Downloaded 567 times








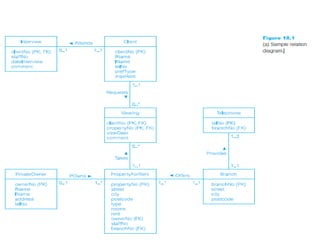



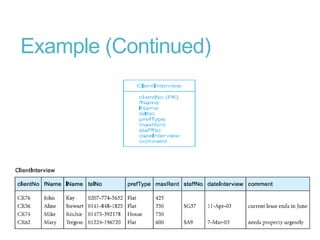

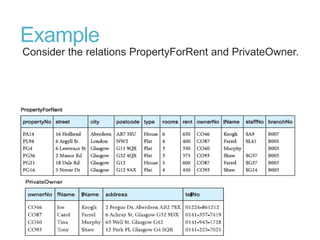

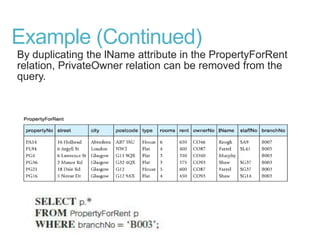


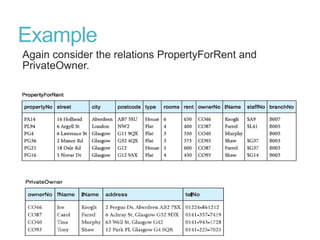

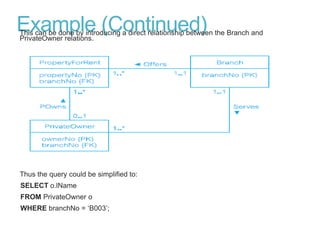
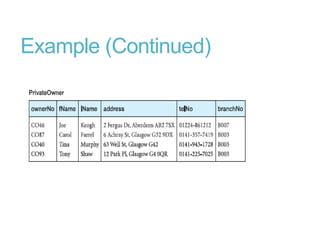


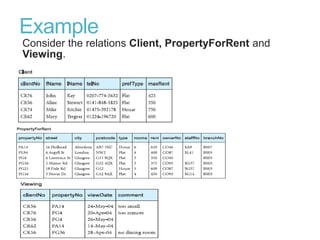









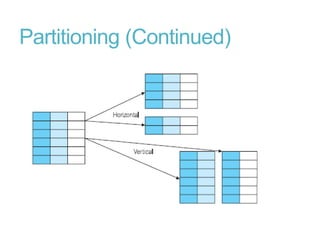











This document discusses denormalization, which refers to modifying a relational schema to be less normalized by combining relations or duplicating attributes. It describes 7 common denormalization techniques: 1) combining one-to-one relations, 2) duplicating attributes in one-to-many relations, 3) duplicating foreign keys, 4) duplicating attributes in many-to-many relations, 5) introducing repeating groups, 6) creating extract tables, and 7) partitioning relations. While denormalization can improve performance, it can also increase complexity, reduce flexibility, and slow down updates. Data integrity must be maintained when denormalizing.





























![The relational data model part[1]](https://cdn.slidesharecdn.com/ss_thumbnails/therelationaldatamodelpart1-150714113659-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)











































![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)







