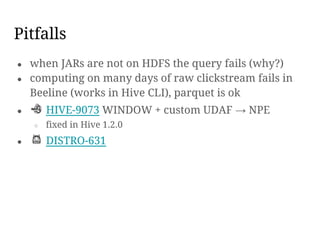
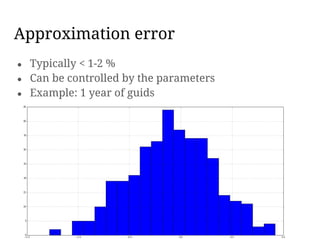
This document discusses using HyperLogLog (HLL) in Hive to efficiently estimate the number of unique elements or cardinality in big datasets. It describes how HLL provides fast approximate counting using probabilistic data structures. It covers implementing HLL as user-defined functions in Hive, comparing different open source implementations, and examples of using HLL to estimate unique visitors per day and in a rolling window.
















![Brickhouse – usage
ADD JAR /user/zamecnik/lib/brickhouse-0.7.1-15f5e8e.jar;
ADD JAR /user/zamecnik/lib/stream-2.3.0.jar;
CREATE TEMPORARY FUNCTION to_hll AS 'brickhouse.udf.hll.
HyperLogLogUDAF';
CREATE TEMPORARY FUNCTION union_hlls AS 'brickhouse.udf.
hll.UnionHyperLogLogUDAF';
CREATE TEMPORARY FUNCTION hll_approx_count AS 'brickhouse.
udf.hll.EstimateCardinalityUDF';
to_hll(value, [bit_precision])
● bit_precision: 4 to 16 (default 6)](https://image.slidesharecdn.com/hyperlogloginhive-efficientcountdistinct-160527103617/85/HyperLogLog-in-Hive-How-to-count-sheep-efficiently-17-320.jpg)

![We have to explicitly hash the value:
SELECT
hll_approx_count(to_hll(hll_hash(user_id)))
FROM events;
Options for creating HLL:
to_hll(x, [log2m, regwidth, expthresh, sparseon])
hardcoded to:
[log2m=11, regwidth=5, expthresh=-1, sparseon=true]
Hive-hll usage](https://image.slidesharecdn.com/hyperlogloginhive-efficientcountdistinct-160527103617/85/HyperLogLog-in-Hive-How-to-count-sheep-efficiently-19-320.jpg)






![Linear counter
m = 20 # size of the register
register = bitarray(m) # register, m bits
def add(value):
h = mmh3.hash(value) % m # select bit index
register[h] = 1 # = max(1, register[h])
def cardinality():
u_n = register.count(0) # number of zeros
v_n = u_n / m # relative number of zeros
n_hat = -m * math.log(v_n) # estimate of the set cardinality
return n_hat](https://image.slidesharecdn.com/hyperlogloginhive-efficientcountdistinct-160527103617/85/HyperLogLog-in-Hive-How-to-count-sheep-efficiently-28-320.jpg)







































![Анализ количества посетителей на сайте [Считаем уникальные элементы]](https://cdn.slidesharecdn.com/ss_thumbnails/schitaemunikalnyeehlementy-170110075909-thumbnail.jpg?width=640&height=640&fit=bounds)









































