Download to read offline





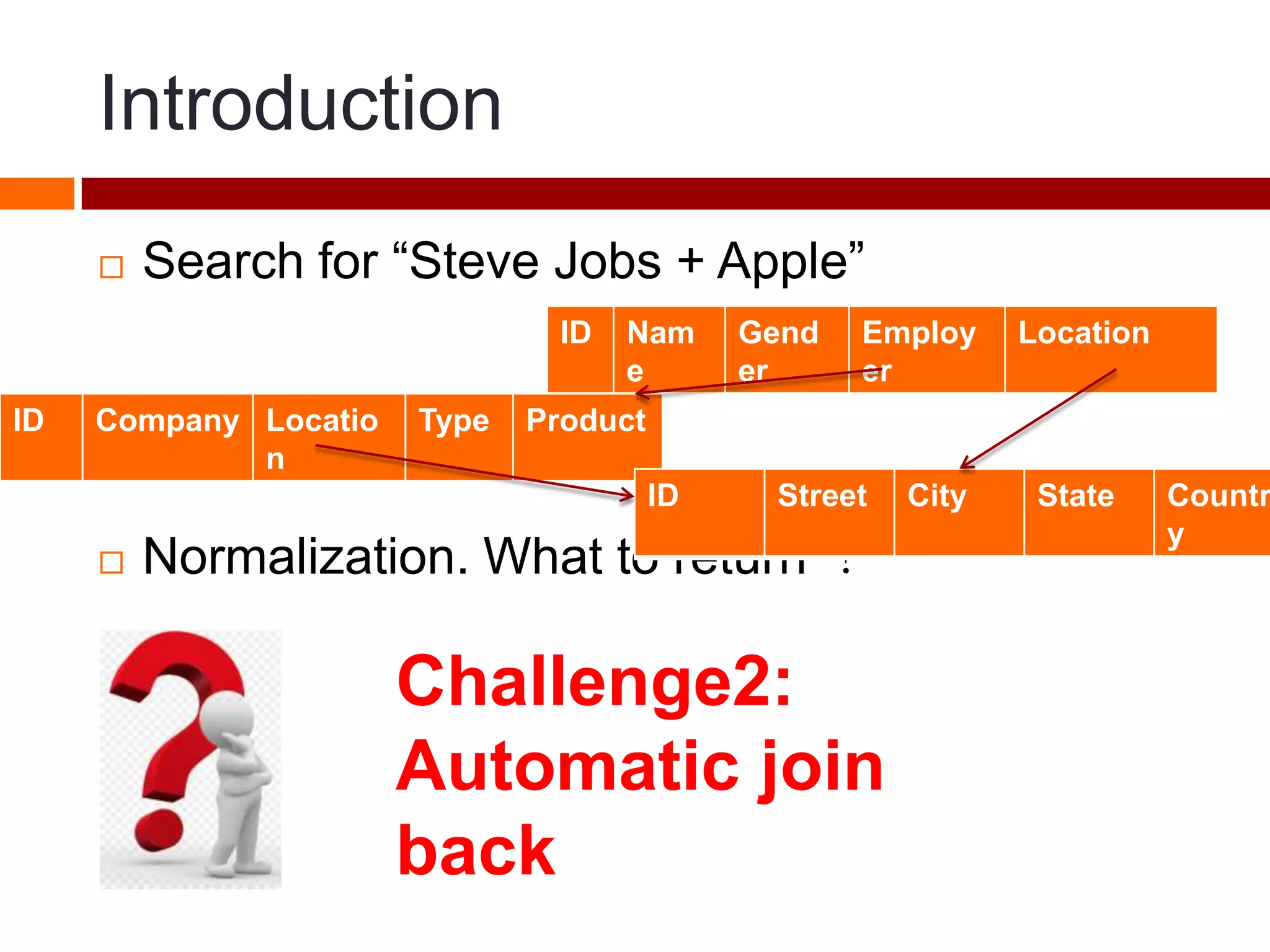







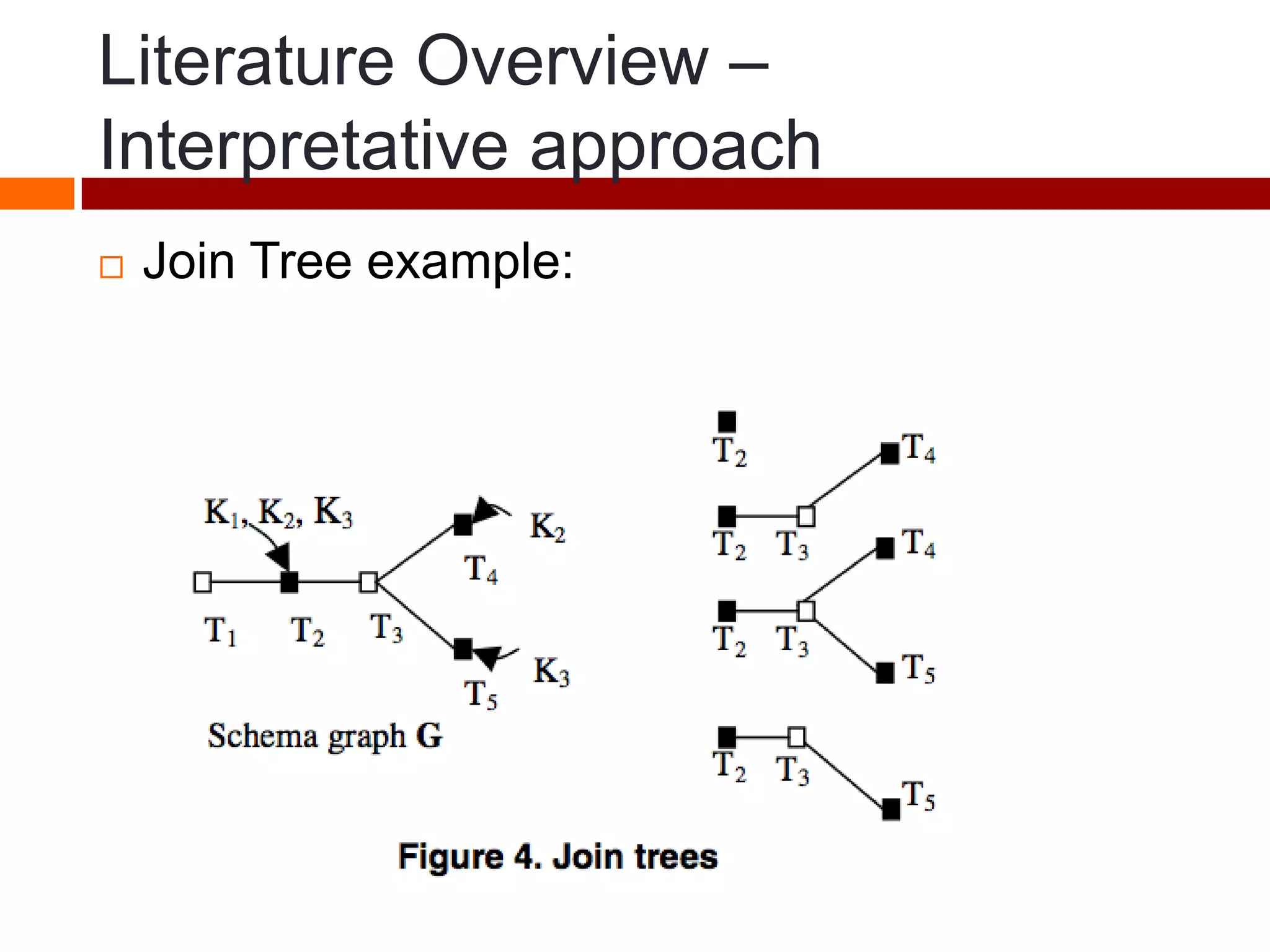


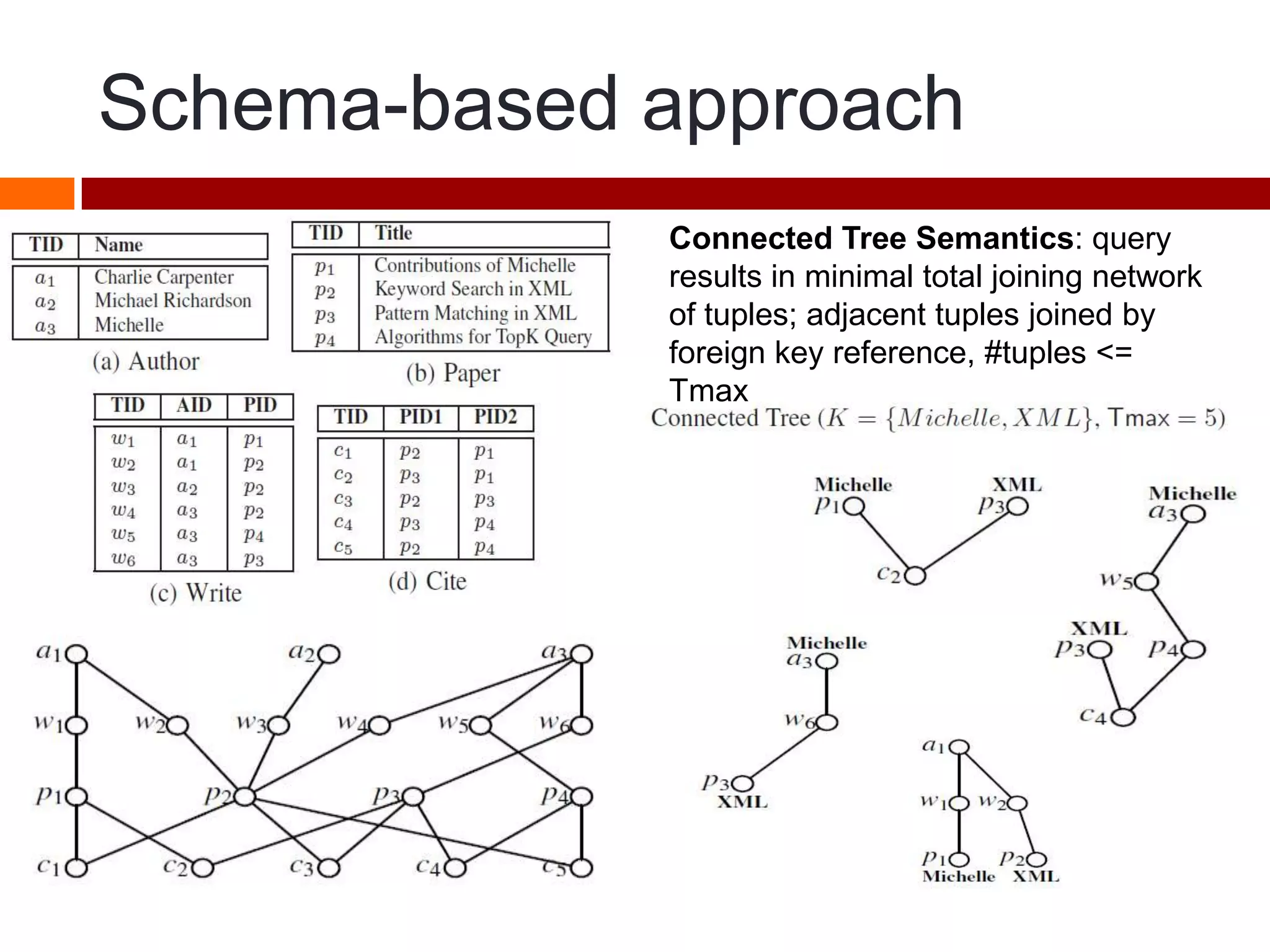

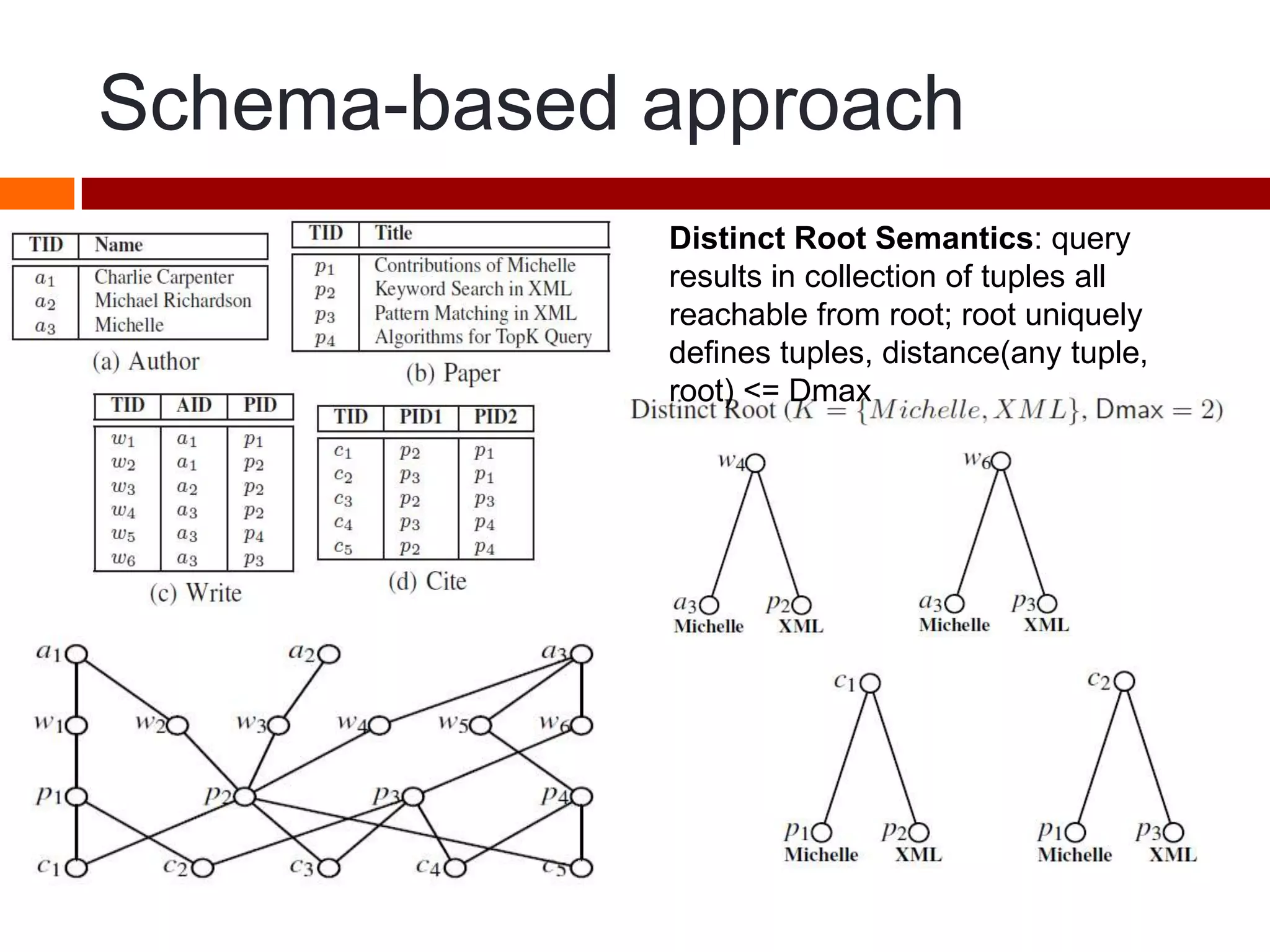
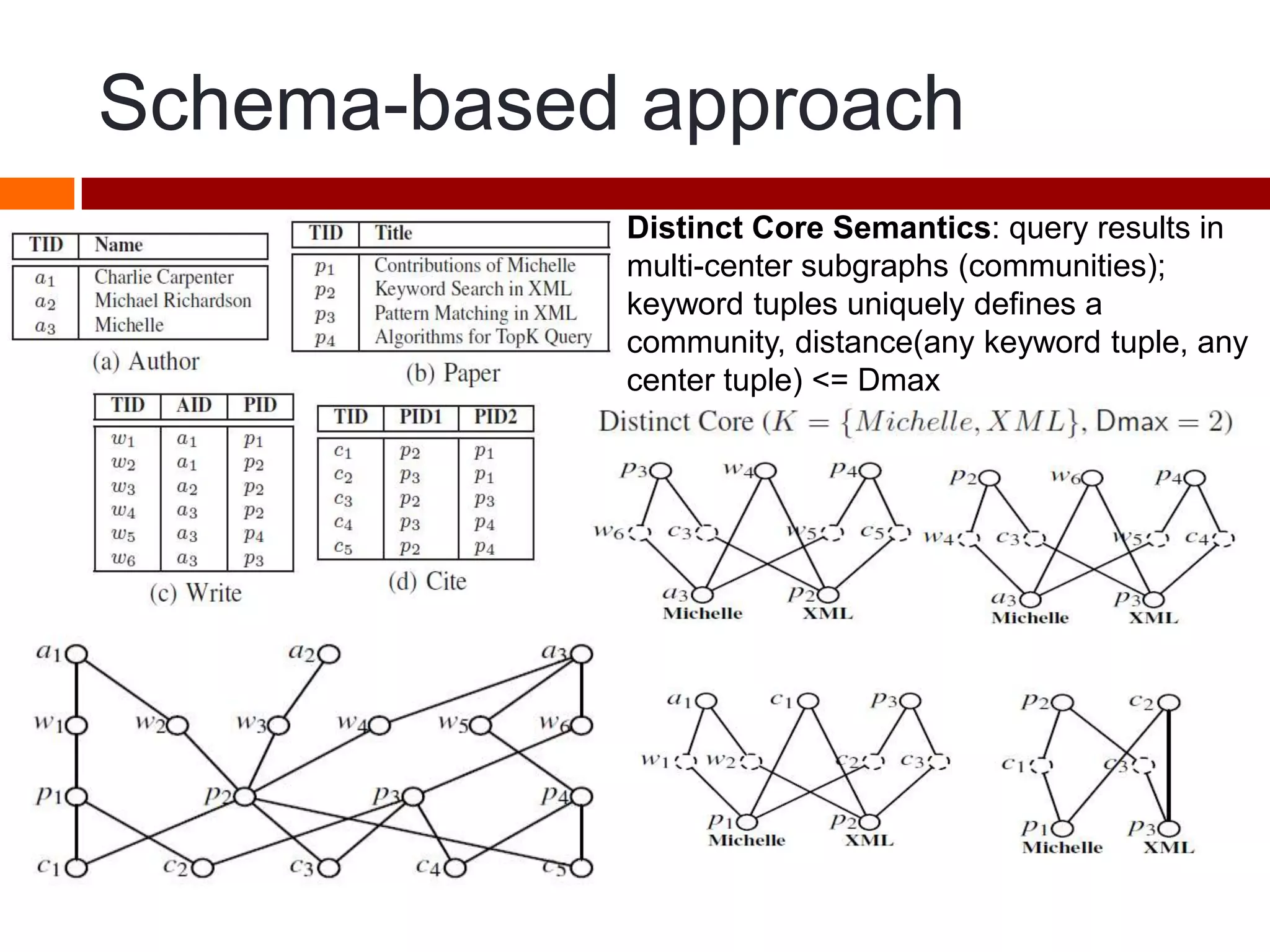




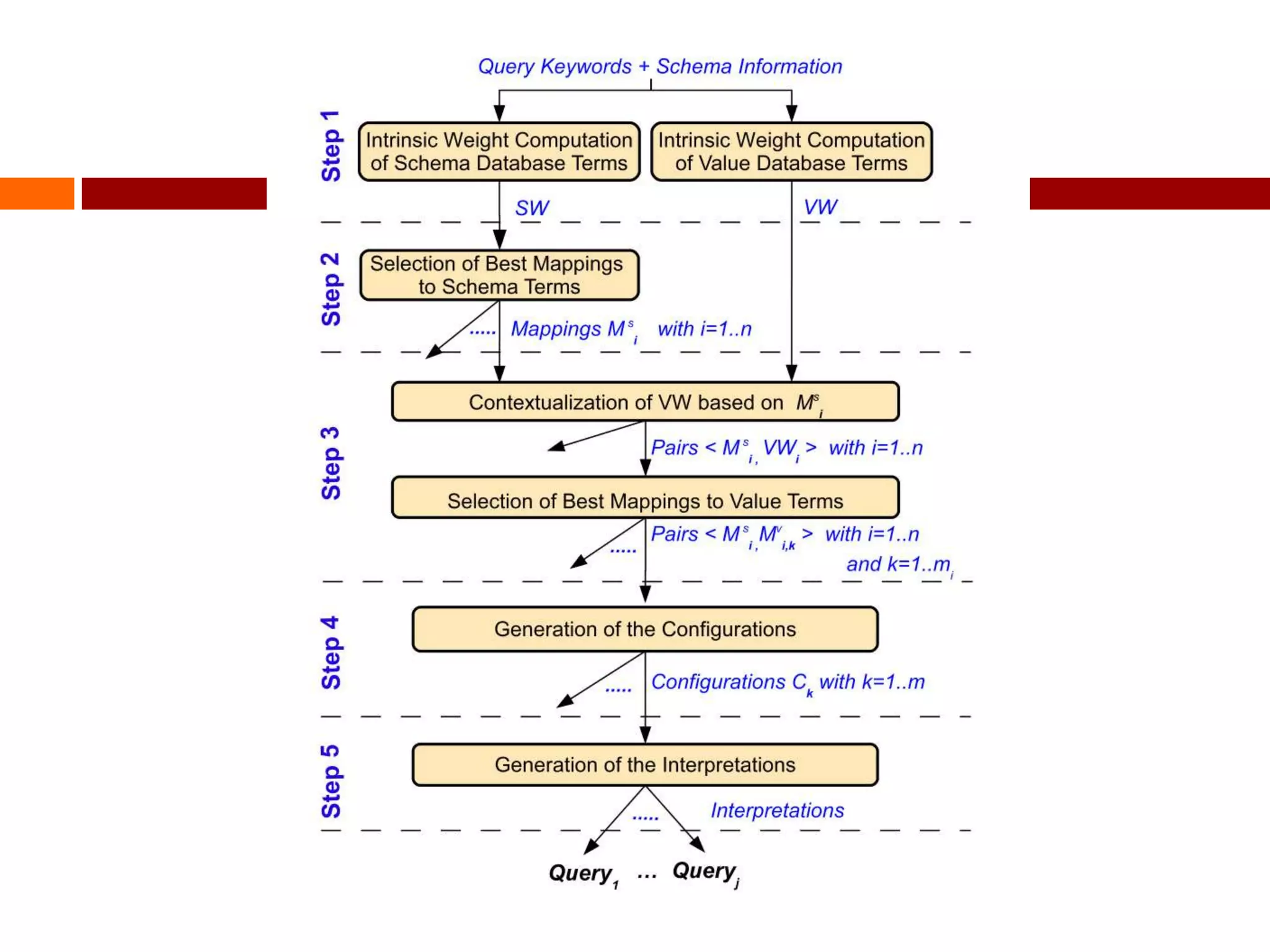




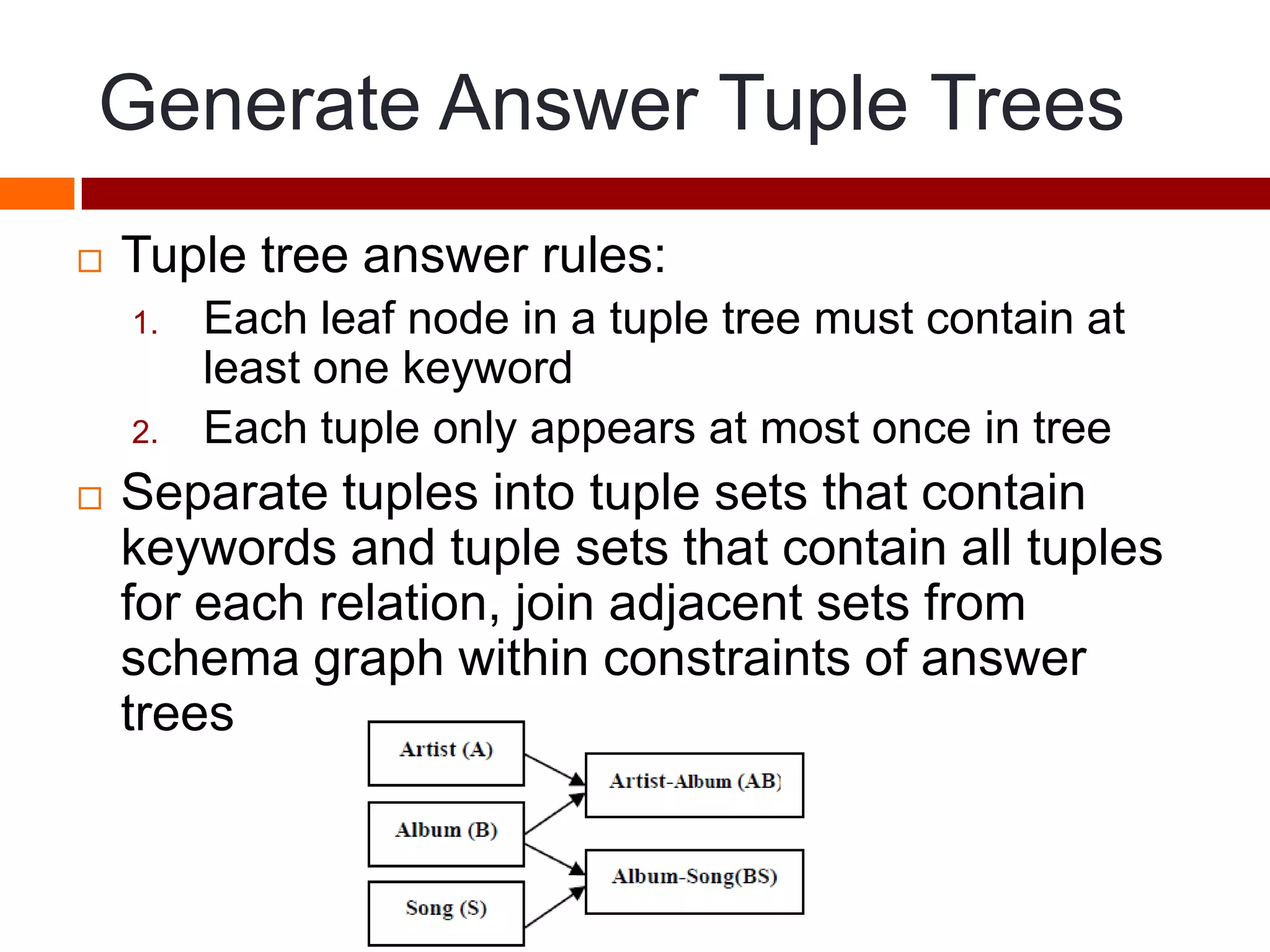


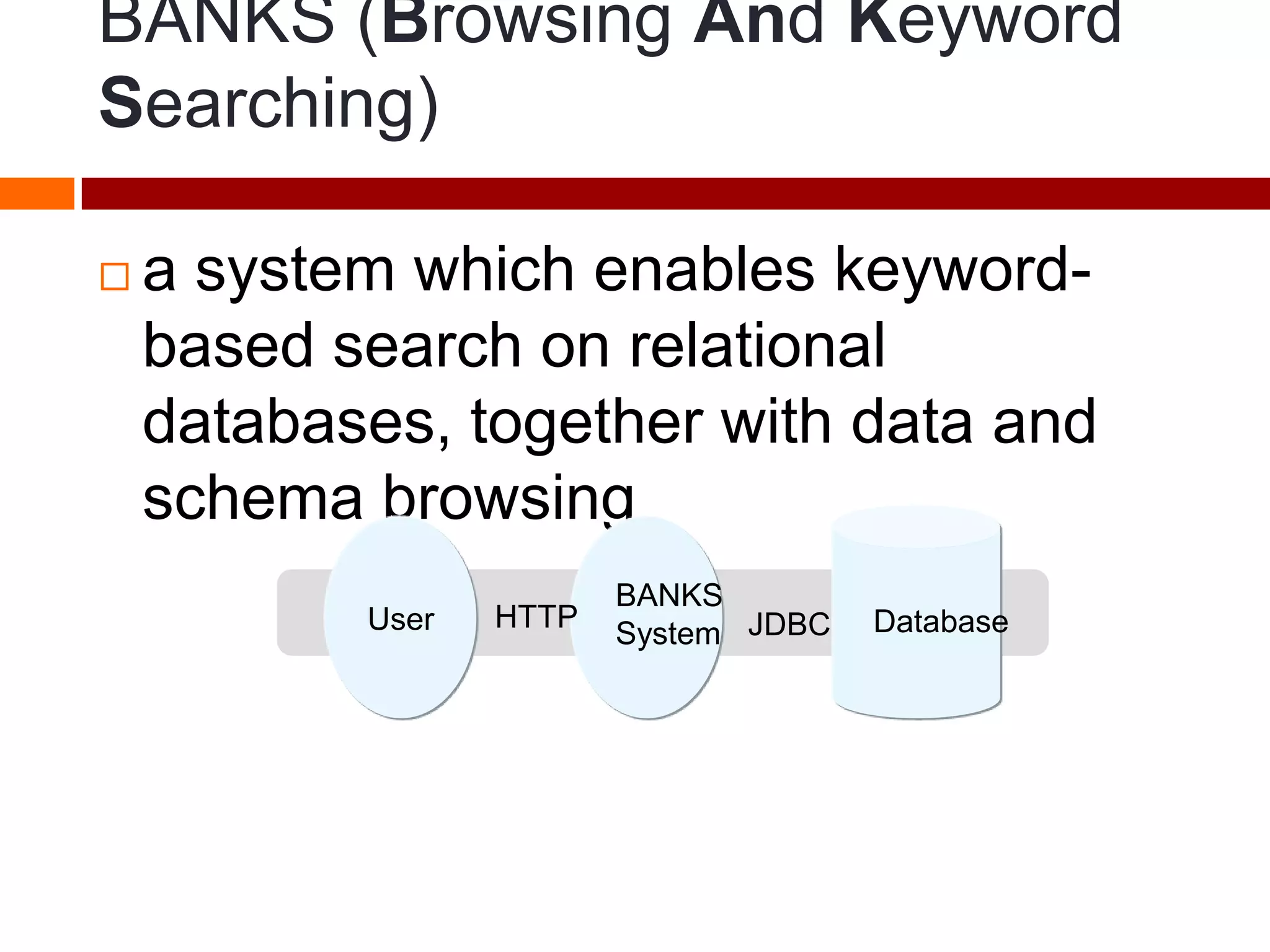

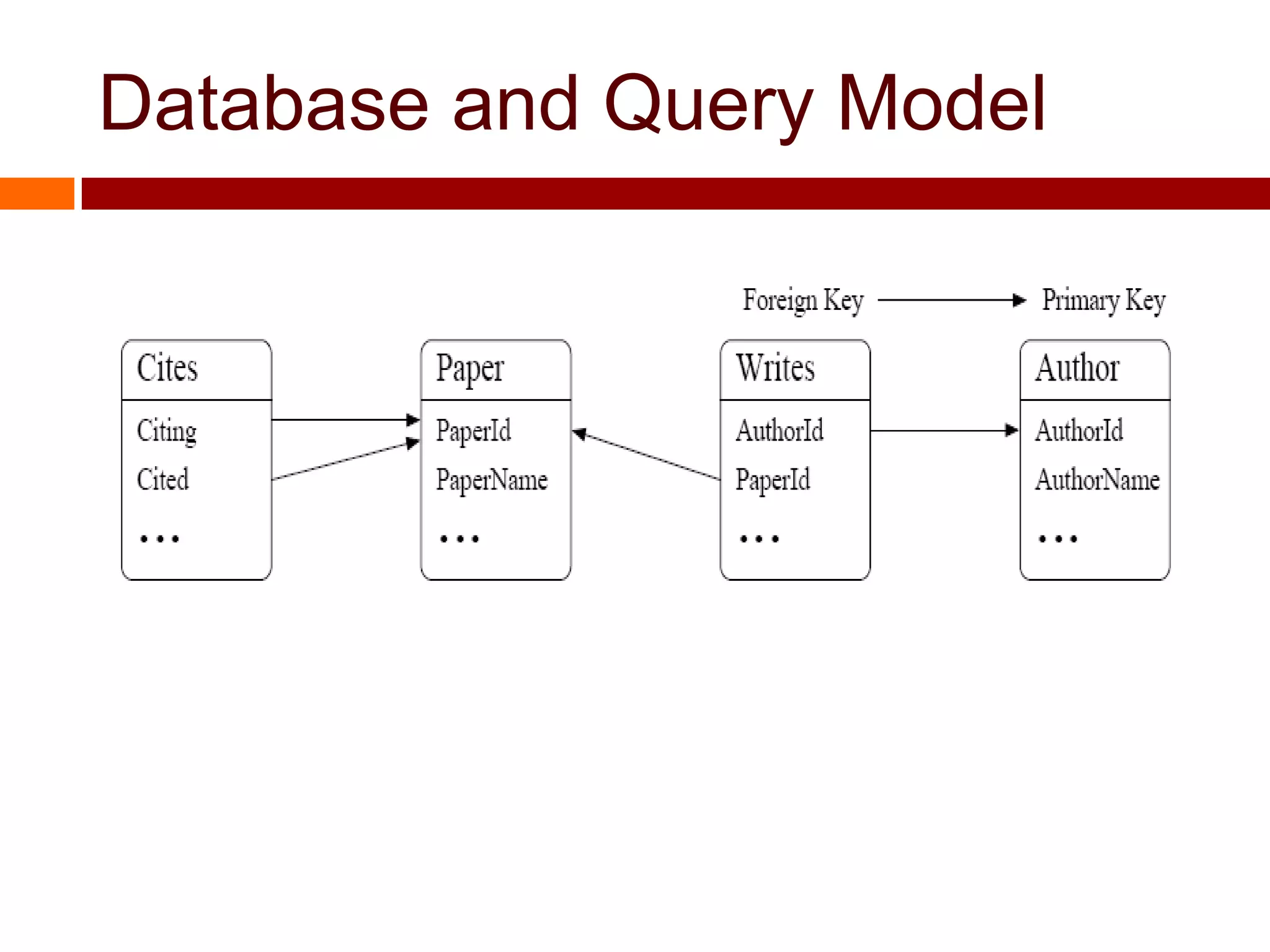







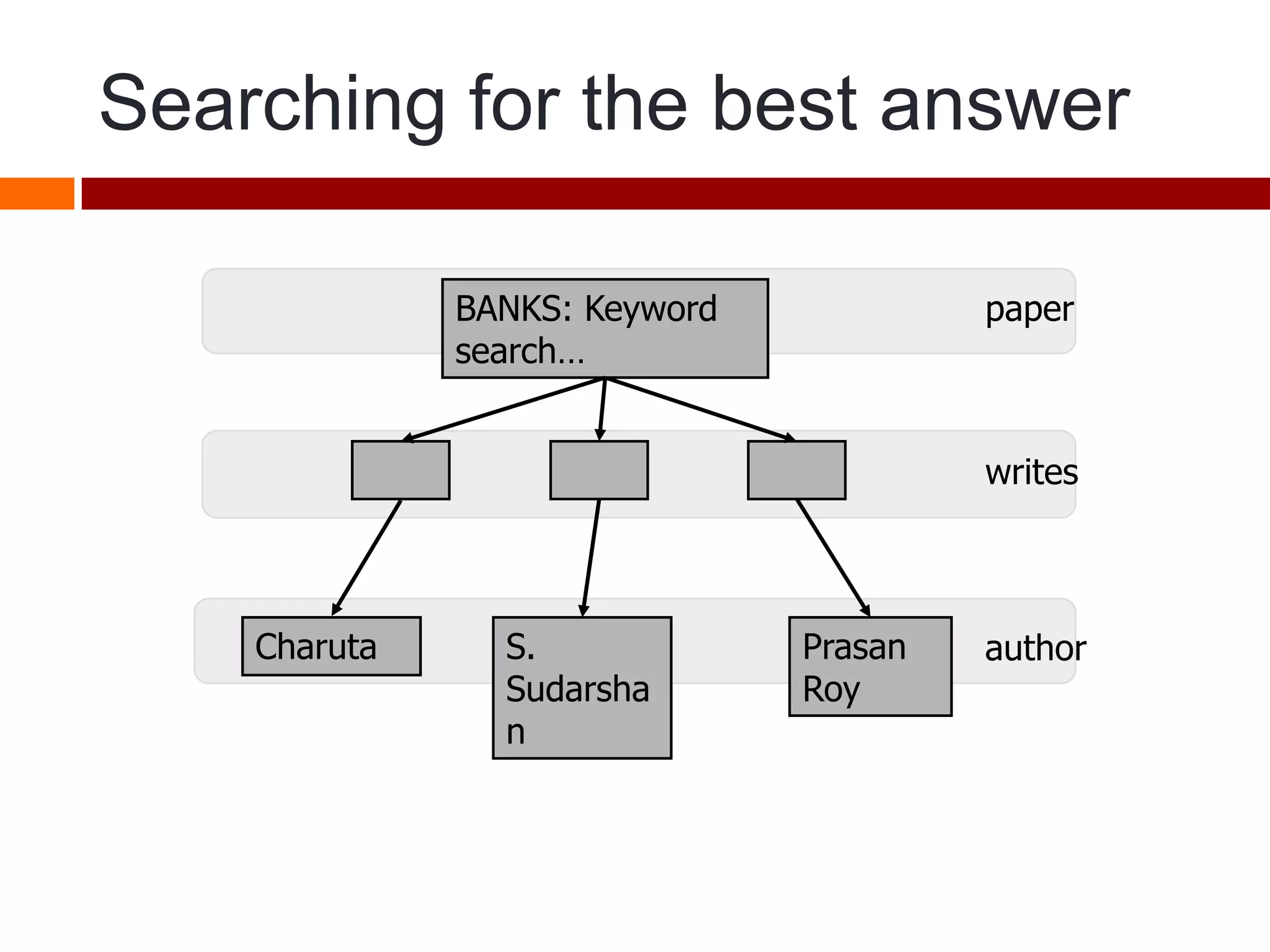







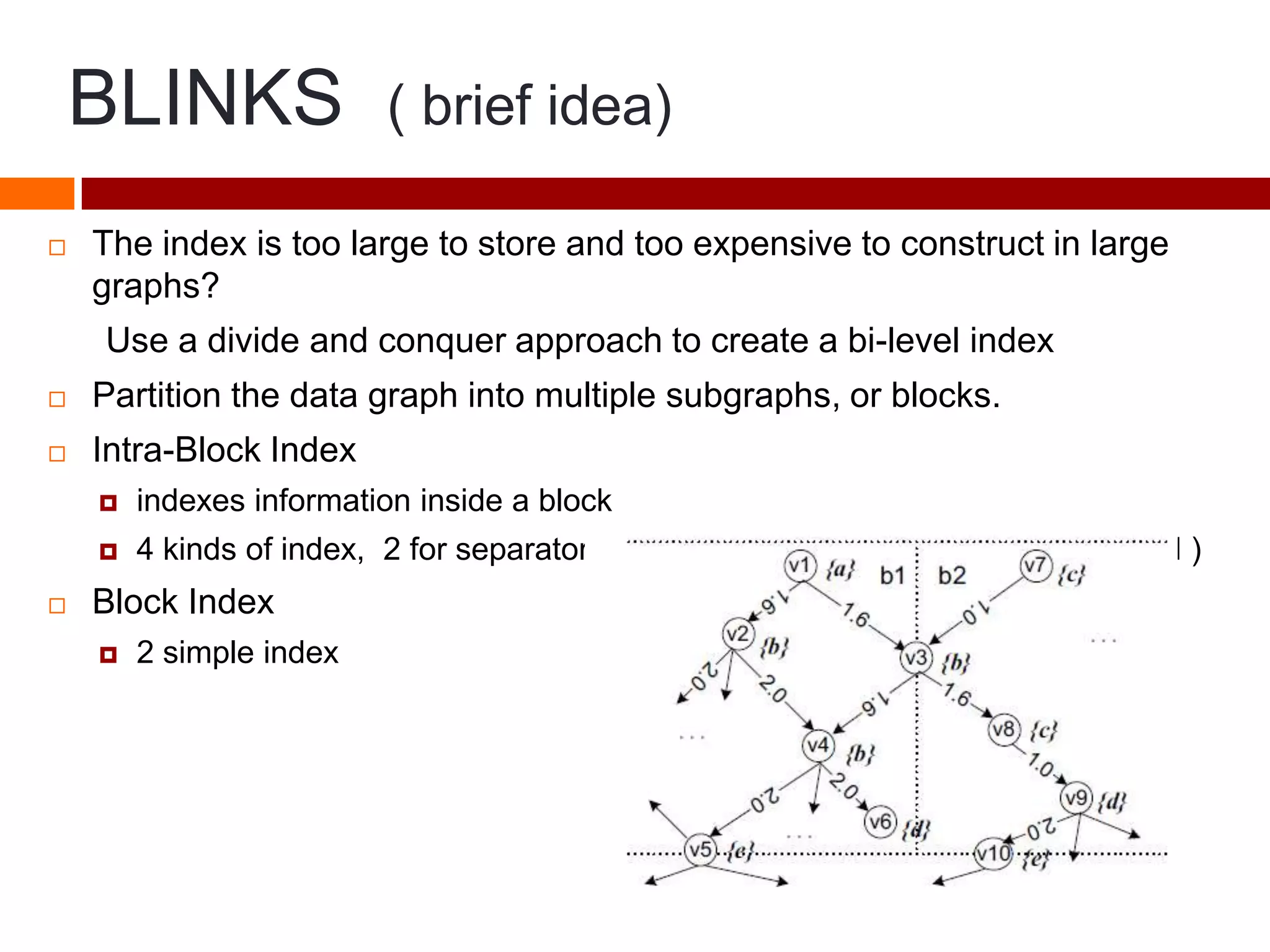



This document summarizes three papers on keyword search over structured databases using an interpretative approach. The first paper discusses building an efficient index table to map keywords to row and column identifiers in the database. The second paper presents a general algorithm with two steps - a publication step to pre-compute indexing, and a search step to lookup keywords and generate SQL queries. The third paper introduces the concept of intrinsic and contextual weights to model the dependency between query keywords and generate a ranked list of query interpretations.
























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















