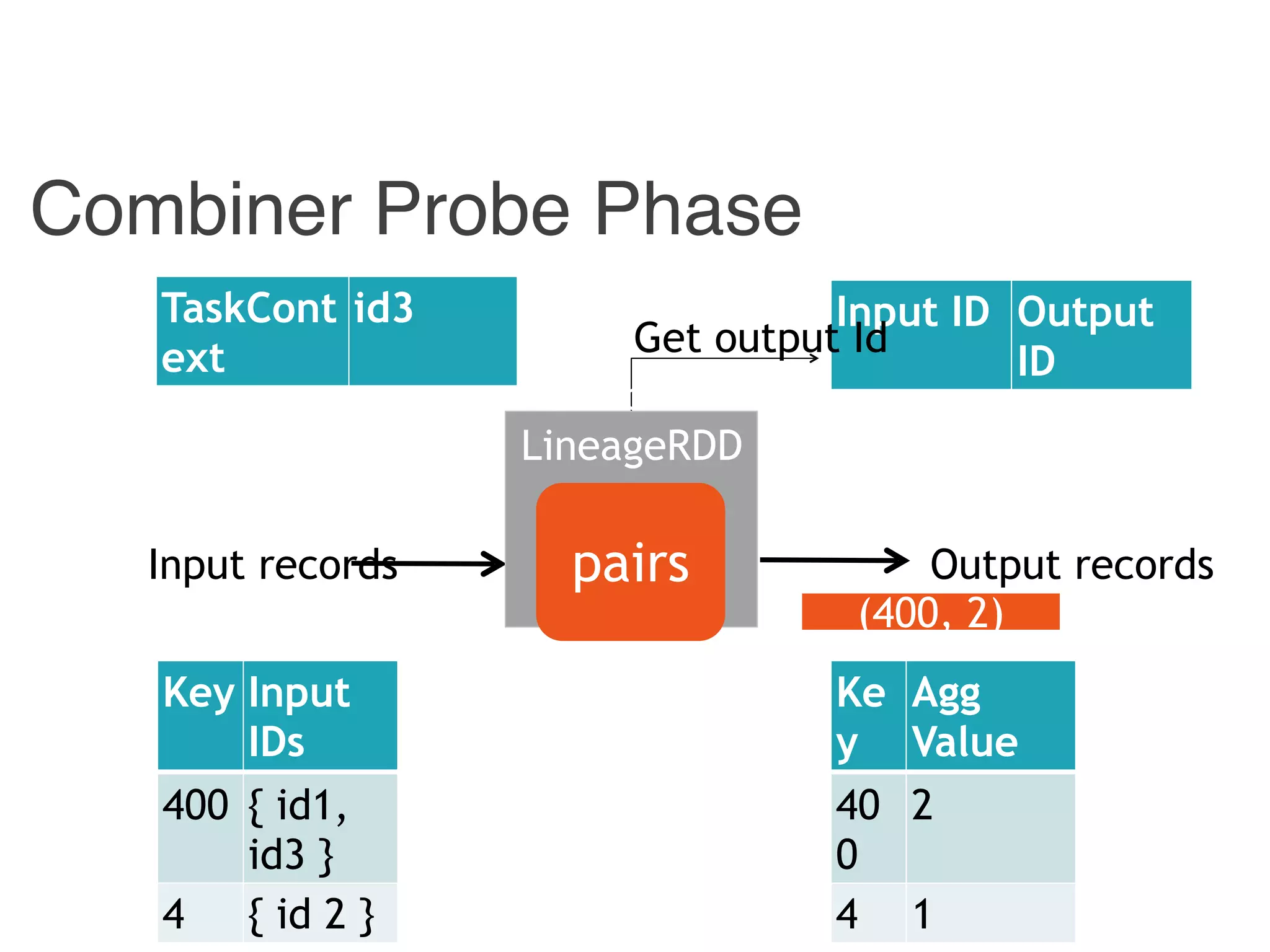
![Example: Trace Back
Worker3
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Reducer Stage](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-41-2048.jpg)
![Example: Trace Back
Worker3
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Reducer Stage
Worker3
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Reducer Stage
Stage.Input IDReducer.Output ID](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-42-2048.jpg)
![Example: Trace Back
Worker1
Worker2
Worker3
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Reducer Stage
Input ID Output ID
offset1 id1
offset2 id2
offset3 id3
Input ID Output ID
{ id1, id 3} 400
{ id2 } 4
Hadoop Combiner
Input ID Output ID
offset1 id1
… …
Input ID Output ID
{ id1, …} 400
Hadoop Combiner](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-43-2048.jpg)
![Example: Trace Back
Worker1
Worker2
Worker3
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Reducer Stage
Input ID Output ID
offset1 id1
offset2 id2
offset3 id3
Input ID Output ID
{ id1, id 3} 400
{ id2 } 4
Hadoop Combiner
Input ID Output ID
offset1 id1
… …
Input ID Output ID
{ id1, …} 400
Hadoop Combiner
Worker1
Worker2
Worker3
Input ID Output ID
[p1, p2] 400
[ p1 ] 4
Input ID Output ID
400 id1
4 id2
Reducer Stage
Input ID Output ID
offset1 id1
offset2 id2
offset3 id3
Input ID Output ID
{ id1, id 3} 400
{ id2 } 4
Hadoop Combiner
Input ID Output ID
offset1 id1
… …
Input ID Output ID
{ id1, …} 400
Hadoop Combiner
Input ID Output ID
p1 400
Input ID Output ID
p1 400
Targeted Shuffle](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-44-2048.jpg)

![Debugging workflow
๏ Run program
๏ Understand the cause for bugs / outliers:
• Lineage
• Breakpoints/watchpoints
• Crash culprit
๏ Fix bug
• Fast selective replay
}
} Titian [VLDB 2016]
BigDebug [ICSE 2016]](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-51-2048.jpg)

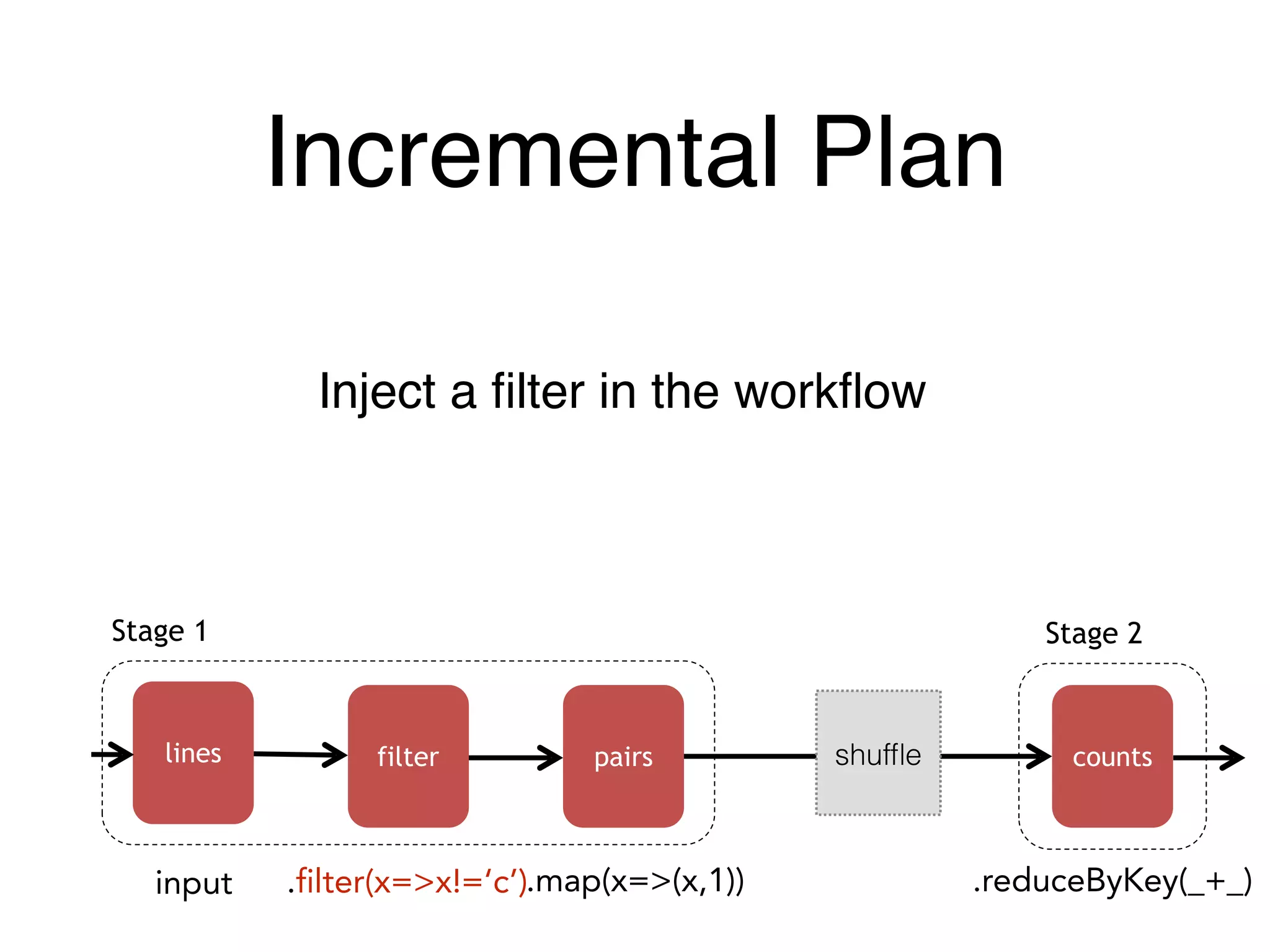
![Incremental Plan
Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(c, 1)
(aa, 1)
(c, 1)
Shuffle
(aa, [1, 1])
(b, 1)
(c, [1, 1])
Reduce
(aa, 2)
(b, 1)
(c, 2)
countspairslines
Stage 1 Stage 2
shuffle
input .map(x=>(x,1)) .reduceByKey(_+_)](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-53-2048.jpg)
![Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(aa, 1)
Shuffle
(aa, [1, 1])
(b, 1)
Reduce
(aa, 2)
(b, 1)
Filter
aa
b
aa
countspairslines
Stage 1 Stage 2
shufflefilter
input .filter(x=>x!=‘c’).map(x=>(x,1)) .reduceByKey(_+_)
Incremental Plan](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-55-2048.jpg)
![Incremental Plan
Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(c, 1)
(aa, 1)
(c, 1)
Shuffle
(aa, [1, 1])
(b, 1)
(c, [1, 1])
Reduce
(aa, 2)
(b, 1)
(c, 2)
Filter
aa
b
c
aa
c](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-56-2048.jpg)
![Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(c, 1)
(aa, 1)
(c, 1)
Shuffle
(aa, [1, 1])
(b, 1)
(c, [1, 1])
Reduce
(aa, 2)
(b, 1)
(c, 2)
Filter
aa
b
c
aa
c
δFilter
—c
—c
Incremental Plan](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-57-2048.jpg)
![Incremental Plan
Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(c, 1)
(aa, 1)
(c, 1)
Shuffle
(aa, [1, 1])
(b, 1)
(c, [1, 1])
Reduce
(aa, 2)
(b, 1)
(c, 2)
Filter
aa
b
c
aa
c
δFilter
—c
—c
∆Map
—(c, 1)
—(c, 1)](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-58-2048.jpg)
![Incremental Plan
Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(c, 1)
(aa, 1)
(c, 1)
Shuffle
(aa, [1, 1])
(b, 1)
(c, [1, 1])
Reduce
(aa, 2)
(b, 1)
(c, 2)
Filter
aa
b
c
aa
c
δFilter
—c
—c
∆Map
—(c, 1)
—(c, 1)
∆Shuffle
c, [—1, —1])](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-59-2048.jpg)
![Incremental Plan
Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(c, 1)
(aa, 1)
(c, 1)
Shuffle
(aa, [1, 1])
(b, 1)
(c, [1, 1])
Reduce
(aa, 2)
(b, 1)
(c, 2)
Filter
aa
b
c
aa
c
δFilter
—c
—c
∆Map
—(c, 1)
—(c, 1)
∆Shuffle
c, [—1, —1])
∆Reduce
—(c, 2)](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-60-2048.jpg)


![Commutative Rewrite
Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(c, 1)
(aa, 1)
(c, 1)
Shuffle
(aa, [1, 1])
(b, 1)
(c, [1, 1])
Reduce
(aa, 2)
(b, 1)
(c, 2)
Filter
aa
b
c
aa
c
filter(x=>x!=‘c’)](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-64-2048.jpg)
![Commutative Rewrite
Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(c, 1)
(aa, 1)
(c, 1)
Shuffle
(aa, [1, 1])
(b, 1)
(c, [1, 1])
Reduce
(aa, 2)
(b, 1)
(c, 2)
Filter
aa
b
c
aa
c
filter(x=>x!=‘c’)
But the input to the filter is (word, 1)
We cannot use the filter anymore](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-65-2048.jpg)
![Commutative Rewrite
Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(c, 1)
(aa, 1)
(c, 1)
Shuffle
(aa, [1, 1])
(b, 1)
(c, [1, 1])
Reduce
(aa, 2)
(b, 1)
(c, 2)
Filter
aa
b
c
aa
c
filter(x=>x!=‘c’)
Observe that the map is invertible
We can use the old filter by using the inverse of the map](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-66-2048.jpg)
![Commutative Rewrite
Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(c, 1)
(aa, 1)
(c, 1)
Shuffle
(aa, [1, 1])
(b, 1)
(c, [1, 1])
Reduce
(aa, 2)
(b, 1)
(c, 2)
Filter’
aa
b
c
aa
c
filter’((x, o)=>x!=‘c’)
Rewritten filter](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-67-2048.jpg)
![Commutative Rewrite
Input
aa
b
c
aa
c
Map
(aa, 1)
(b, 1)
(c, 1)
(aa, 1)
(c, 1)
Shuffle
(aa, [1, 1])
(b, 1)
(c, [1, 1])
Reduce
(aa, 2)
(b, 1)
(c, 2)
Filter’
(aa, 2)
(b, 1)
filter((x, o)=>x!=‘c’)
Shuffle and Reduce operations preserve keys](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-68-2048.jpg)








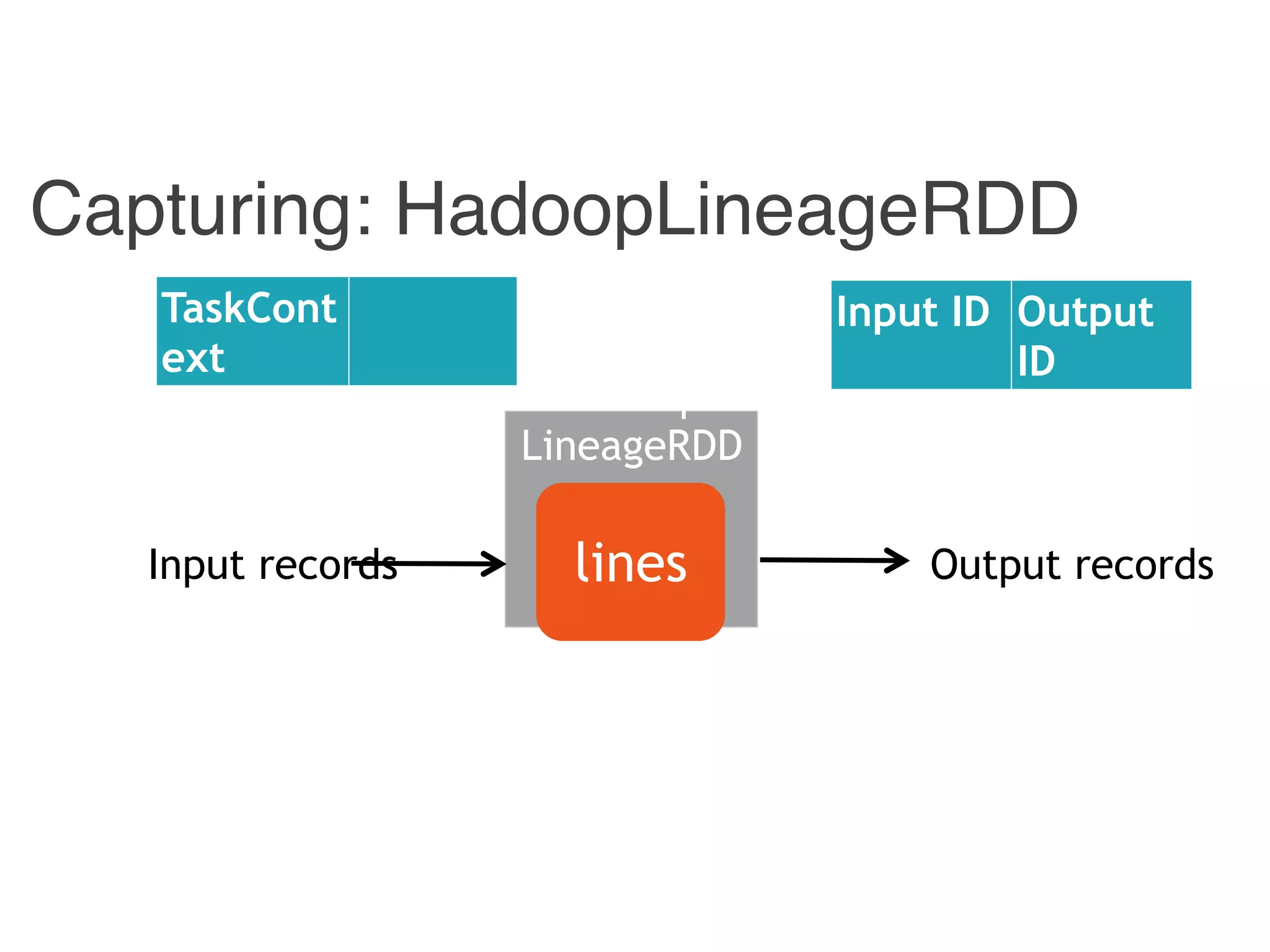
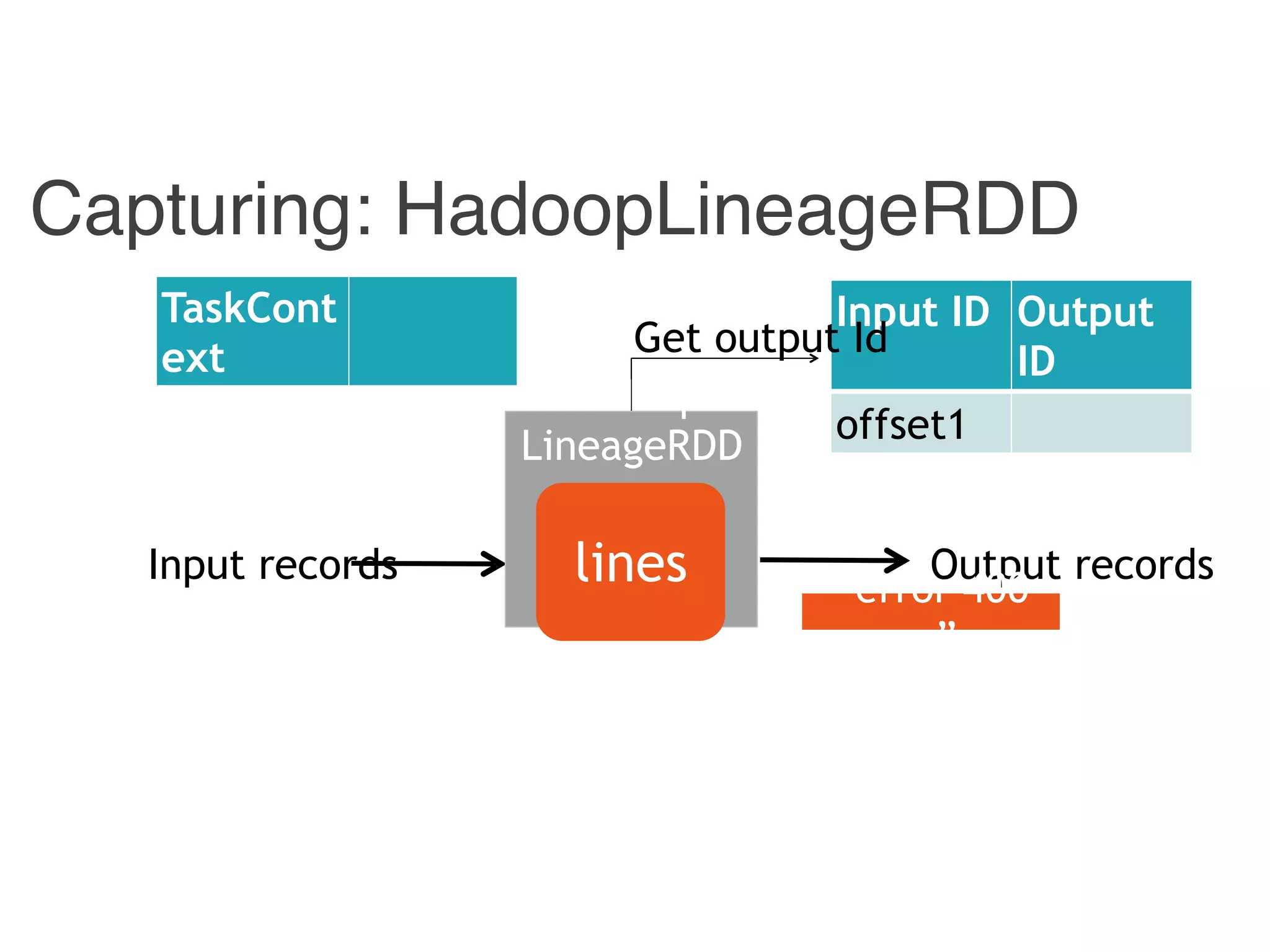
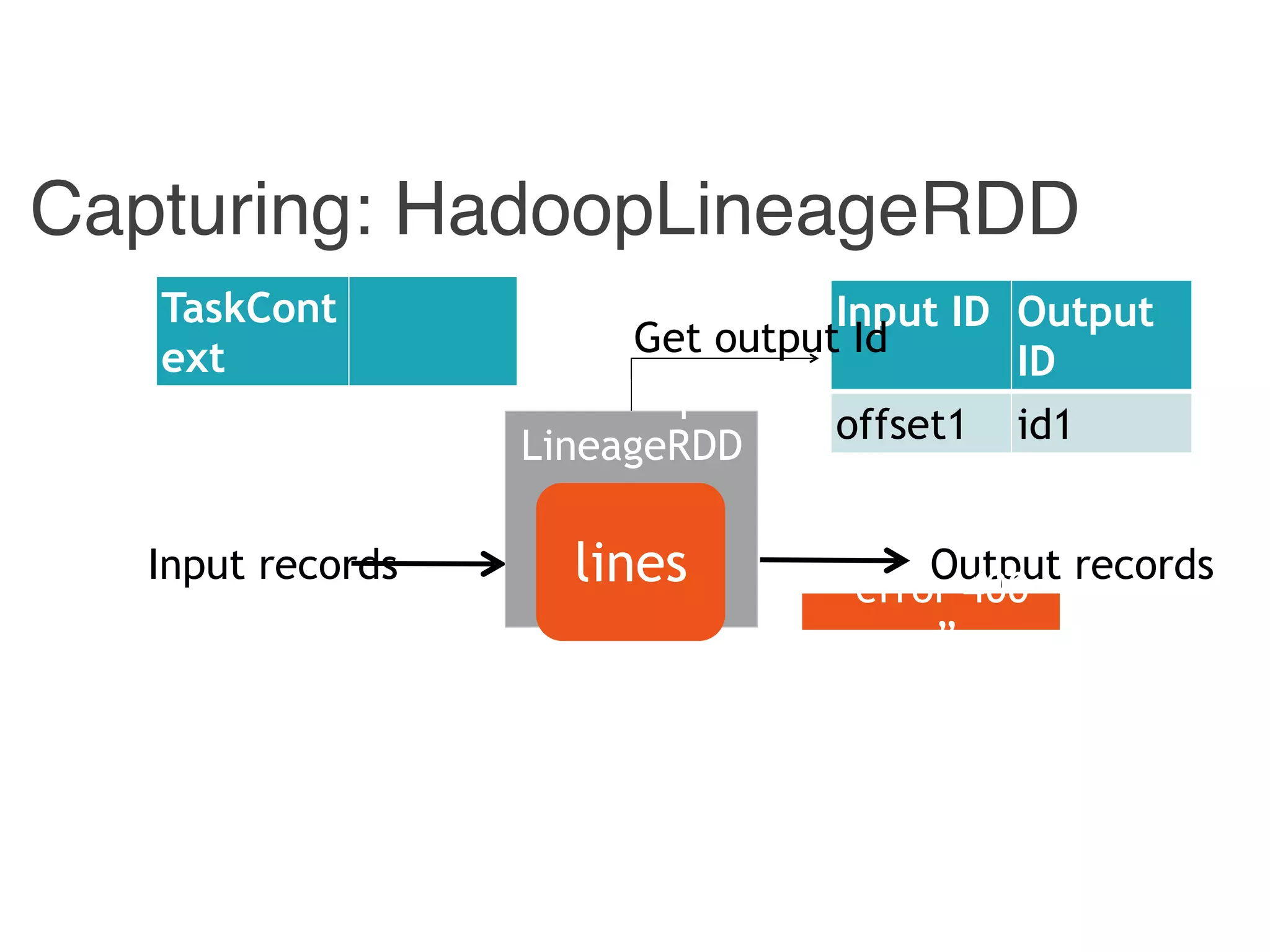
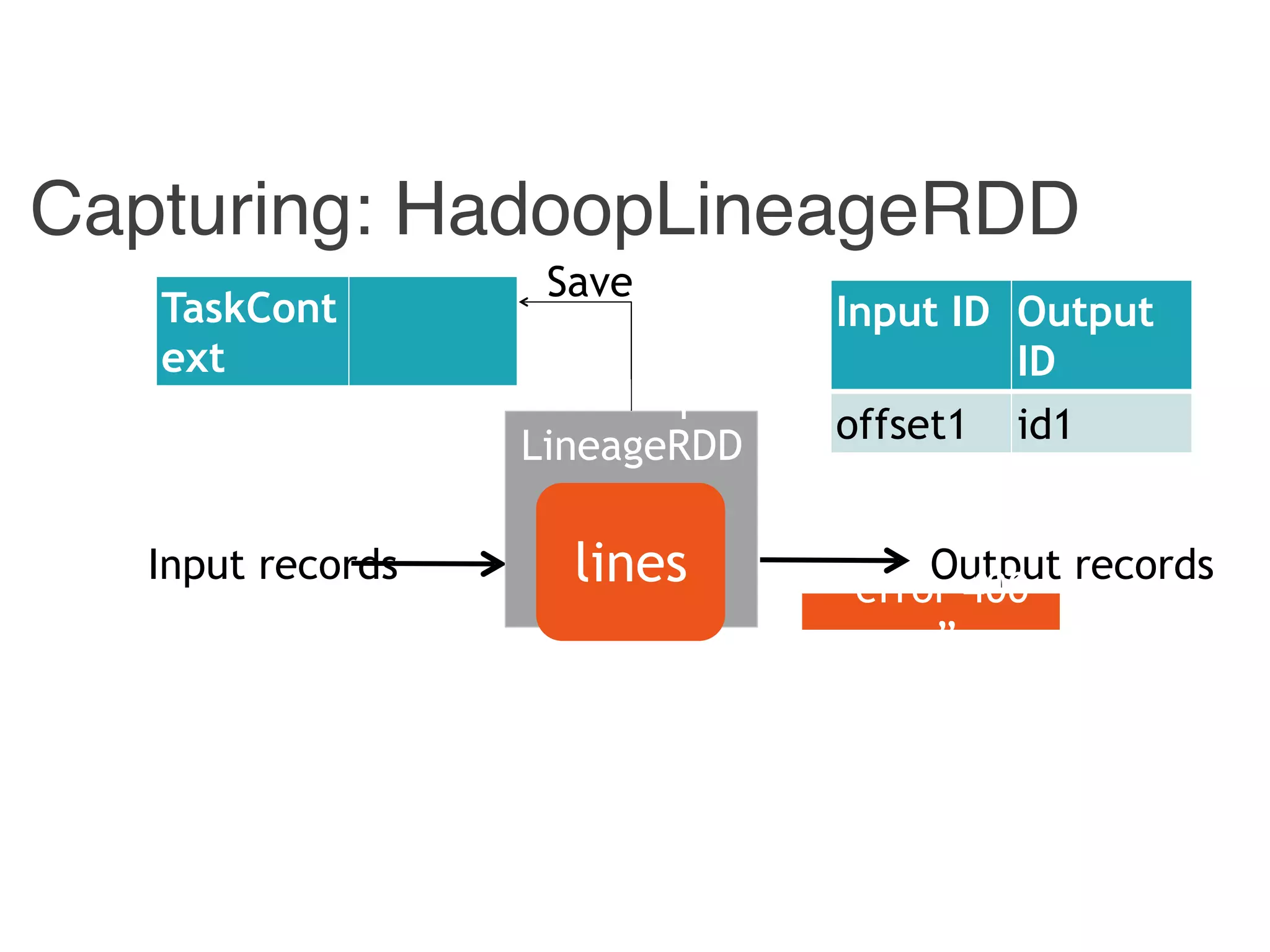
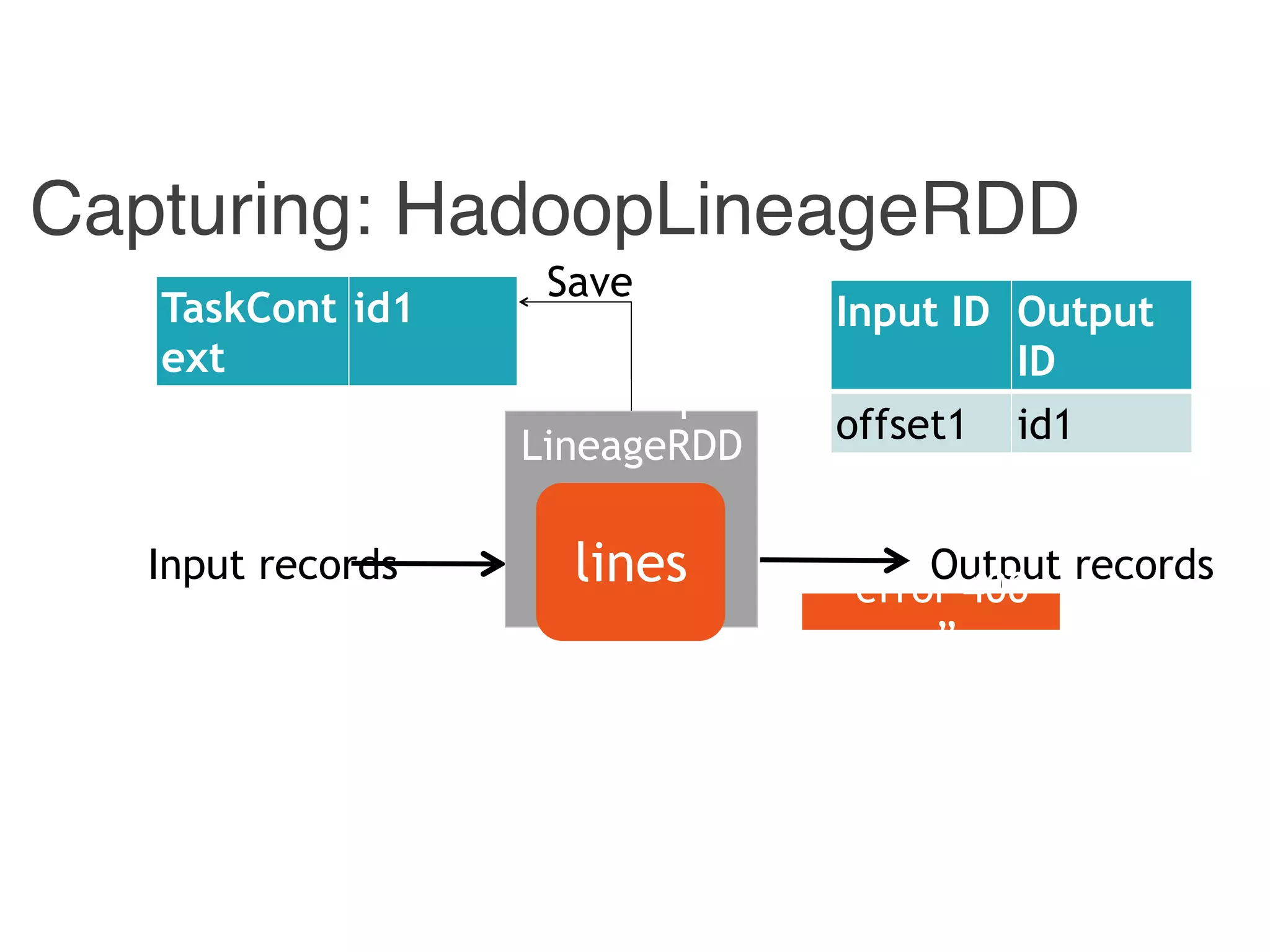
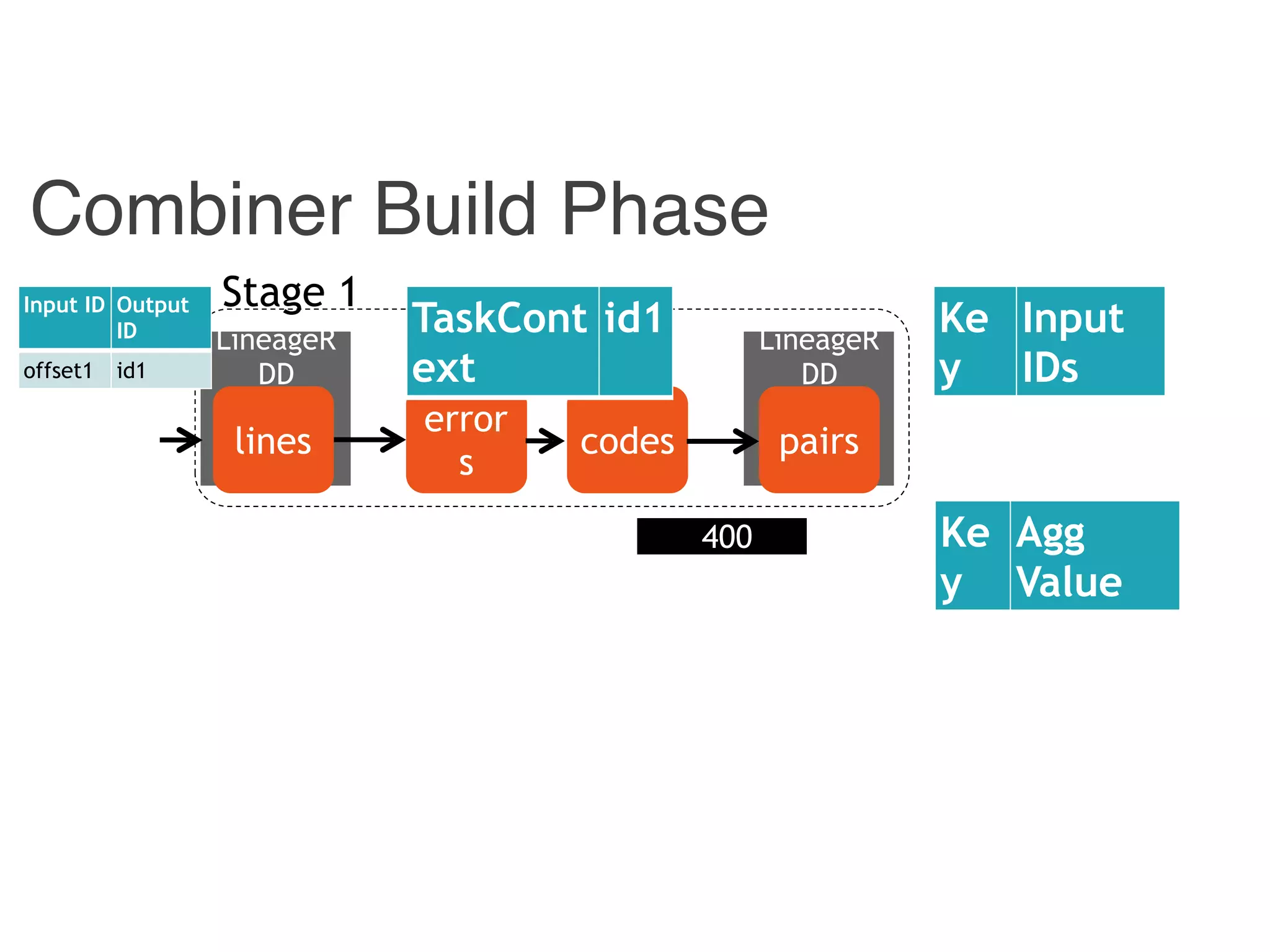
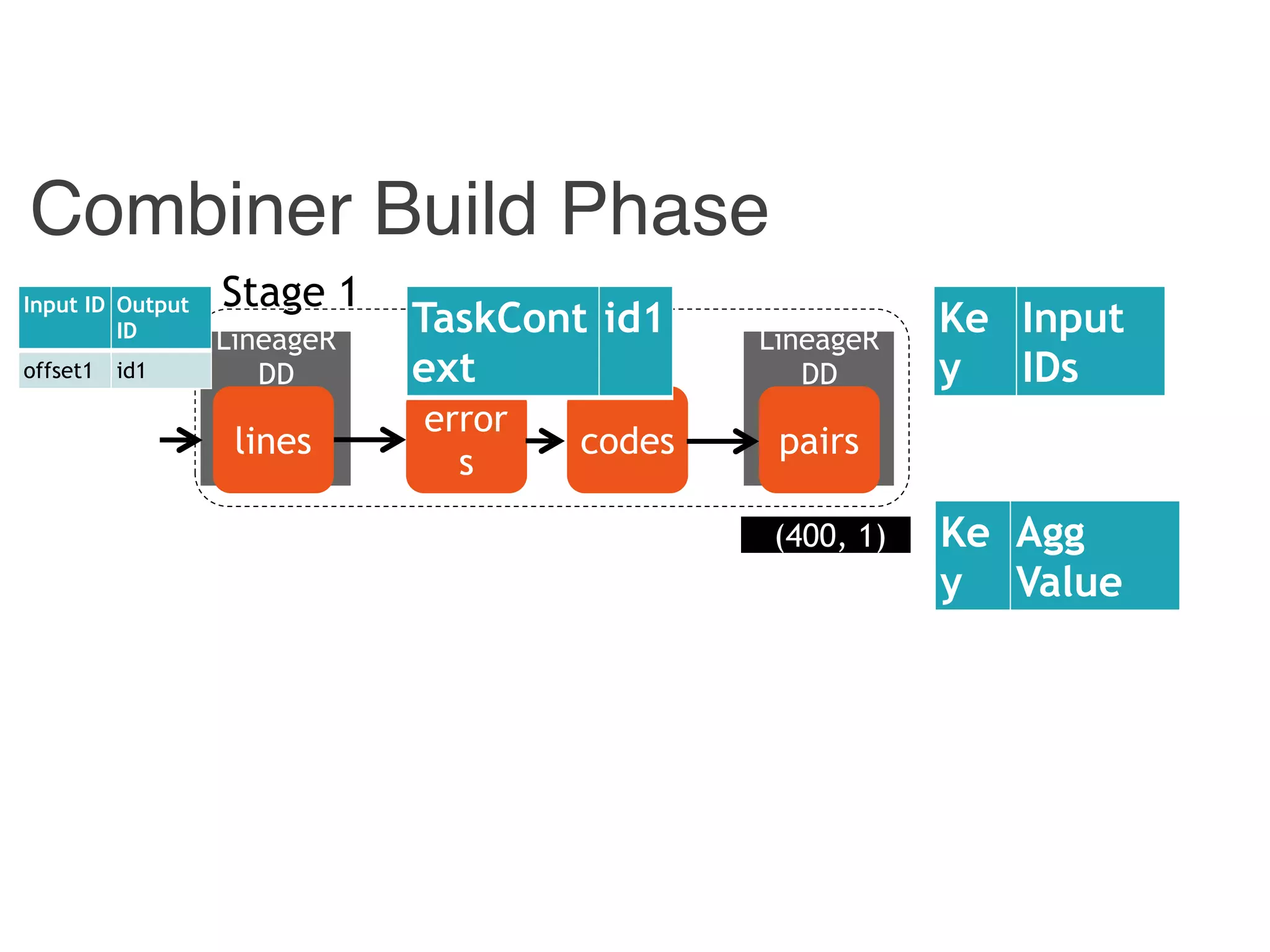
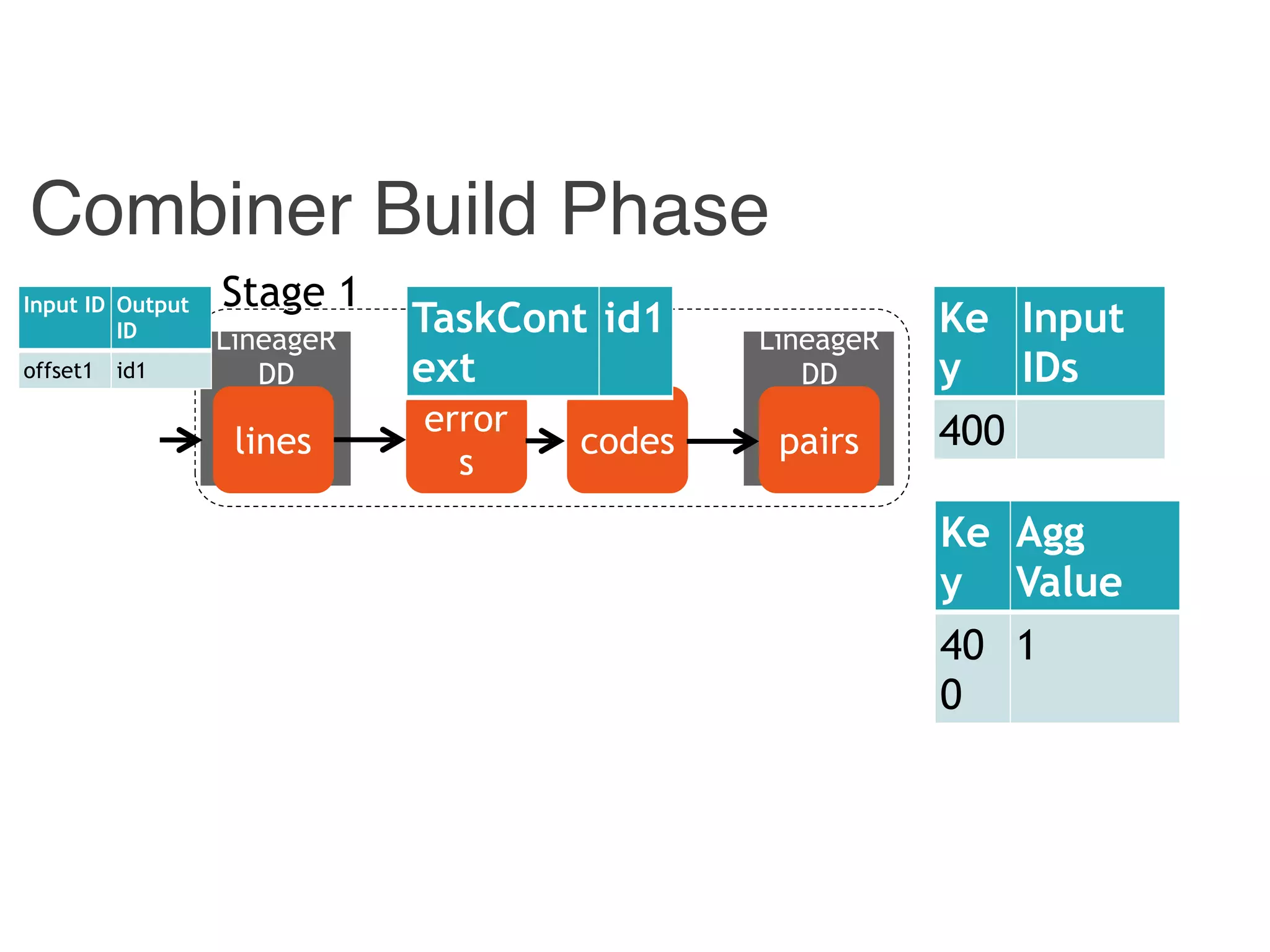
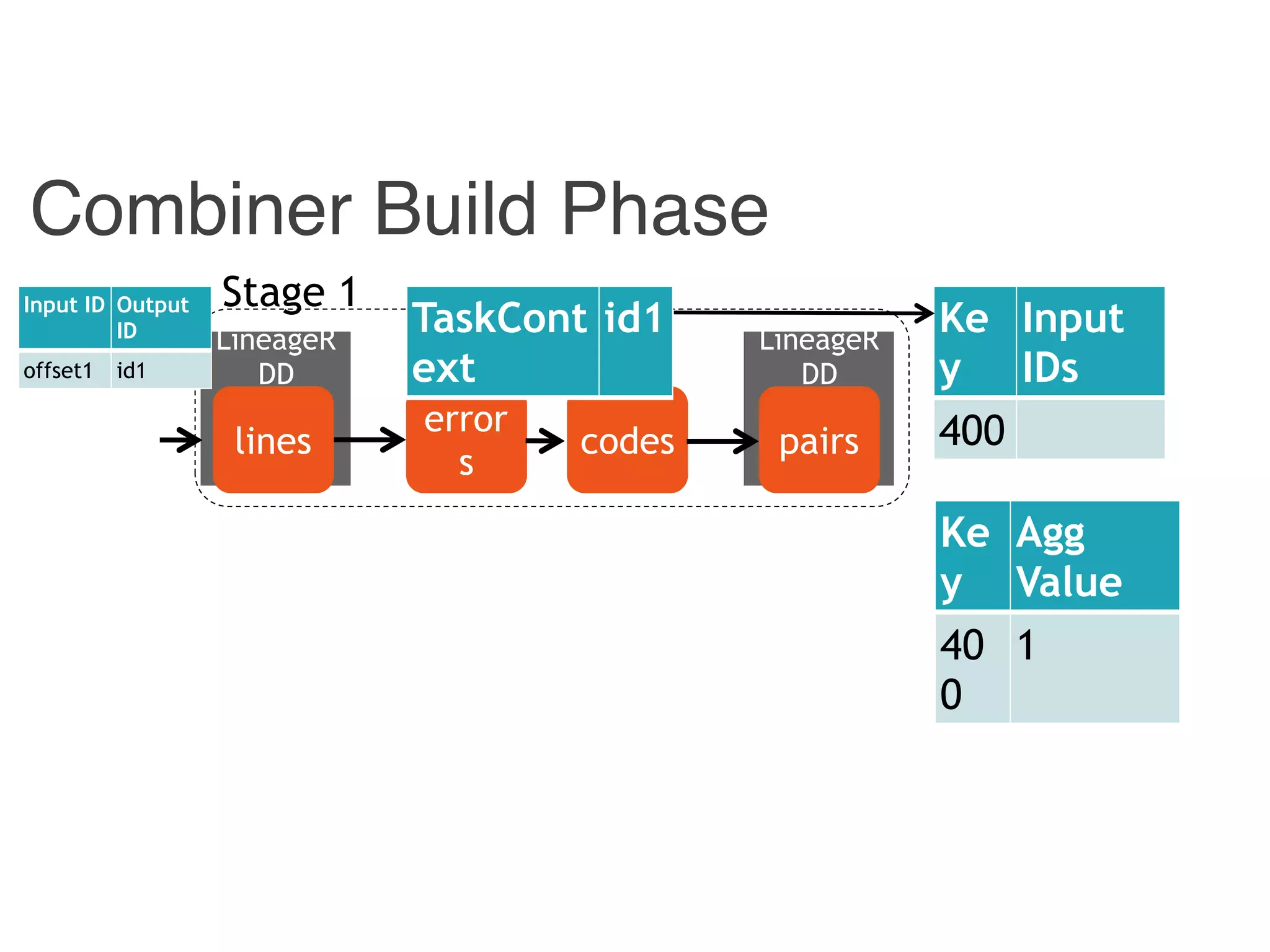
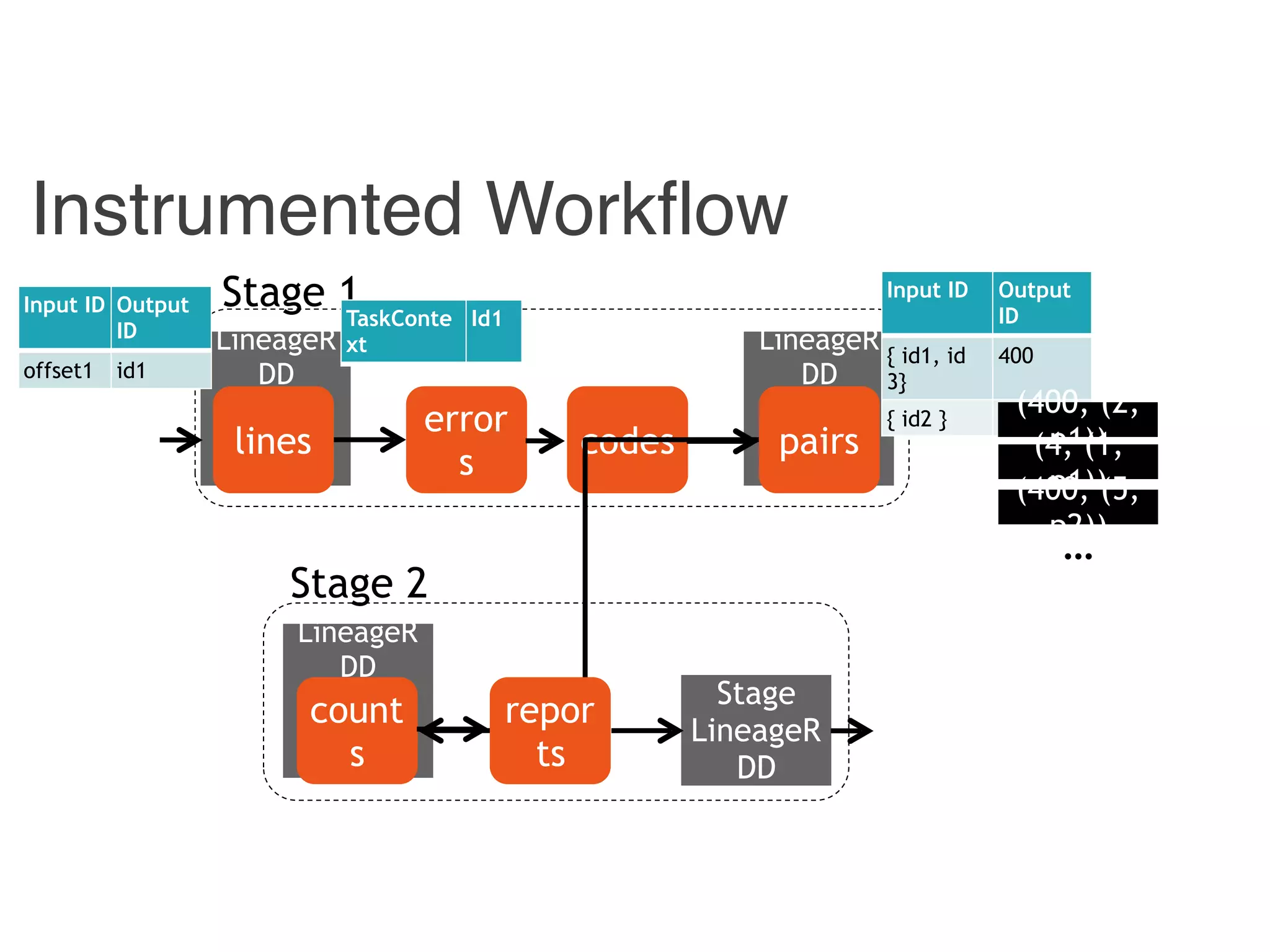
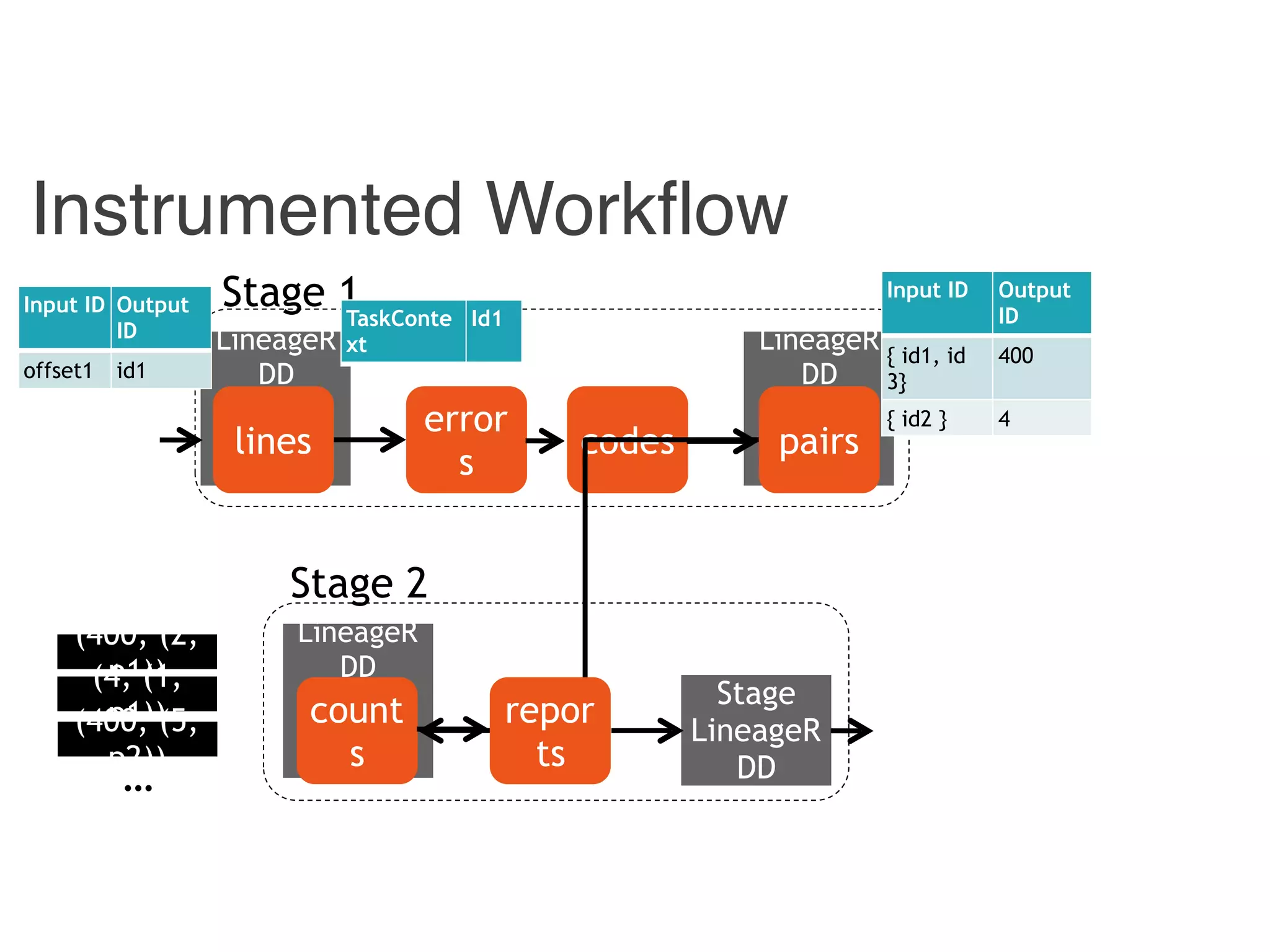
![Combiner
LineageR
DD
Reducer
LineageR
DD
Instrumented Workflow
Hadoop
LineageR
DD
count
s
pairscodes
error
s
lines
Stage 1
Stage 2
repor
ts
Stage
LineageR
DD
Input ID Output
ID
offset1 id1
TaskConte
xt
Id1
Input ID Output
ID
{ id1, id
3}
400
{ id2 } 4
(400, (2,
p1))(4, (1,
p1))(400, (5,
p2))
…
TaskConte
xt
400
Input ID Output
ID
[ p1, p2
]
400](https://image.slidesharecdn.com/jqbk7fectw6gyn2kl1iq-signature-6bd67fe616876e9dddc3901a12b0b9de049f8549e13f8c79d78ae3a0937d2490-poli-160812175915/75/Big-Data-Day-LA-2016-Hadoop-Spark-Kafka-track-Data-Provenance-Support-in-Spark-Matteo-Interlandi-PostDoc-UCLA-116-2048.jpg)
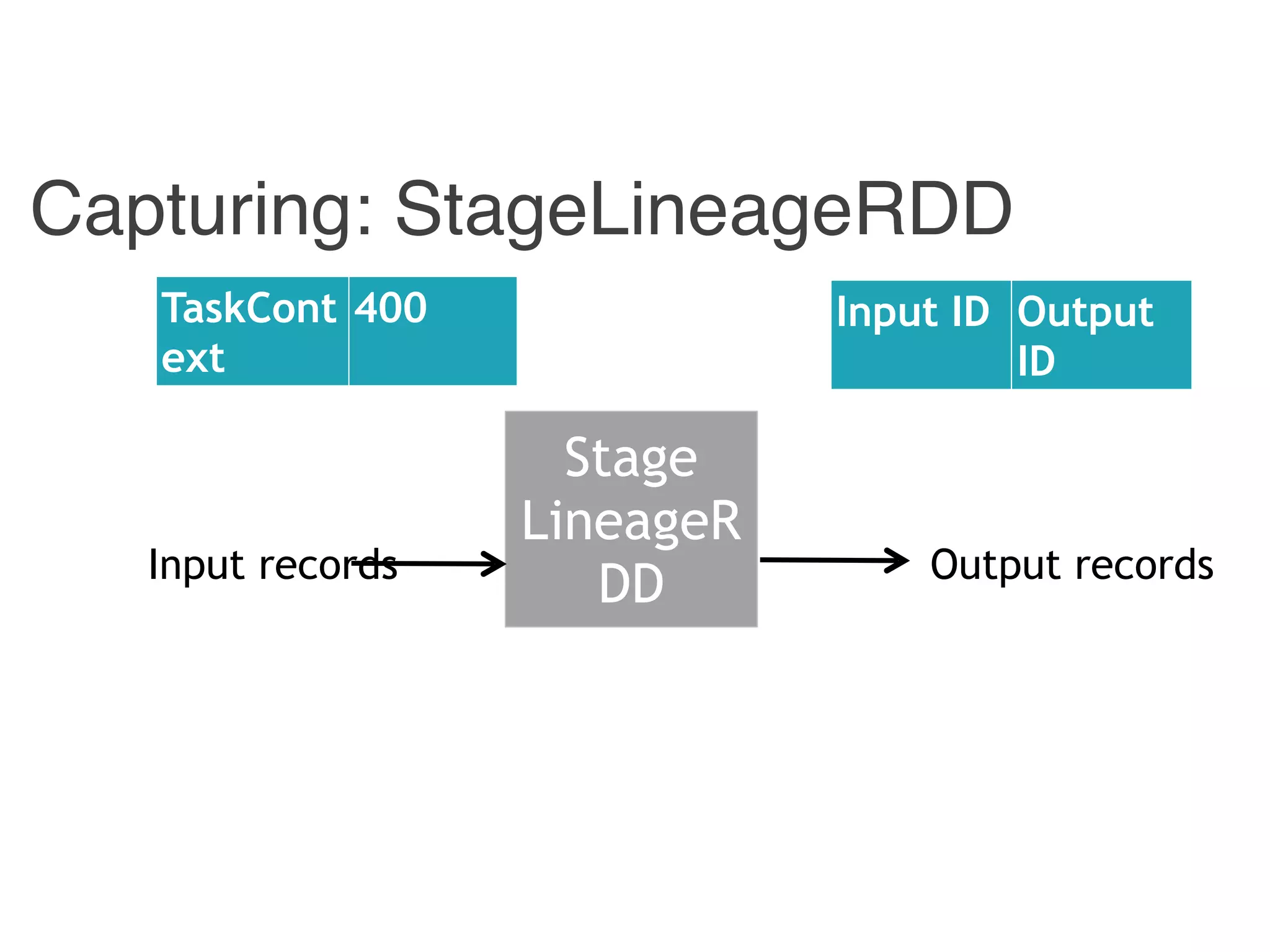
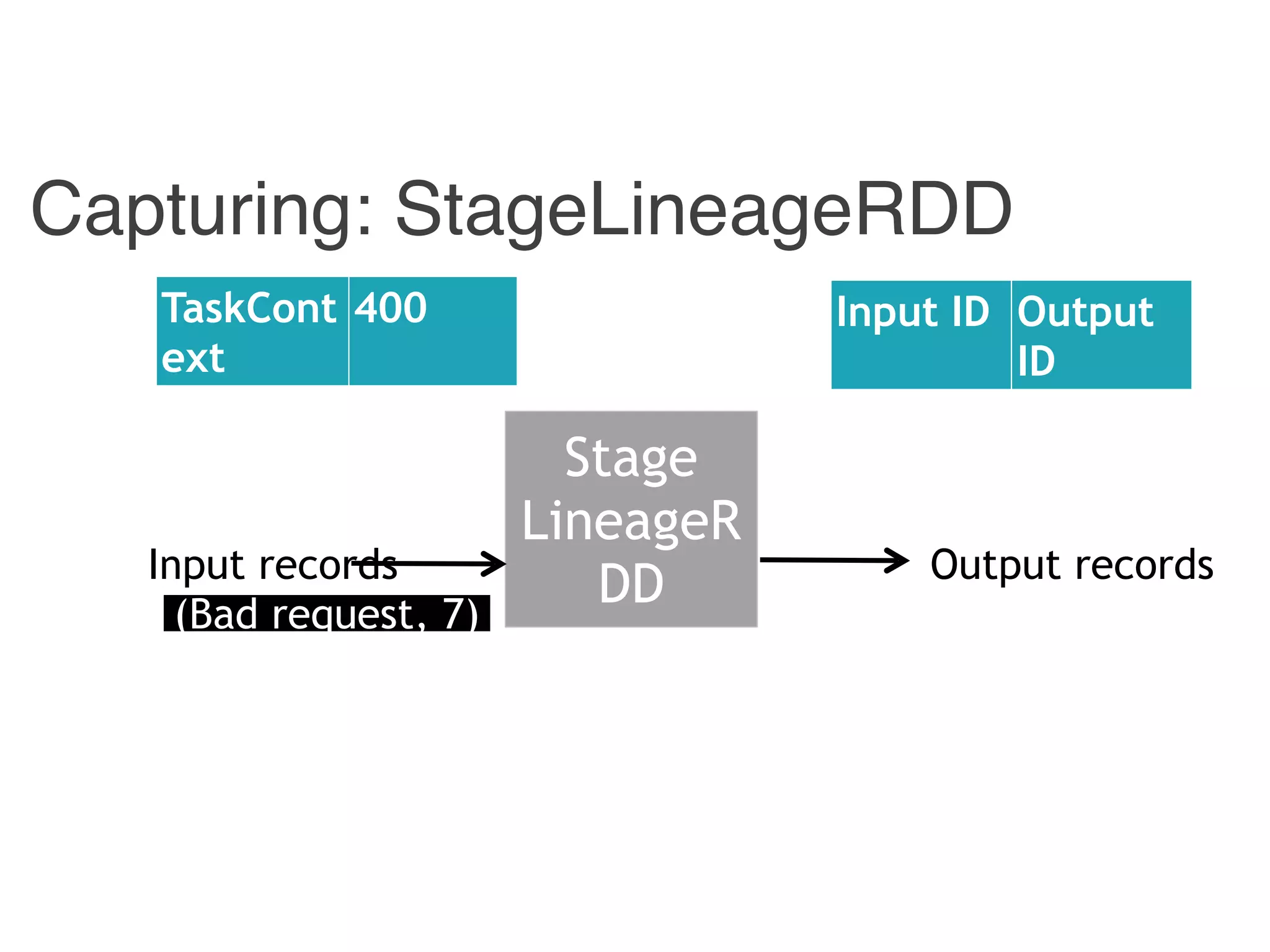
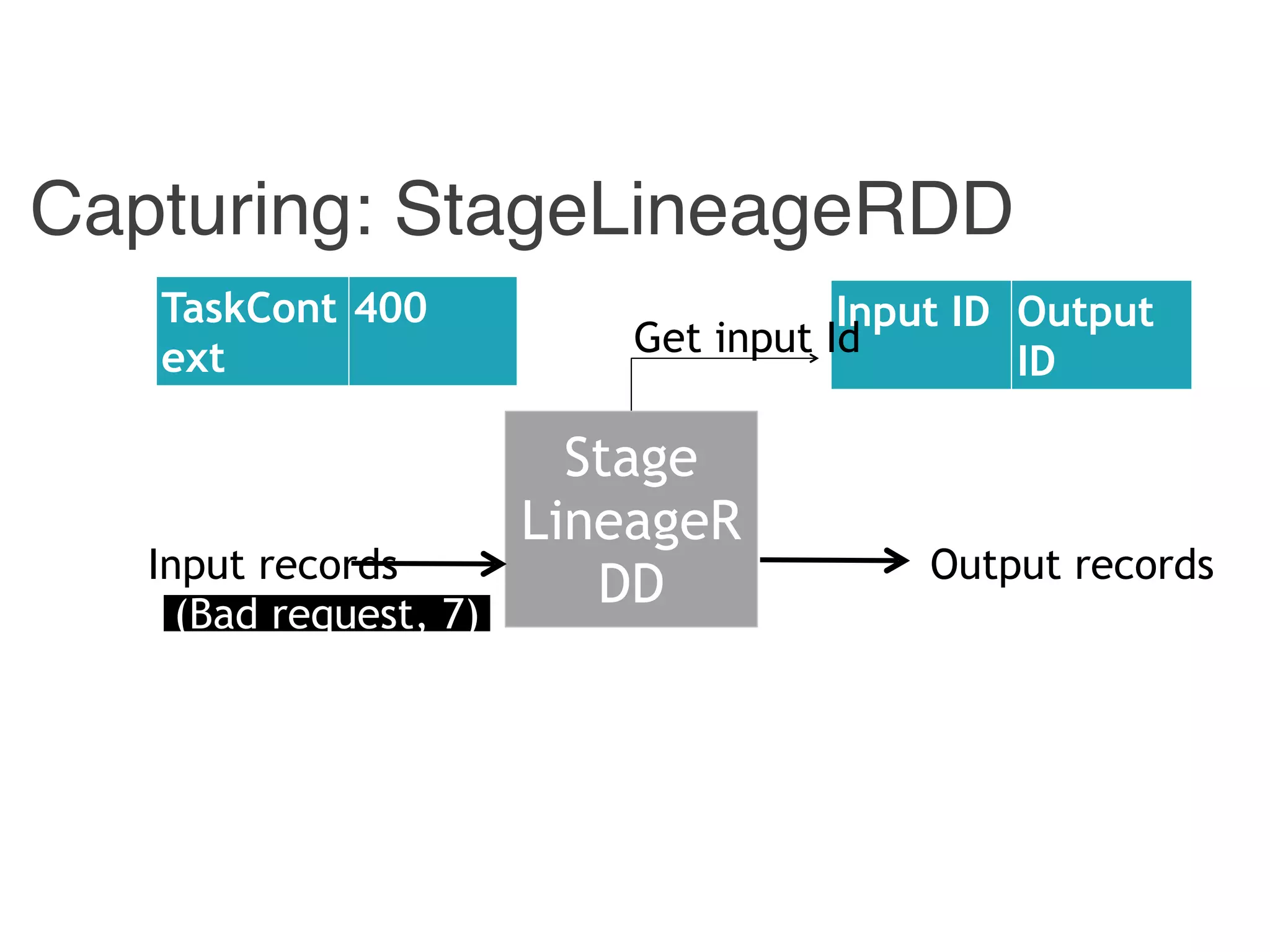
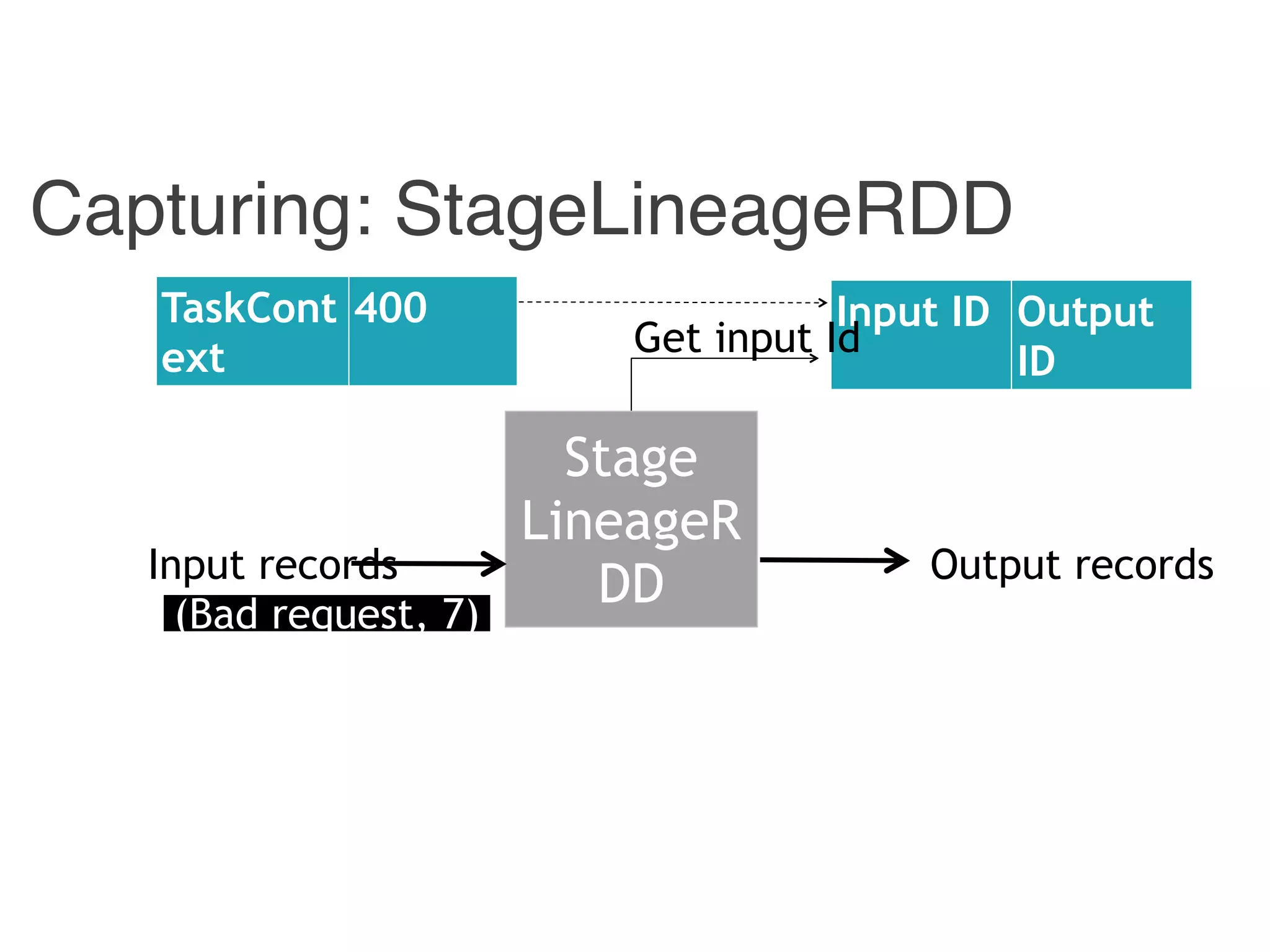
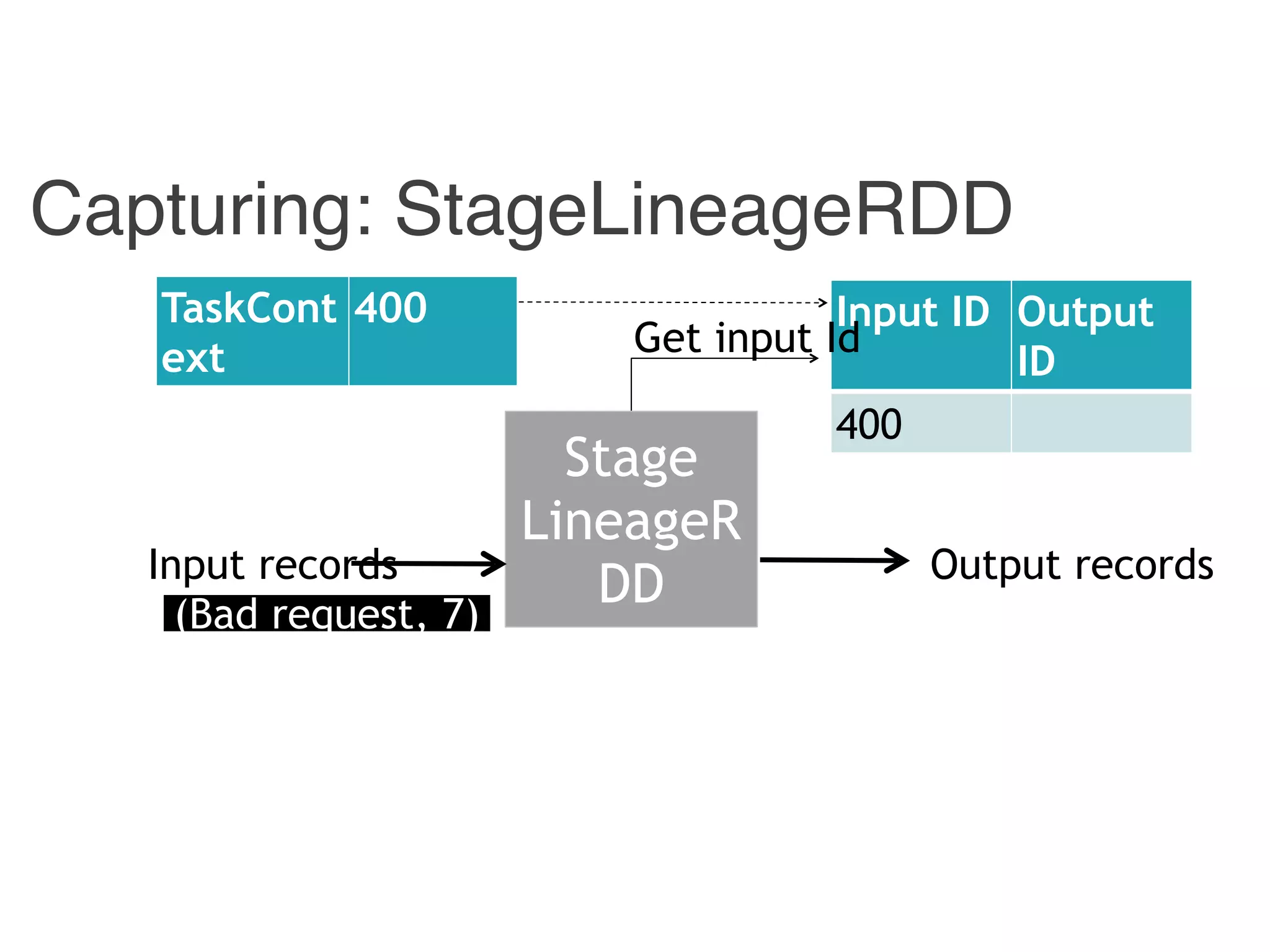
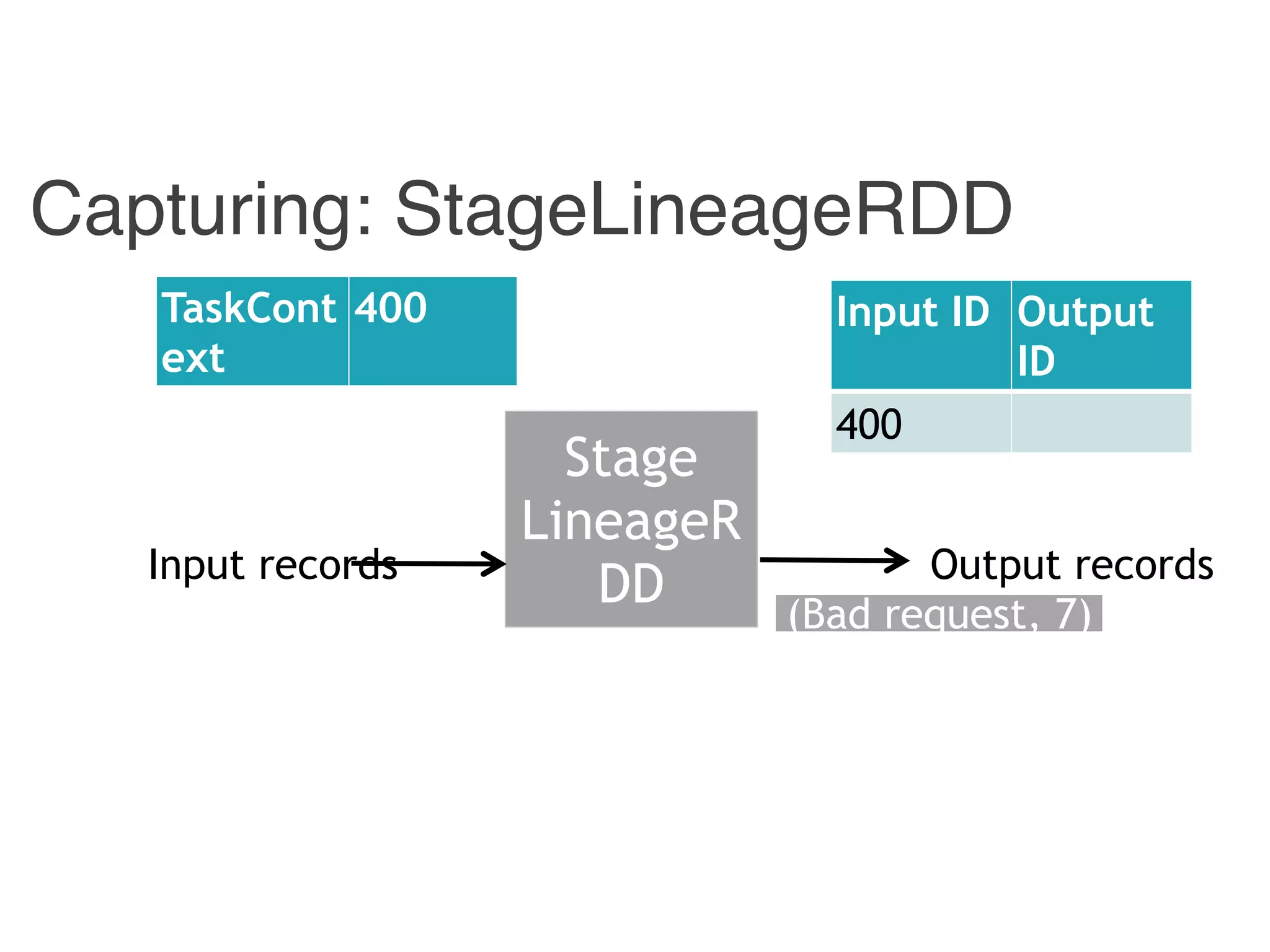

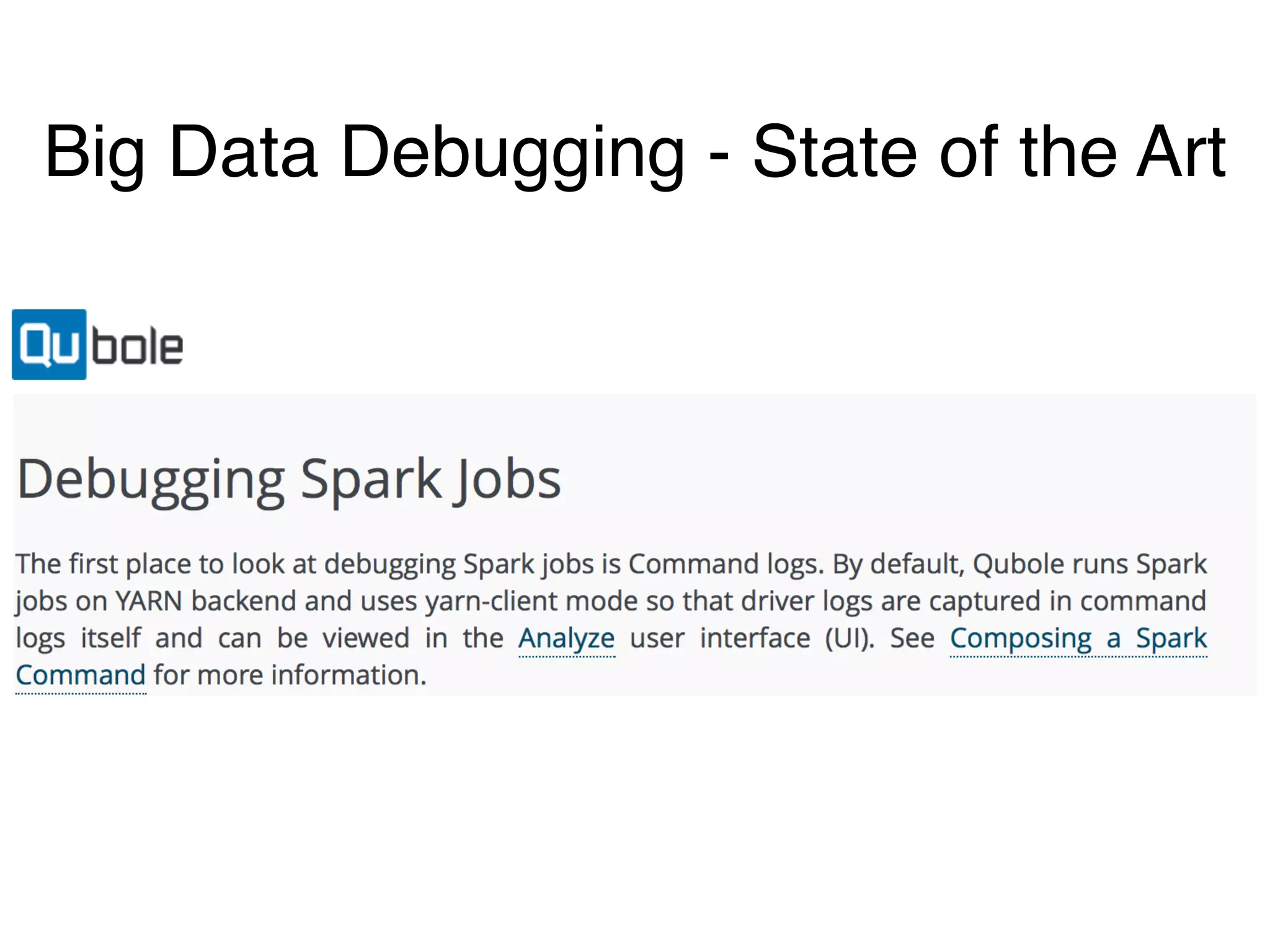
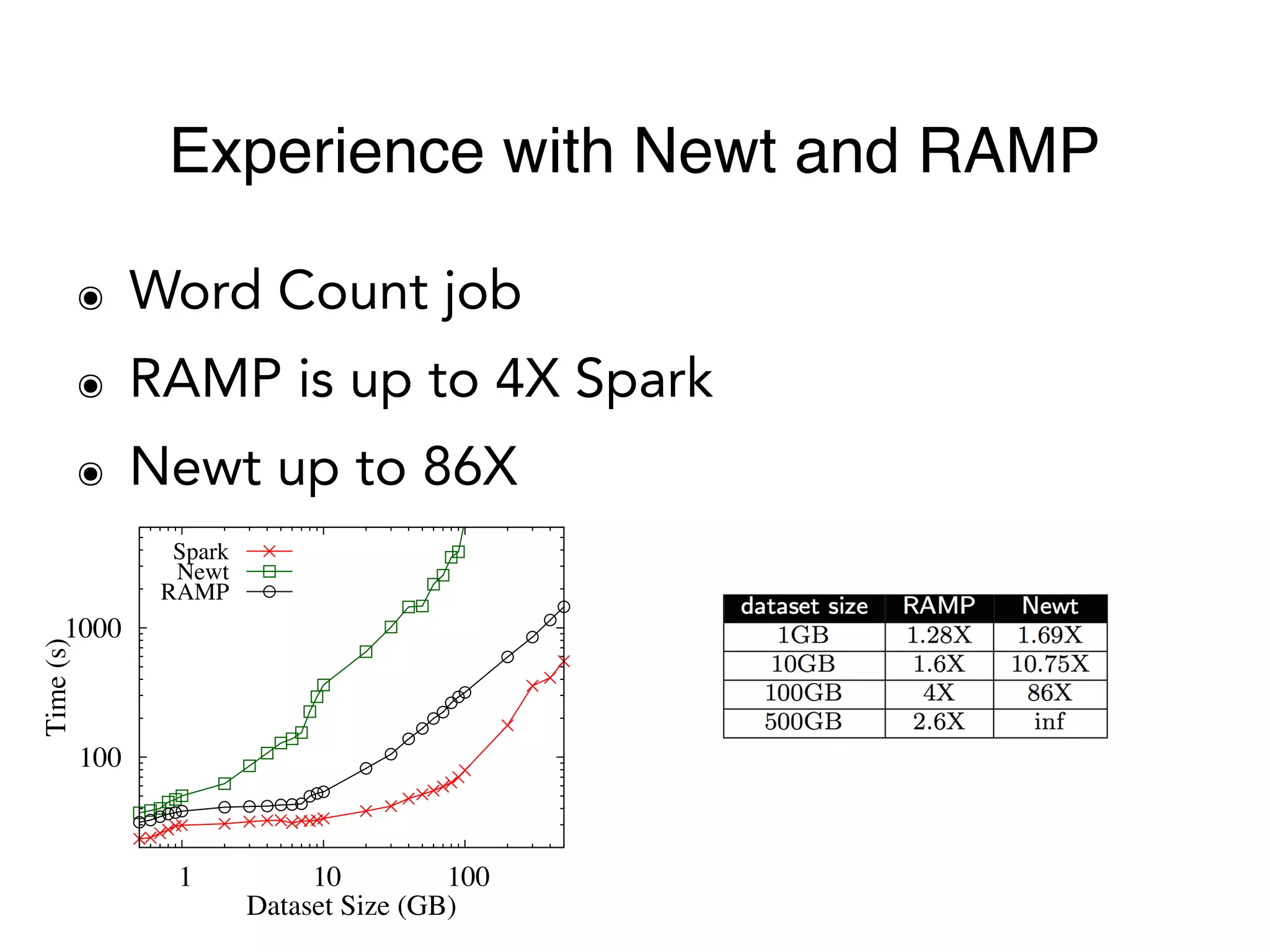
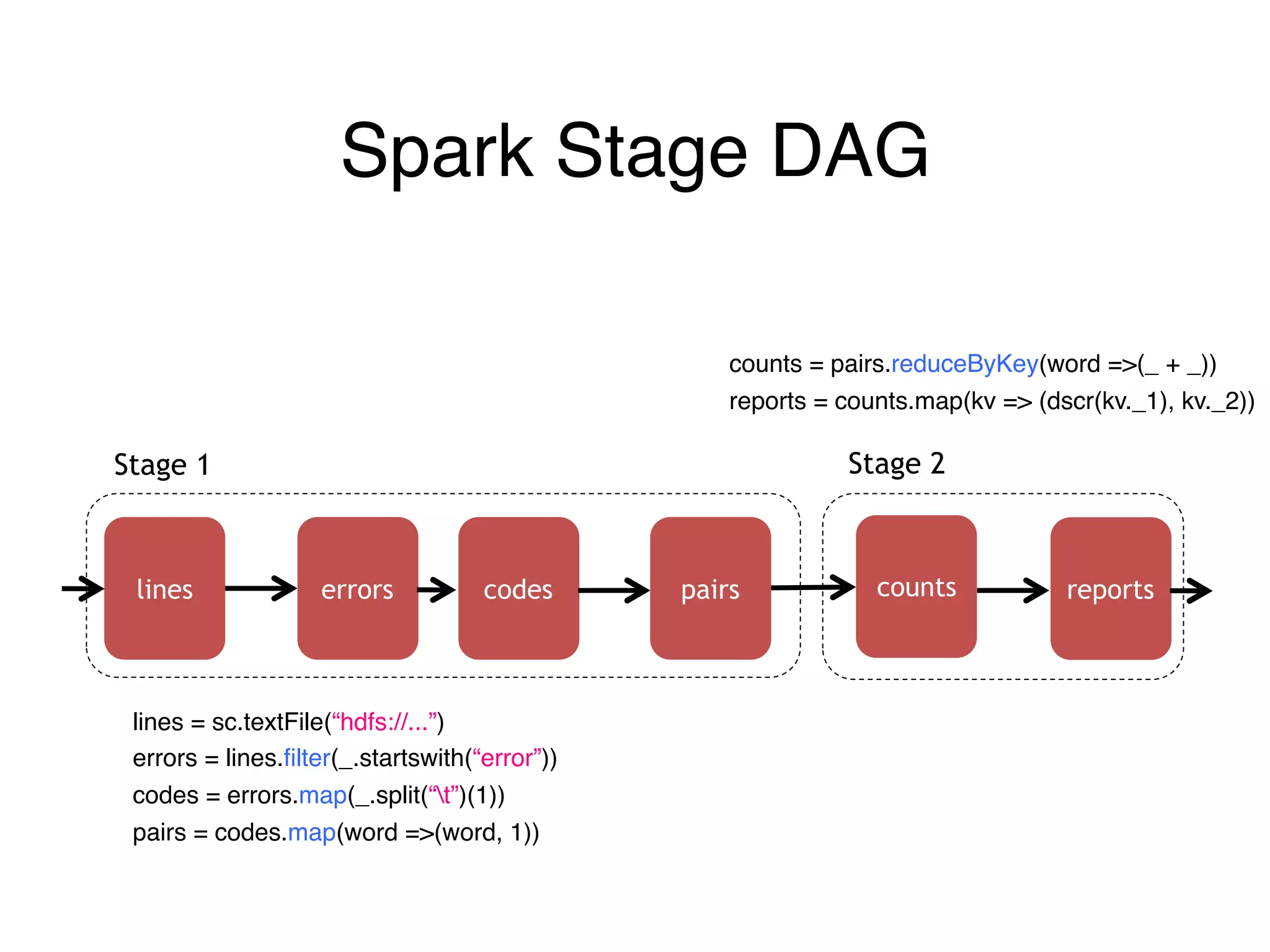
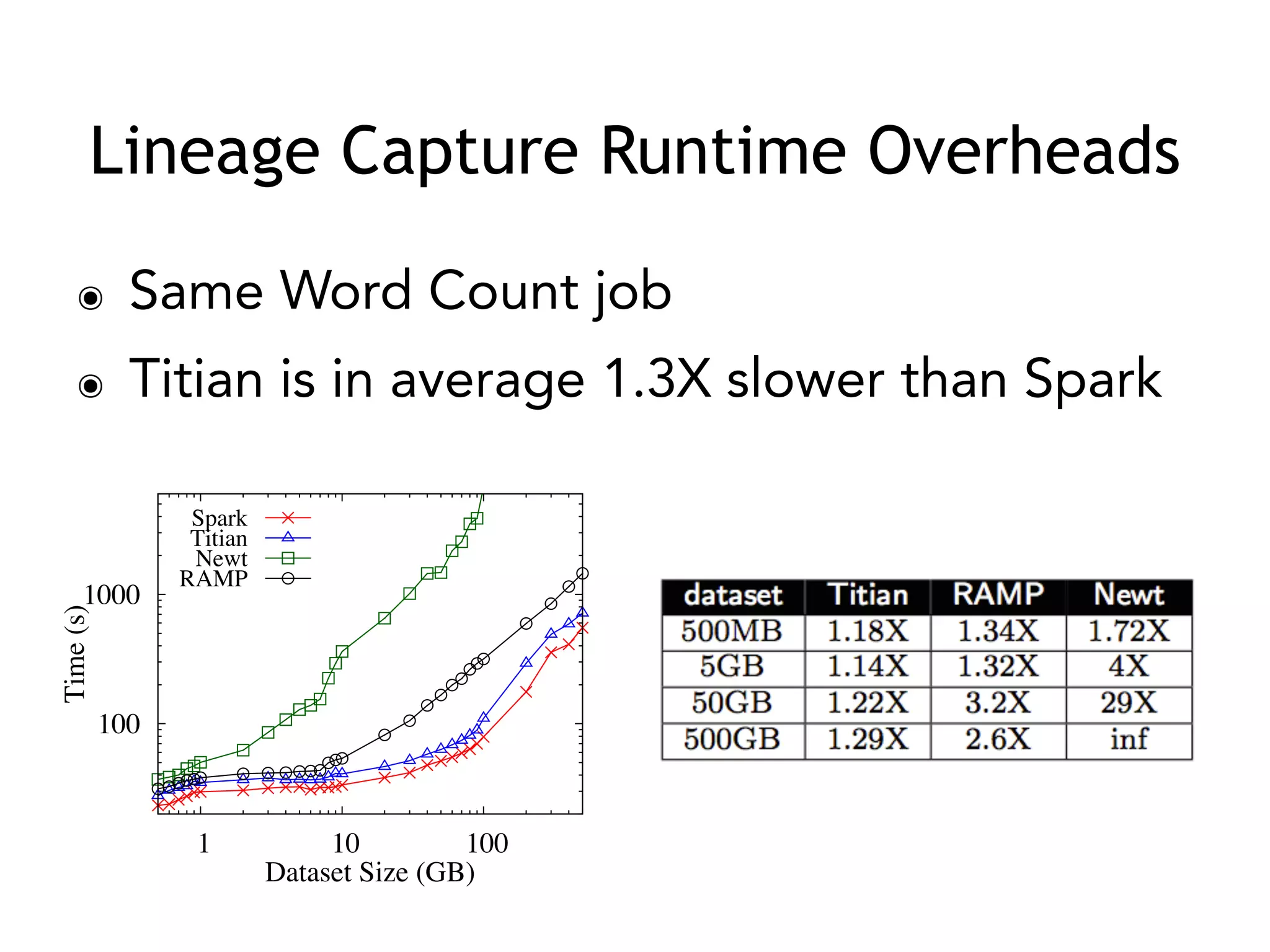
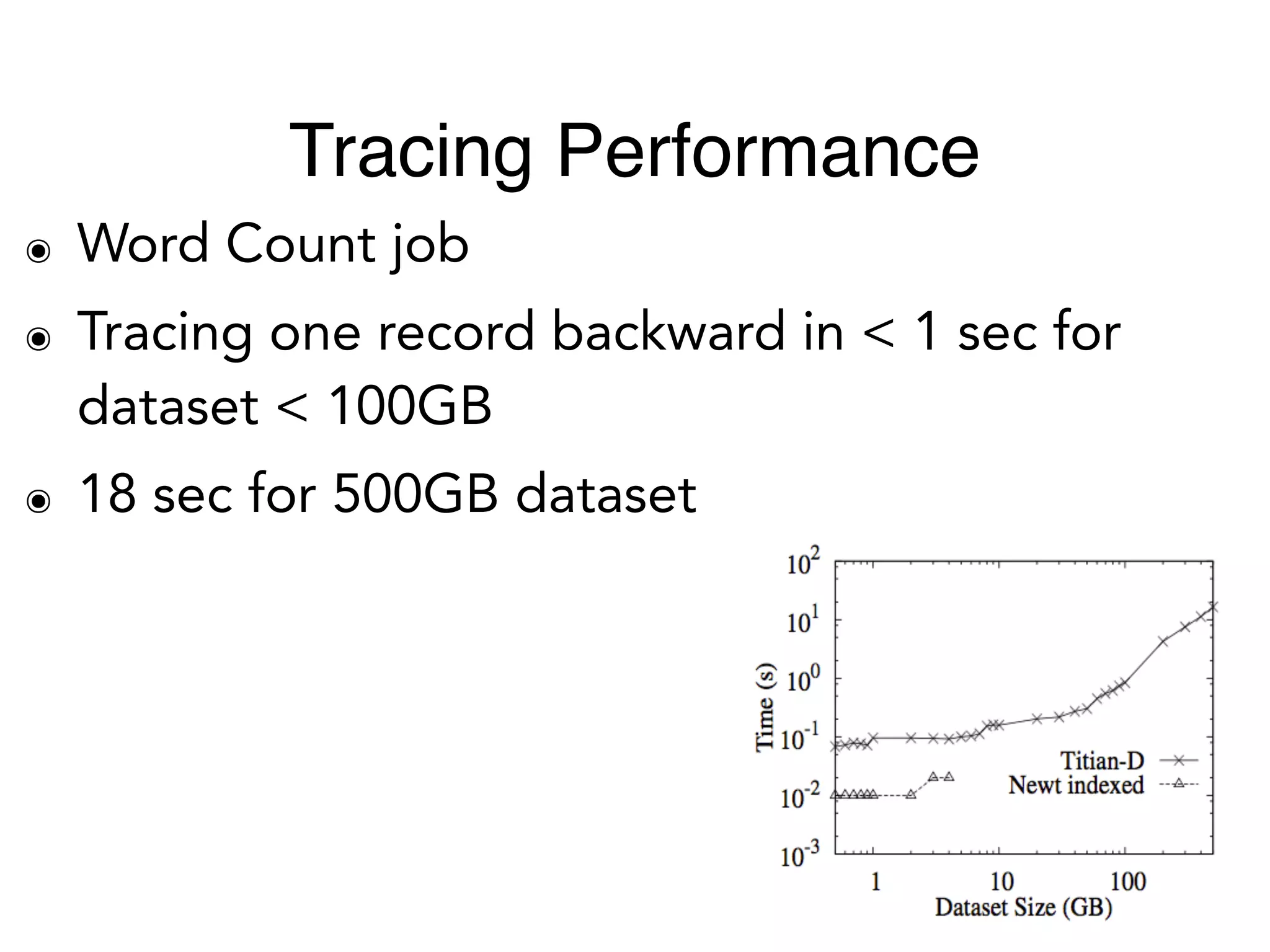
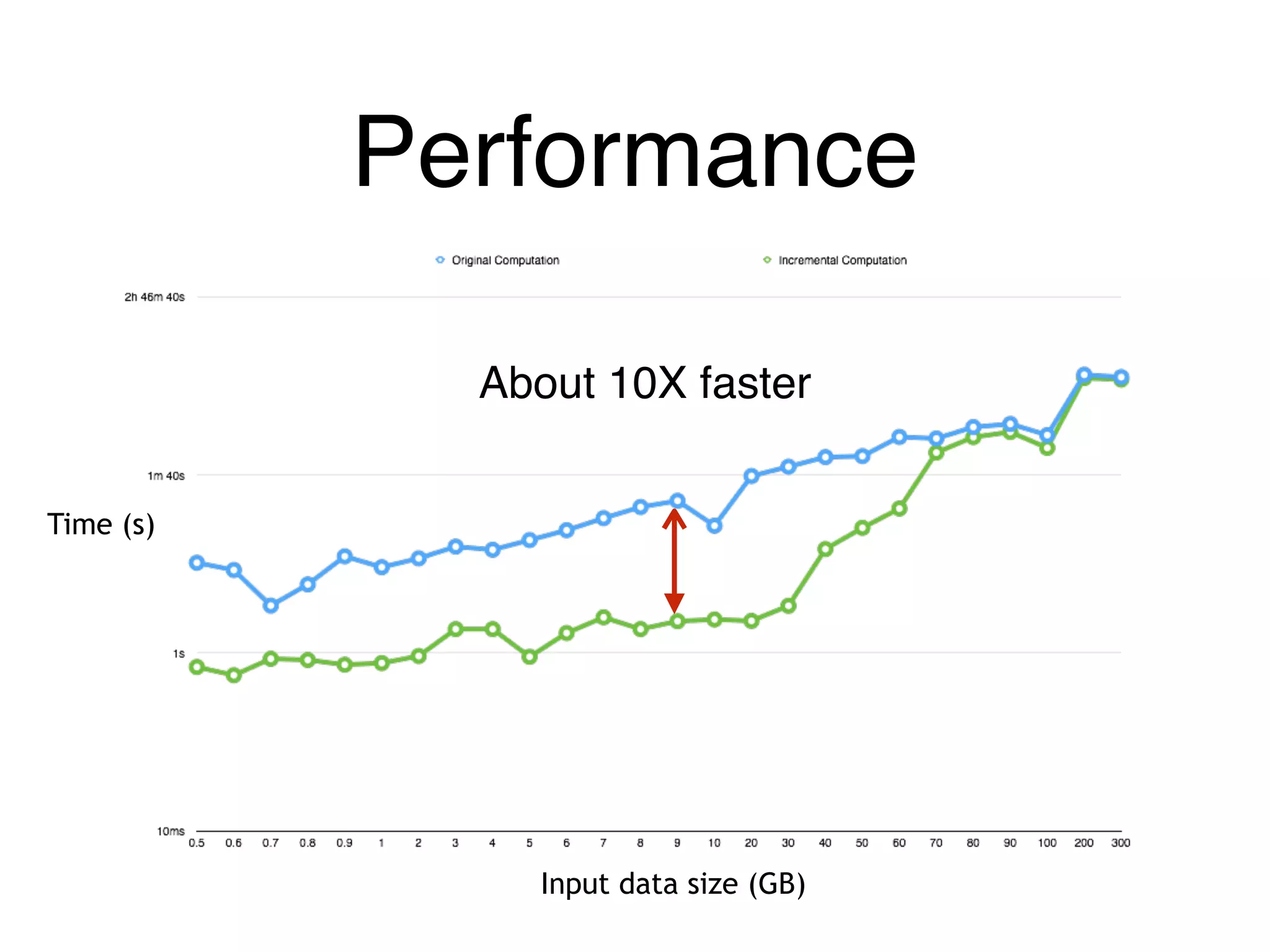
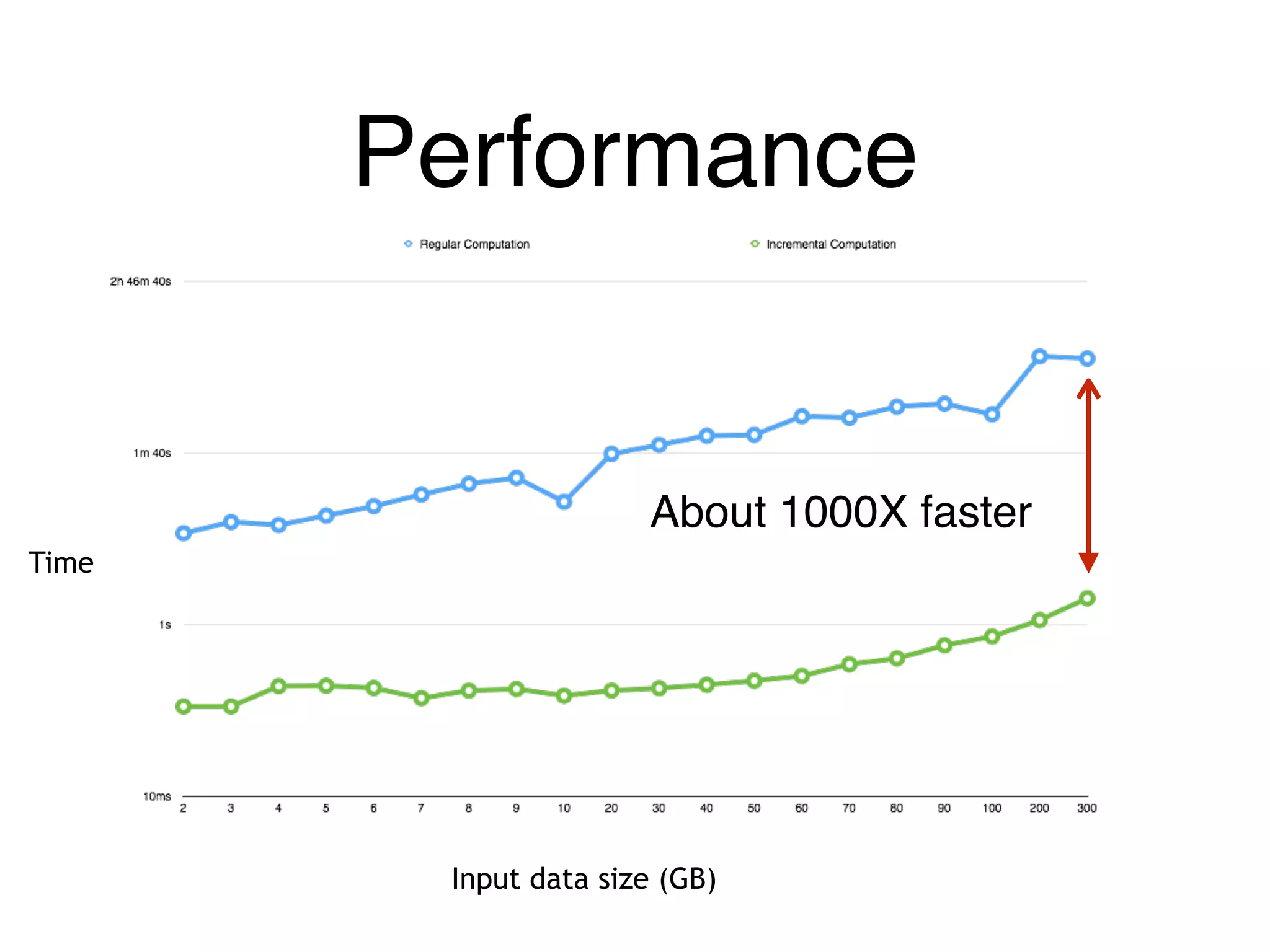
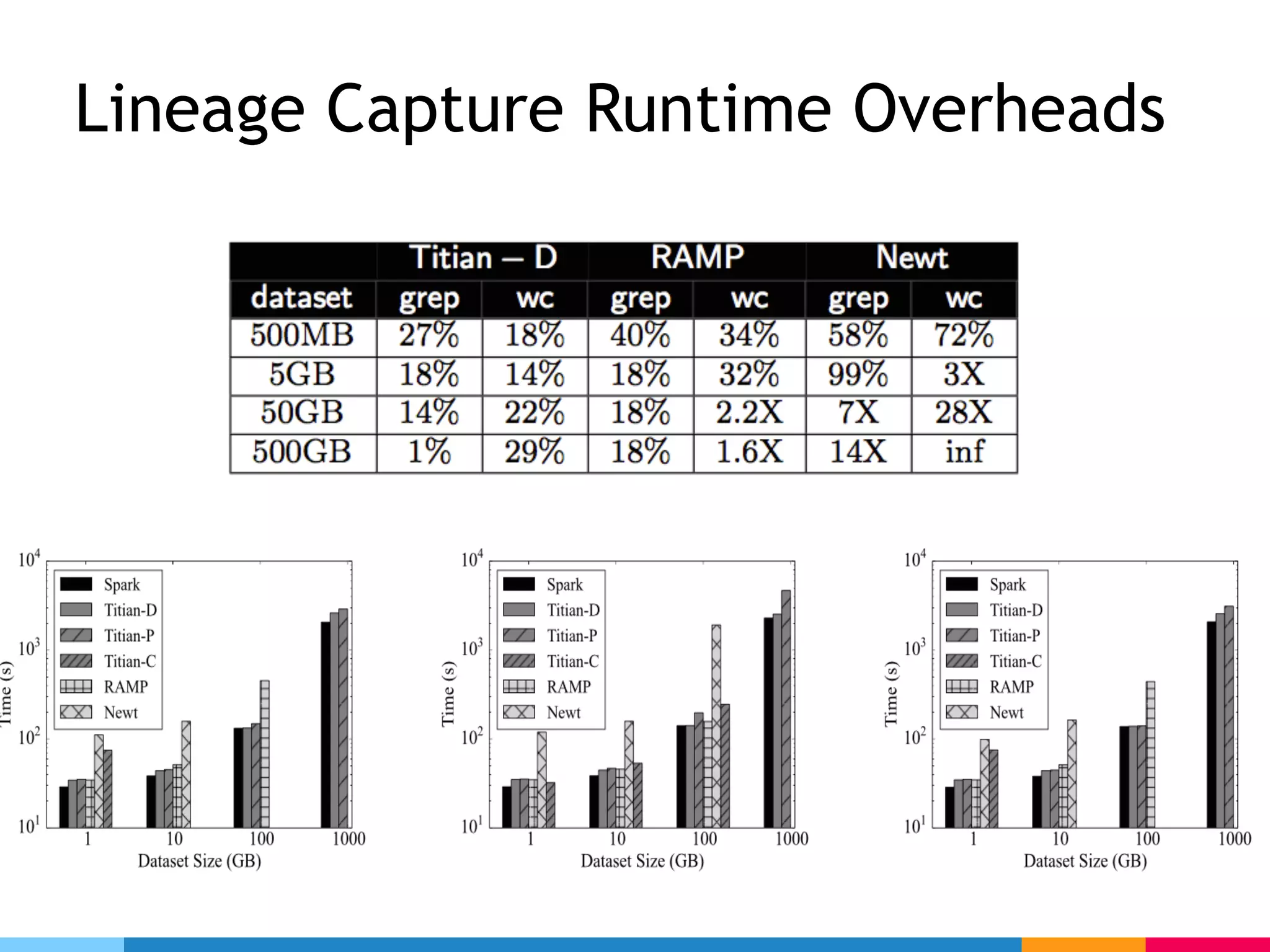
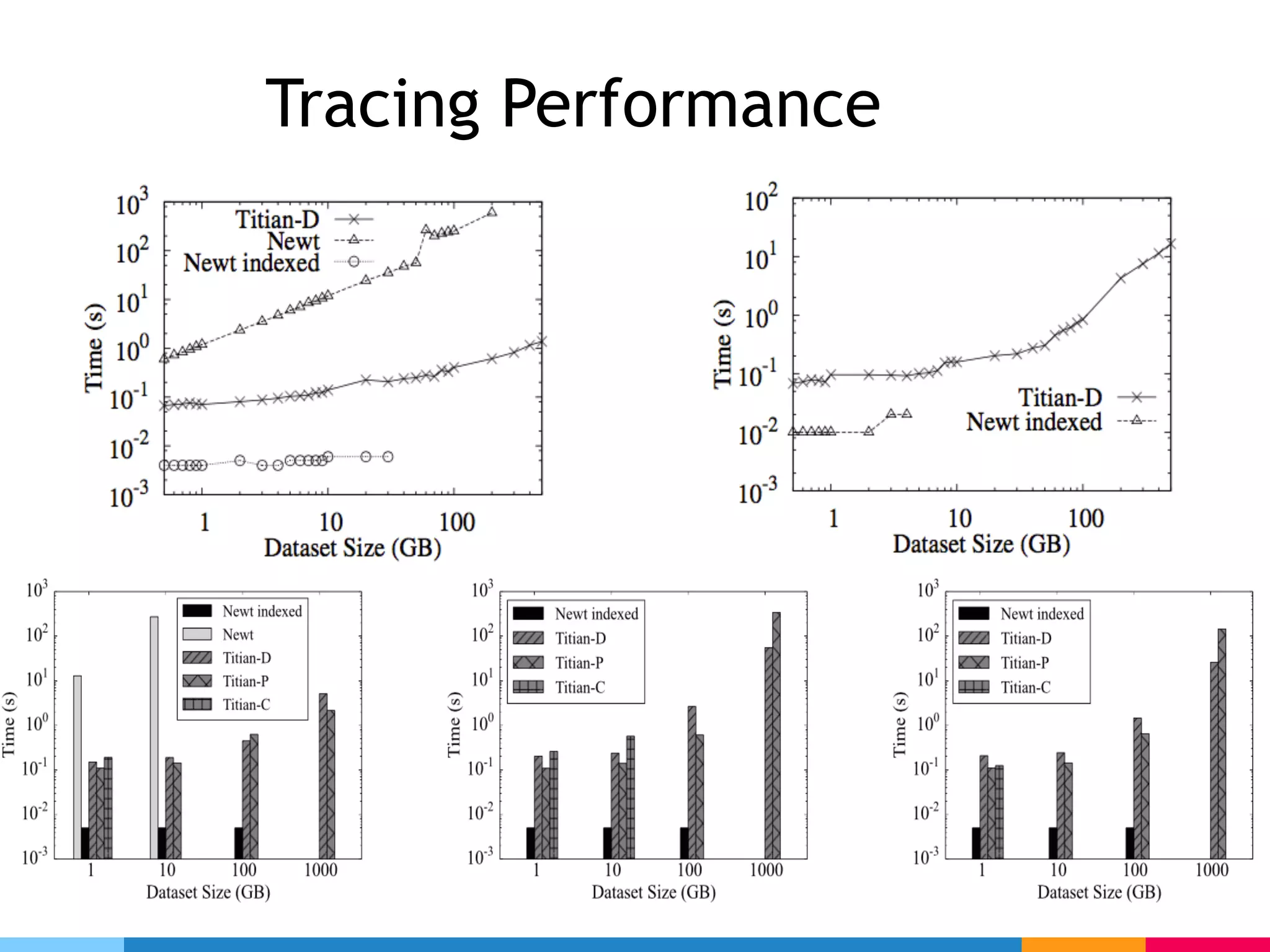
The document outlines challenges and solutions for debugging and developing interactive programs in Apache Spark, focusing on data provenance techniques like lineage tracking and selective replay of computations to improve visibility and interactivity in data-intensive scalable computing systems. It discusses the Titan programming interface and various examples of data processing workflows to demonstrate these debugging techniques. Additionally, it addresses the overhead of previous systems and emphasizes the need for optimized solutions in large-scale job contexts.











![[QE 2018] Łukasz Gawron – Testing Batch and Streaming Spark Applications](https://cdn.slidesharecdn.com/ss_thumbnails/gawrontestingbatchandstreamingsparkapplications-180702090002-thumbnail.jpg?width=640&height=640&fit=bounds)












































































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)








![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)





