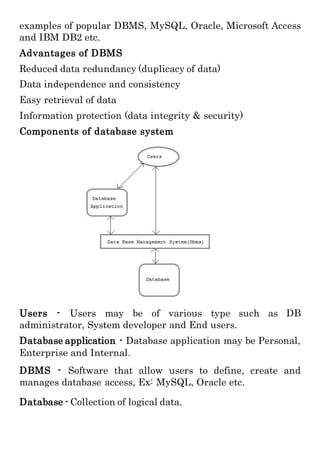
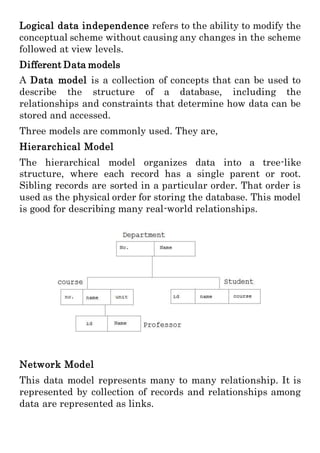
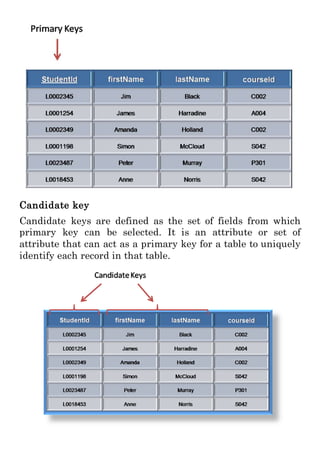
This document provides an overview of databases and database management systems (DBMS). It discusses what a database is, components of a database system like users and applications, and examples of DBMS like MySQL and Oracle. It also summarizes key database concepts such as data models, relationships between data using keys, and relational algebra operations for querying databases.