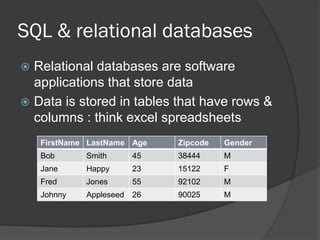
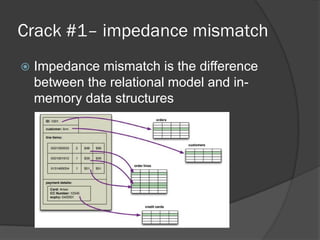
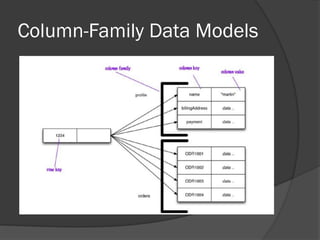
This document provides an overview of SQL and NoSQL databases. It discusses how relational databases using SQL emerged as the dominant data storage approach but faced challenges in scaling to big data workloads. NoSQL databases were developed to address these scaling needs by using non-relational data models like key-value, document, and column-oriented structures that are better suited to distributed architectures. The document outlines the history and characteristics of SQL and relational databases and how NoSQL databases address needs like scalability that drove their emergence in the big data era.






























































![Data Models [DATABASE SYSTEMS: Design, Implementation, and Management]](https://cdn.slidesharecdn.com/ss_thumbnails/coronelpptch02-datamodels-190903105908-thumbnail.jpg?width=640&height=640&fit=bounds)









































