Download as PDF, PPTX








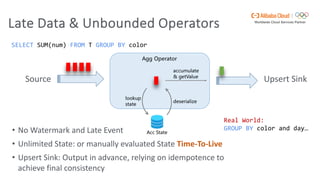
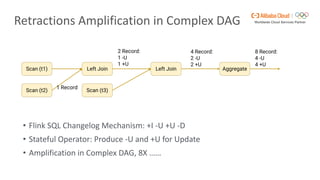

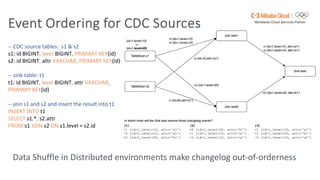
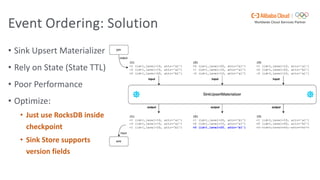
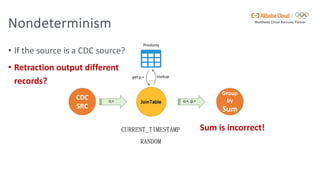
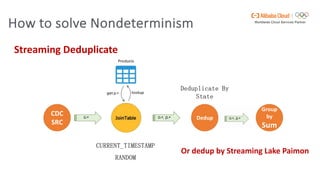

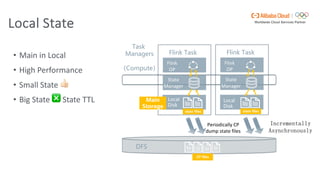
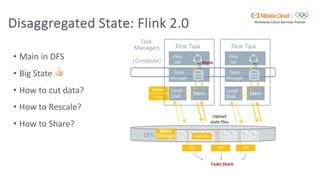
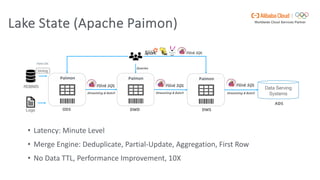




Flink SQL is Apache Flink's streaming SQL engine that supports data movement, data warehousing, and event-driven scenarios. There are four main challenges in building a streaming SQL engine: late data with unbounded operators, retractions amplification in complex query graphs, maintaining event ordering across distributed systems, and dealing with nondeterminism from functions like random and timestamps. The document discusses how Flink SQL addresses these challenges and the state and storage solutions in Flink, including using local state, disaggregated state in external storage, and the Apache Paimon lake storage format which can improve performance by 10x.

















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





