Download to read offline


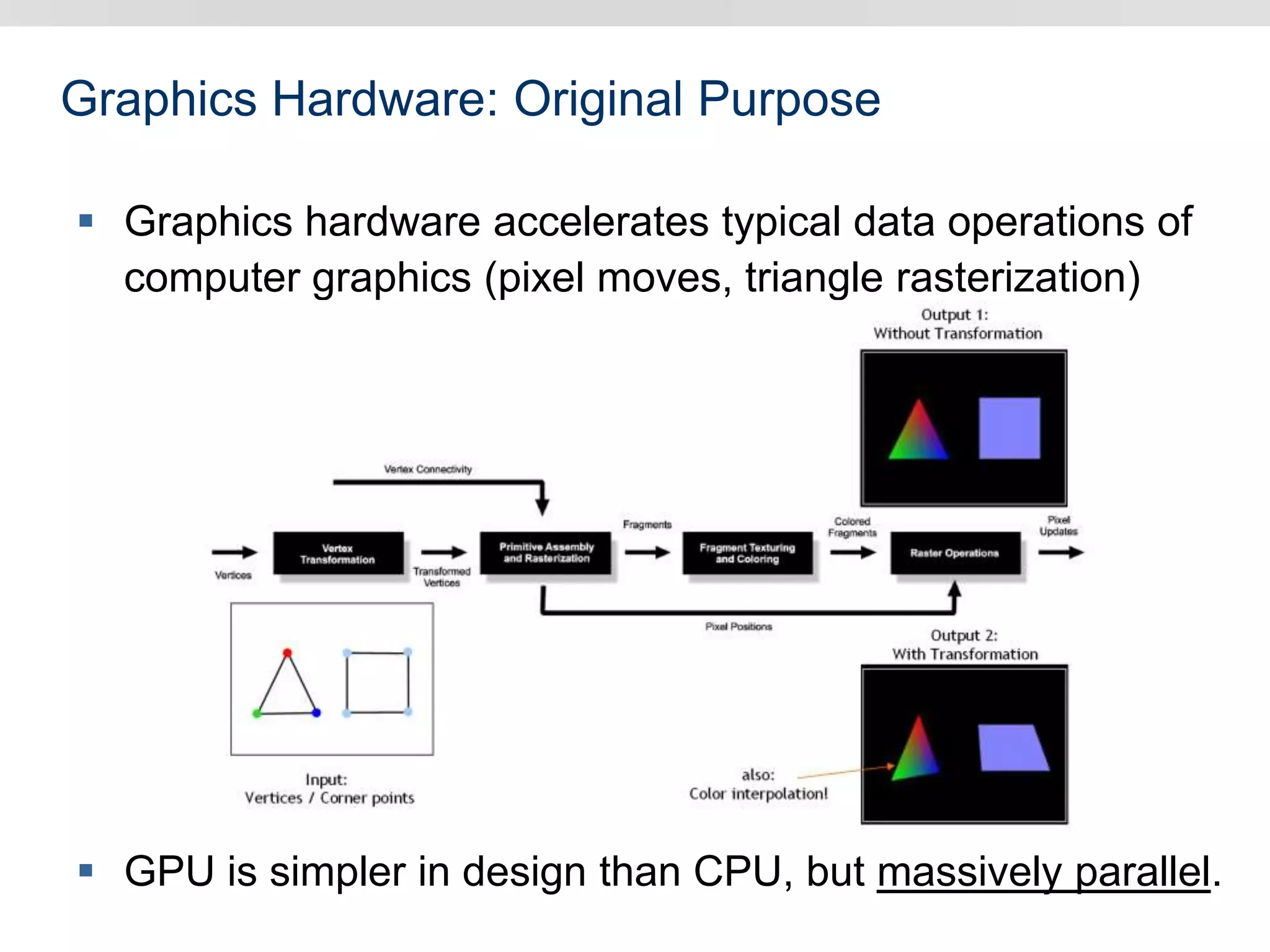
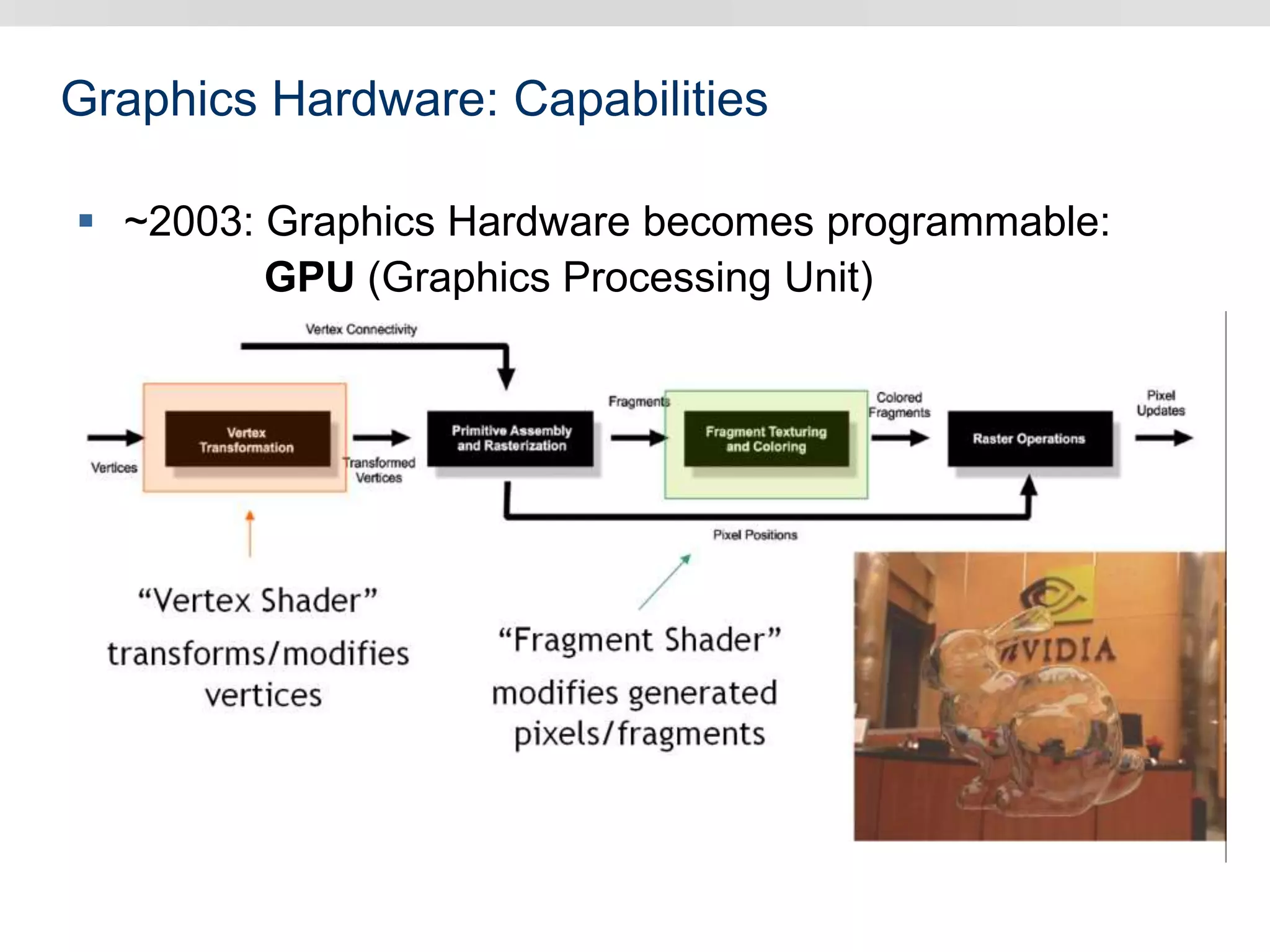


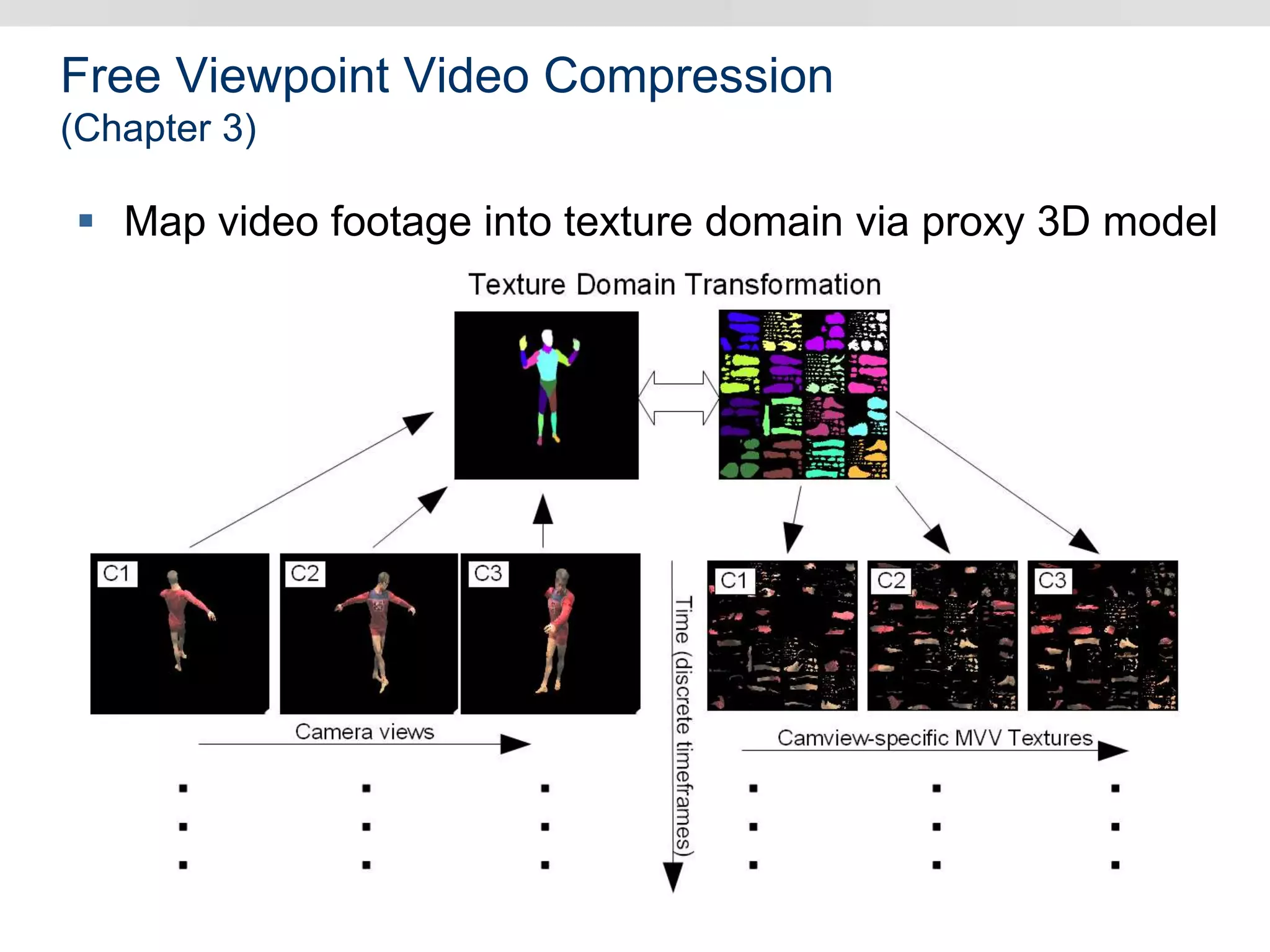
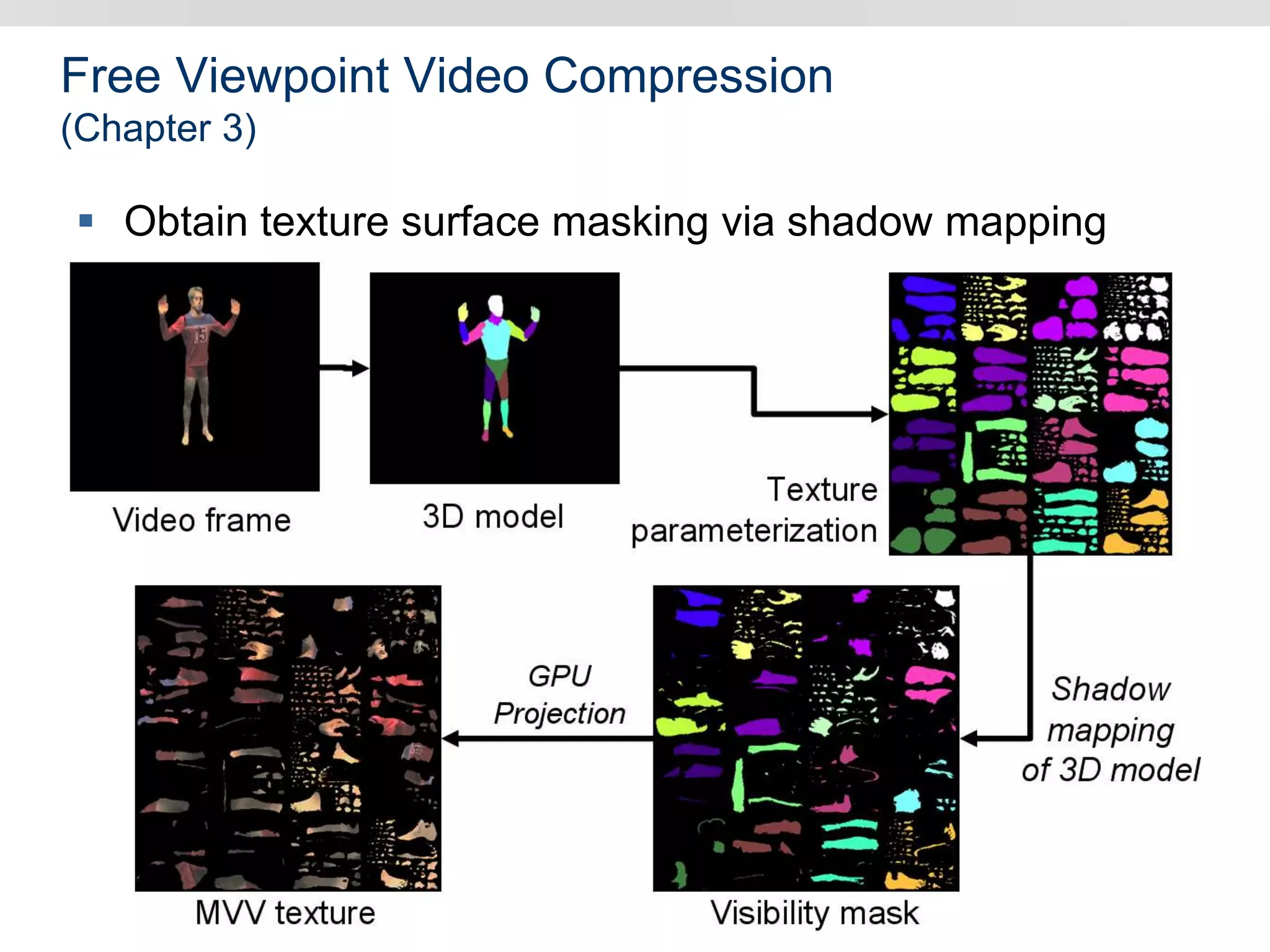

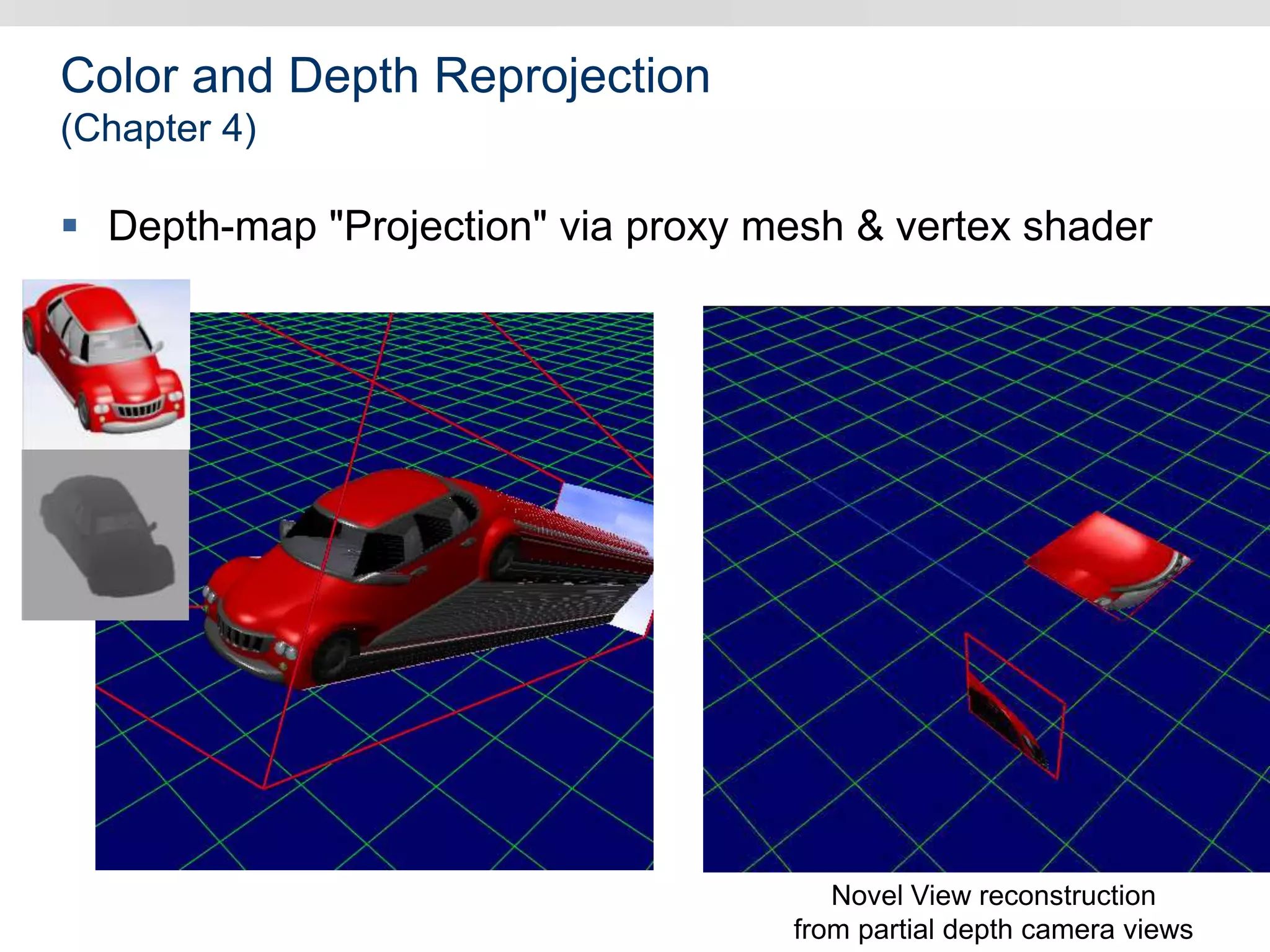
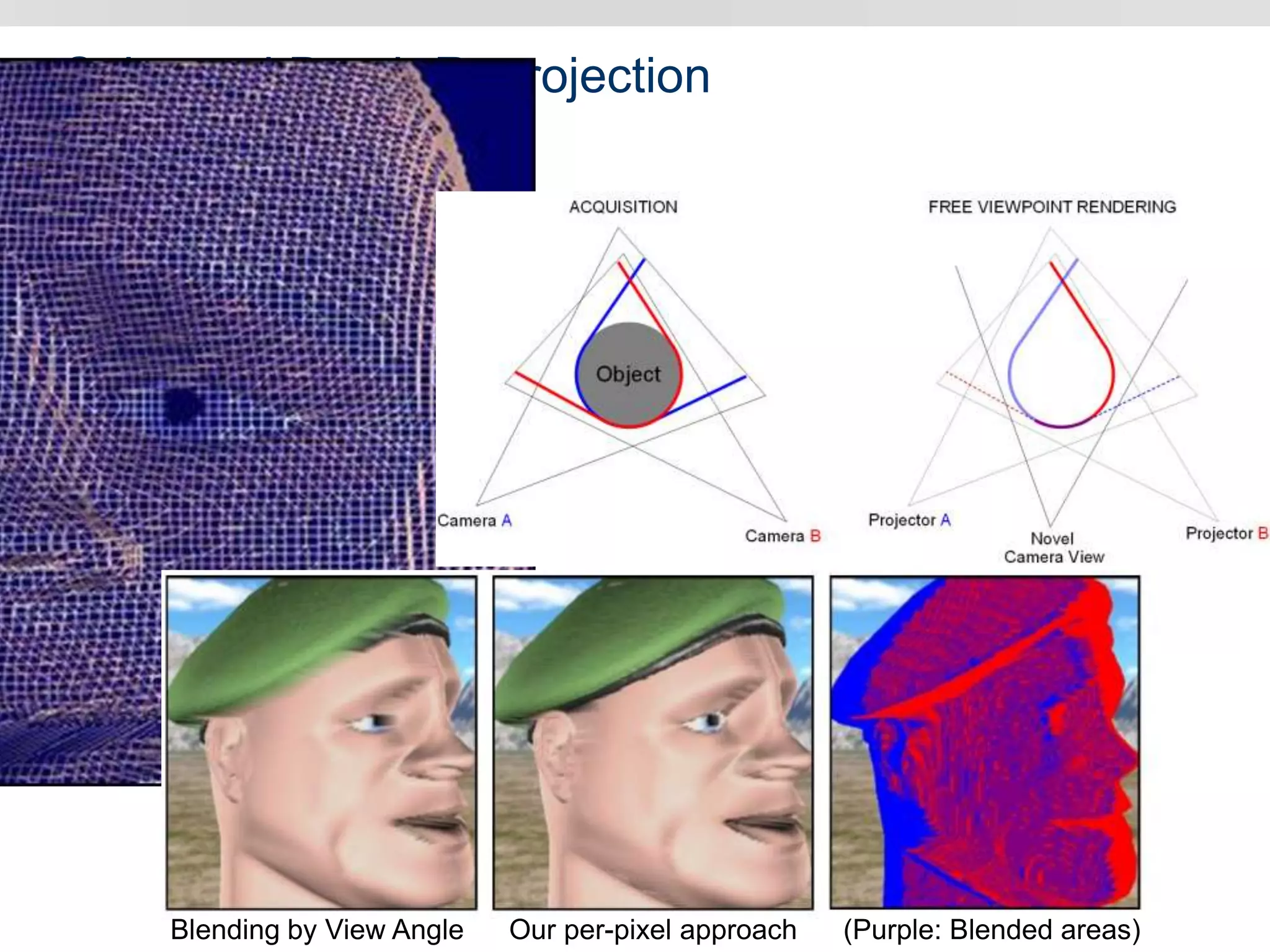

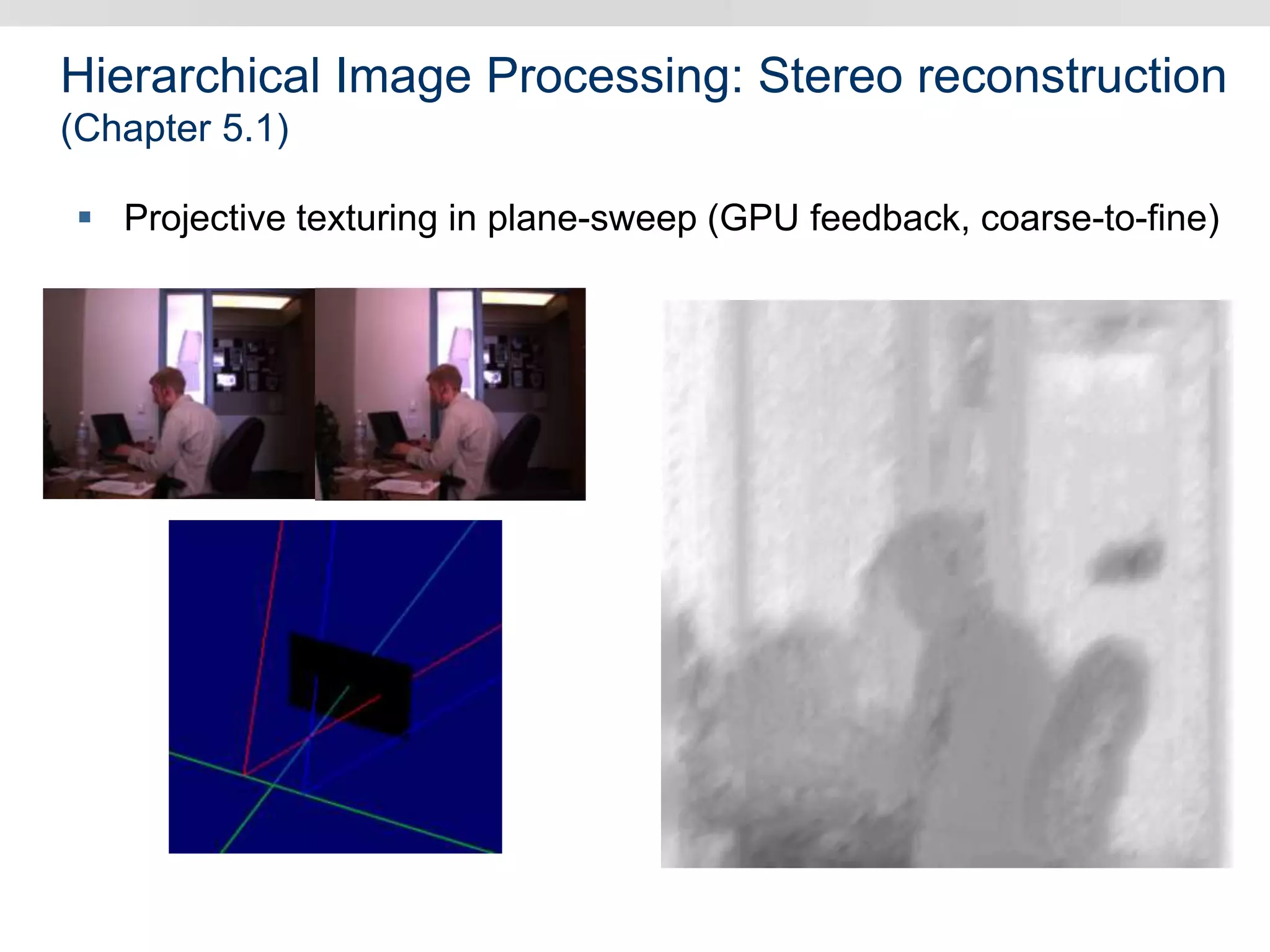



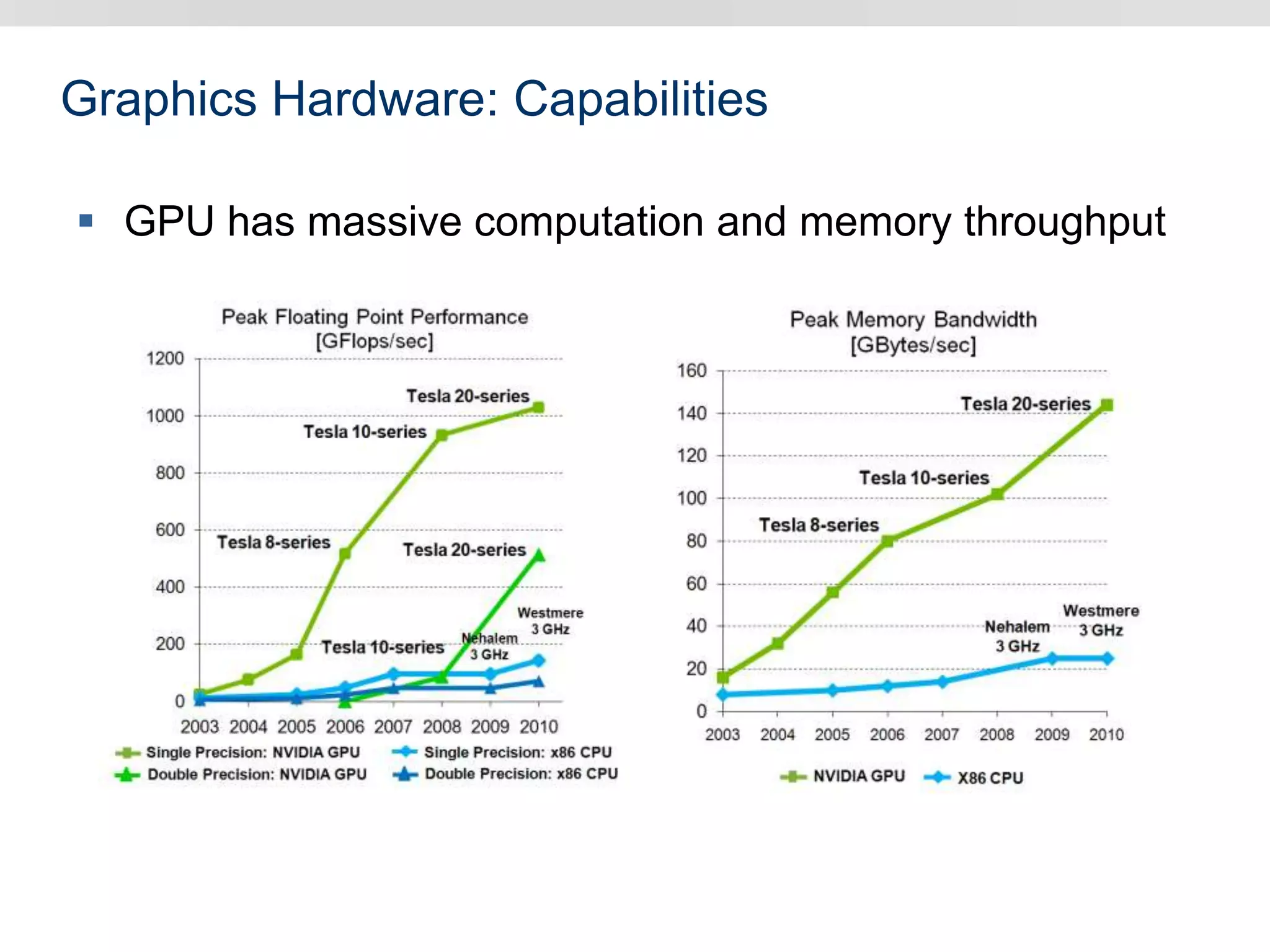


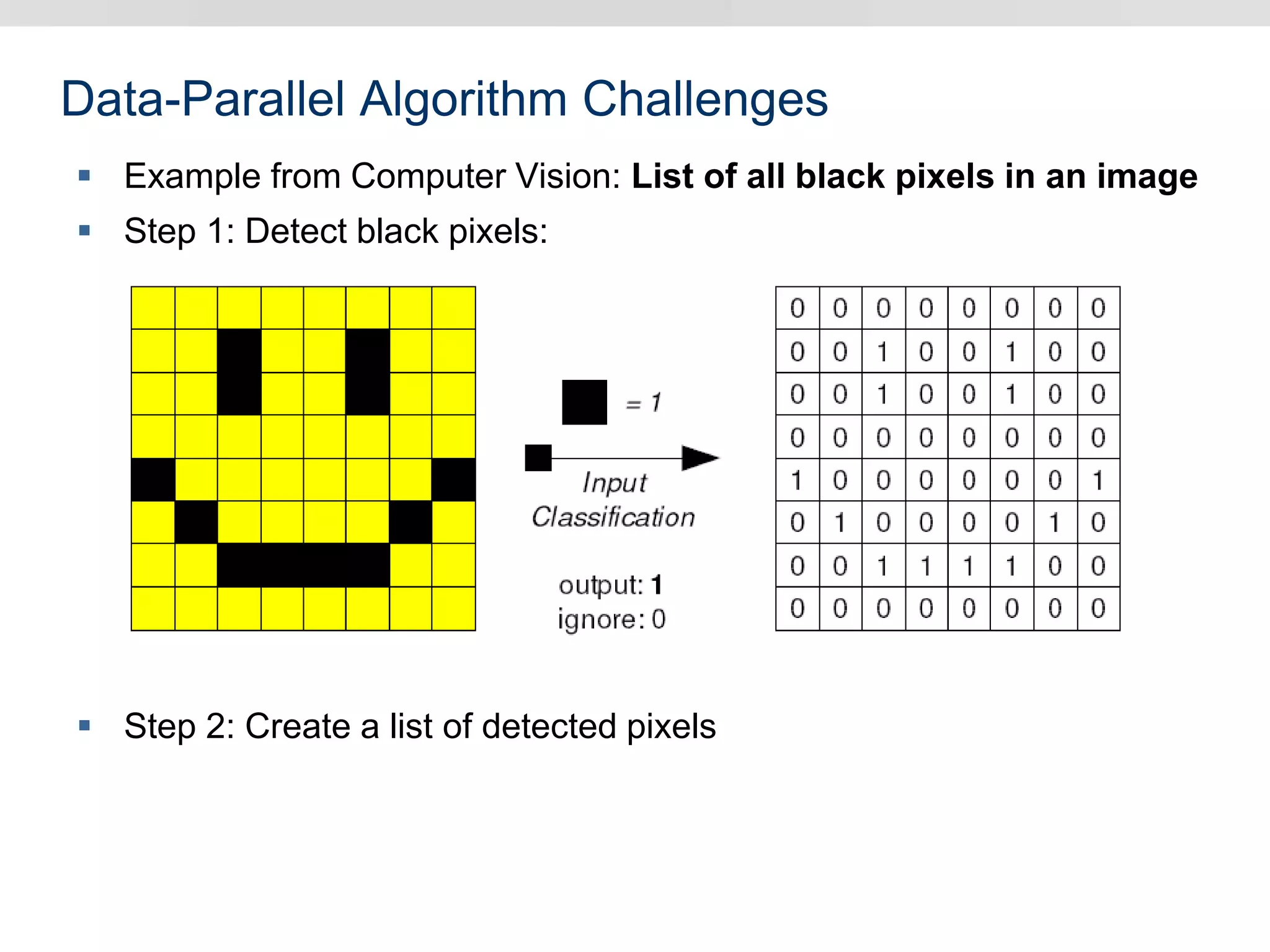

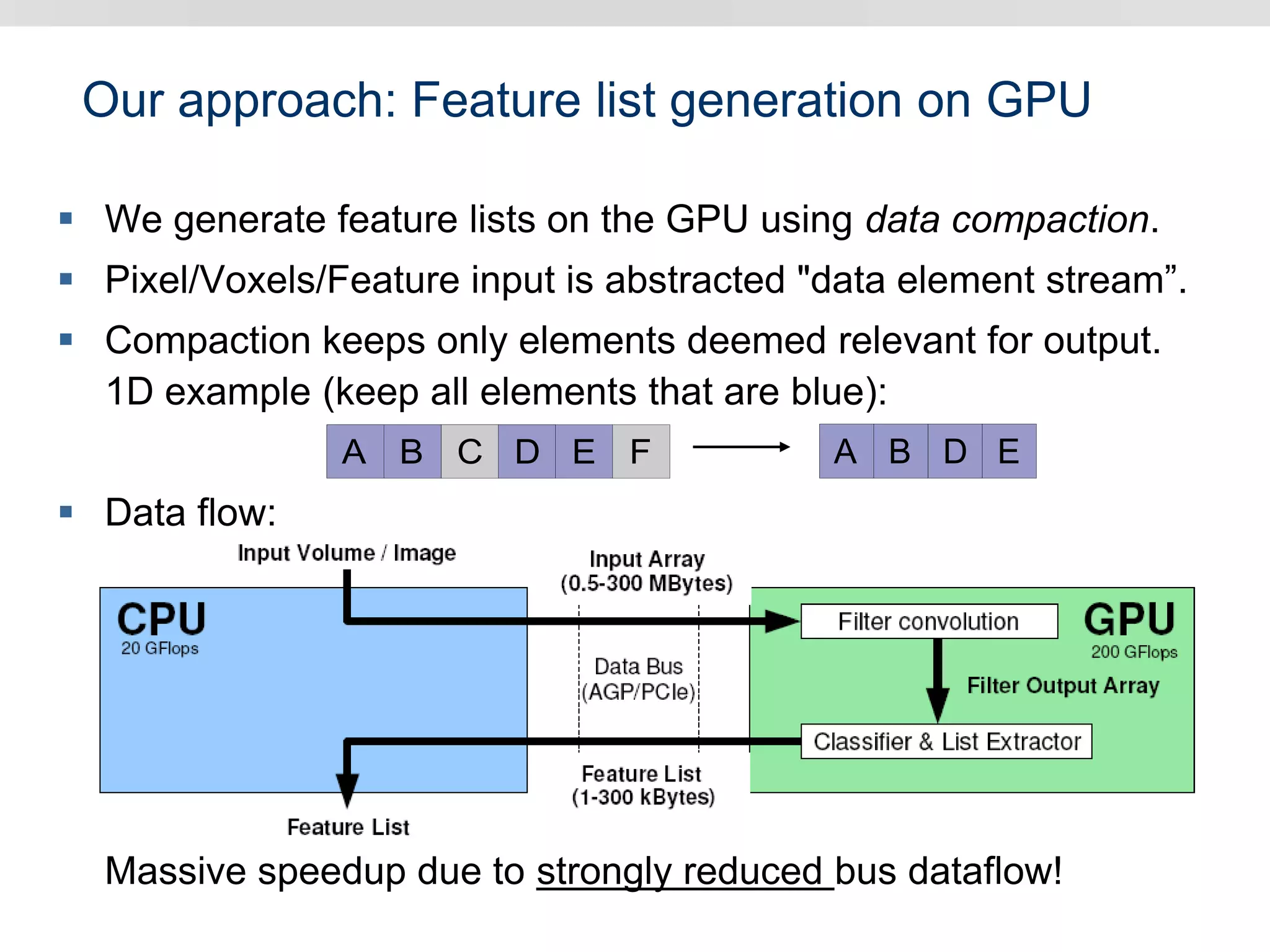
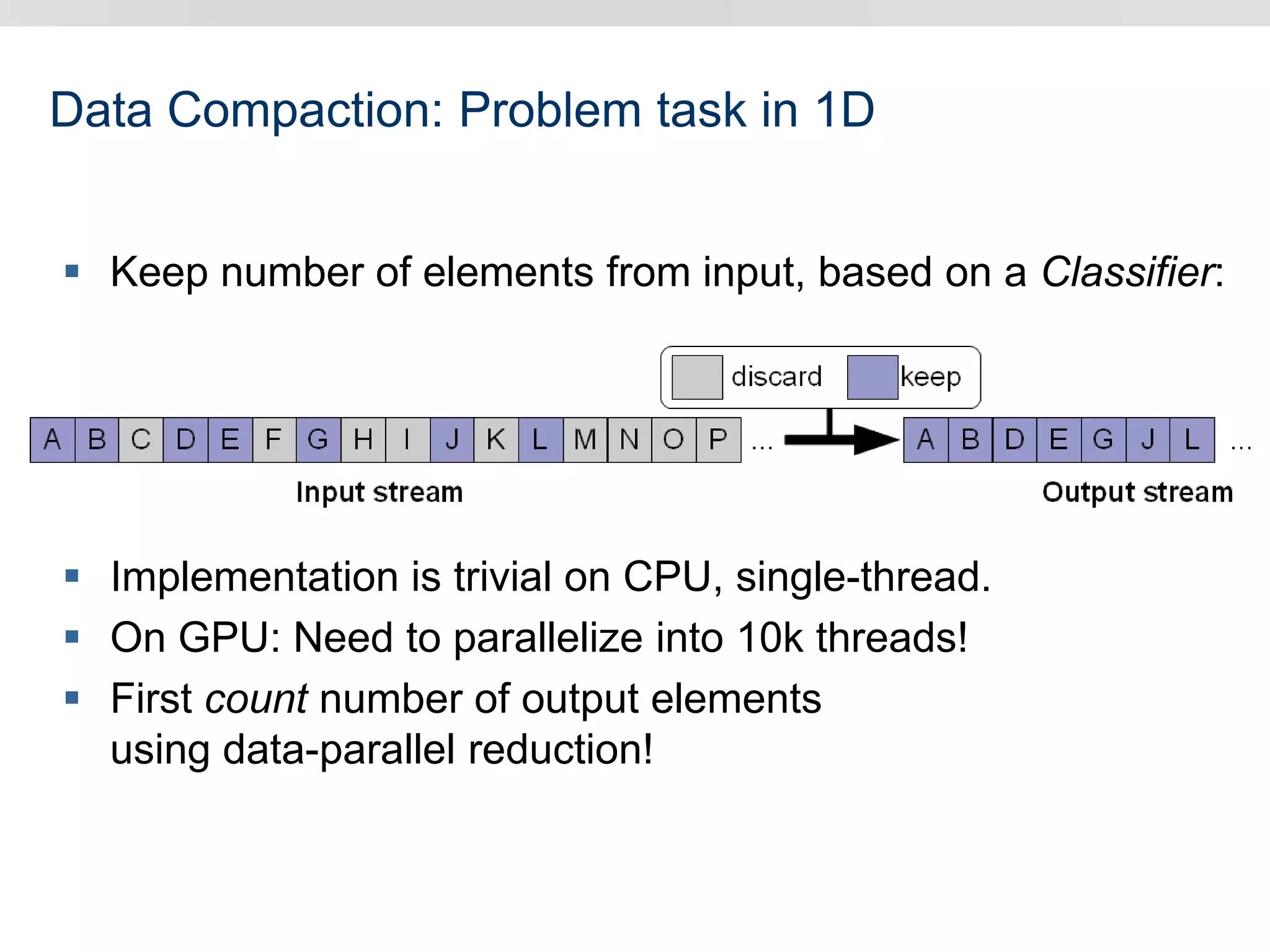
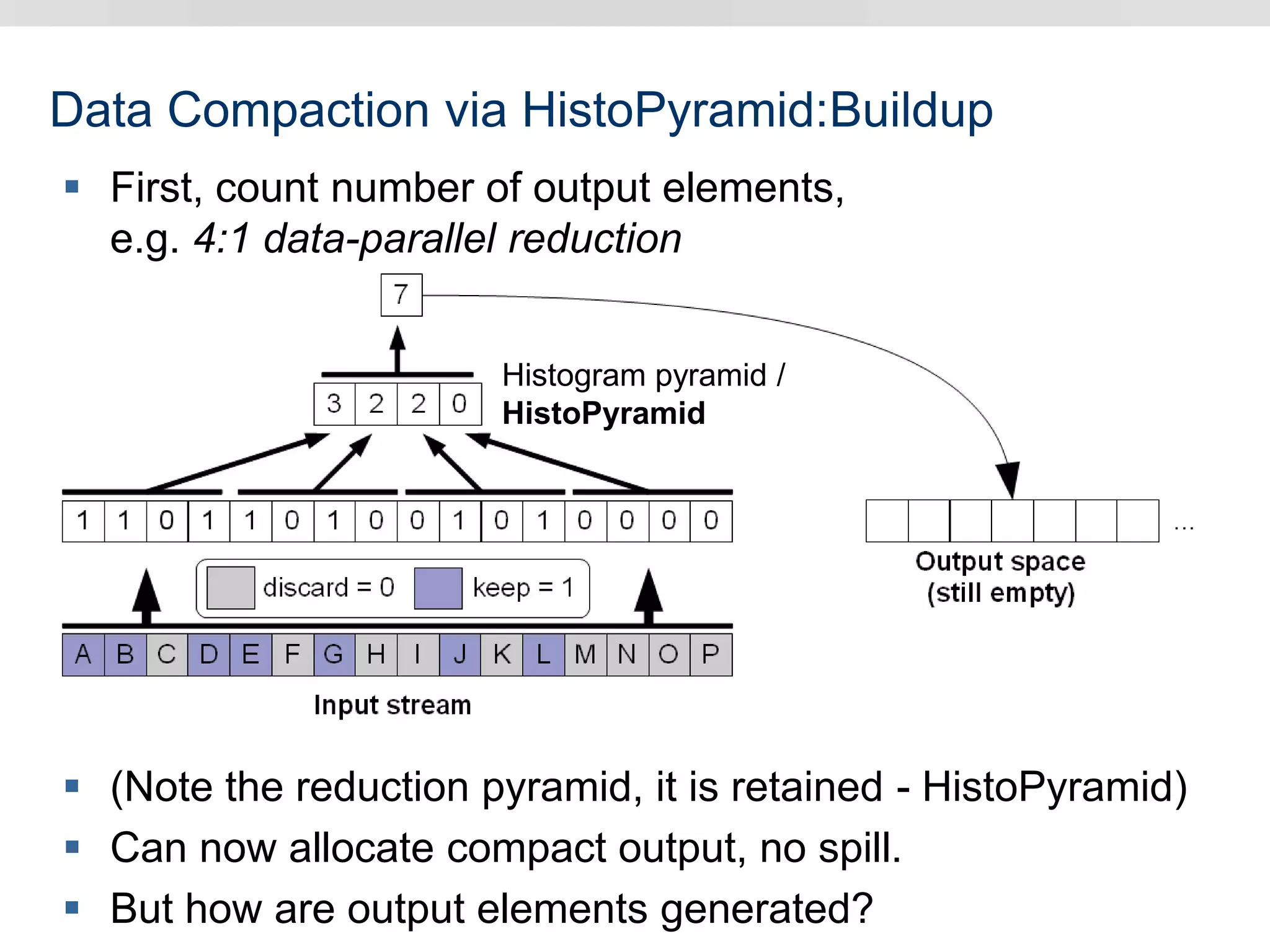
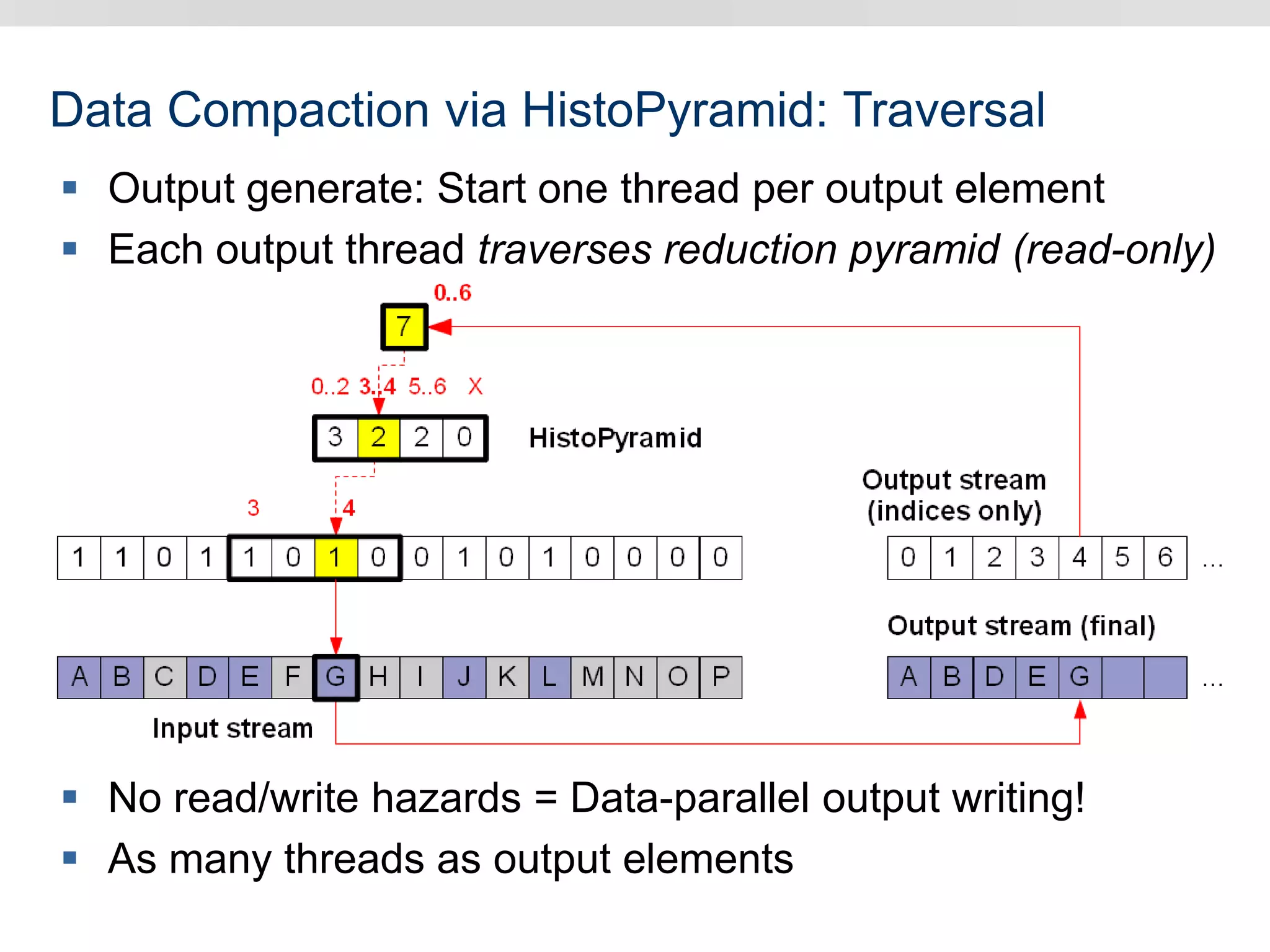
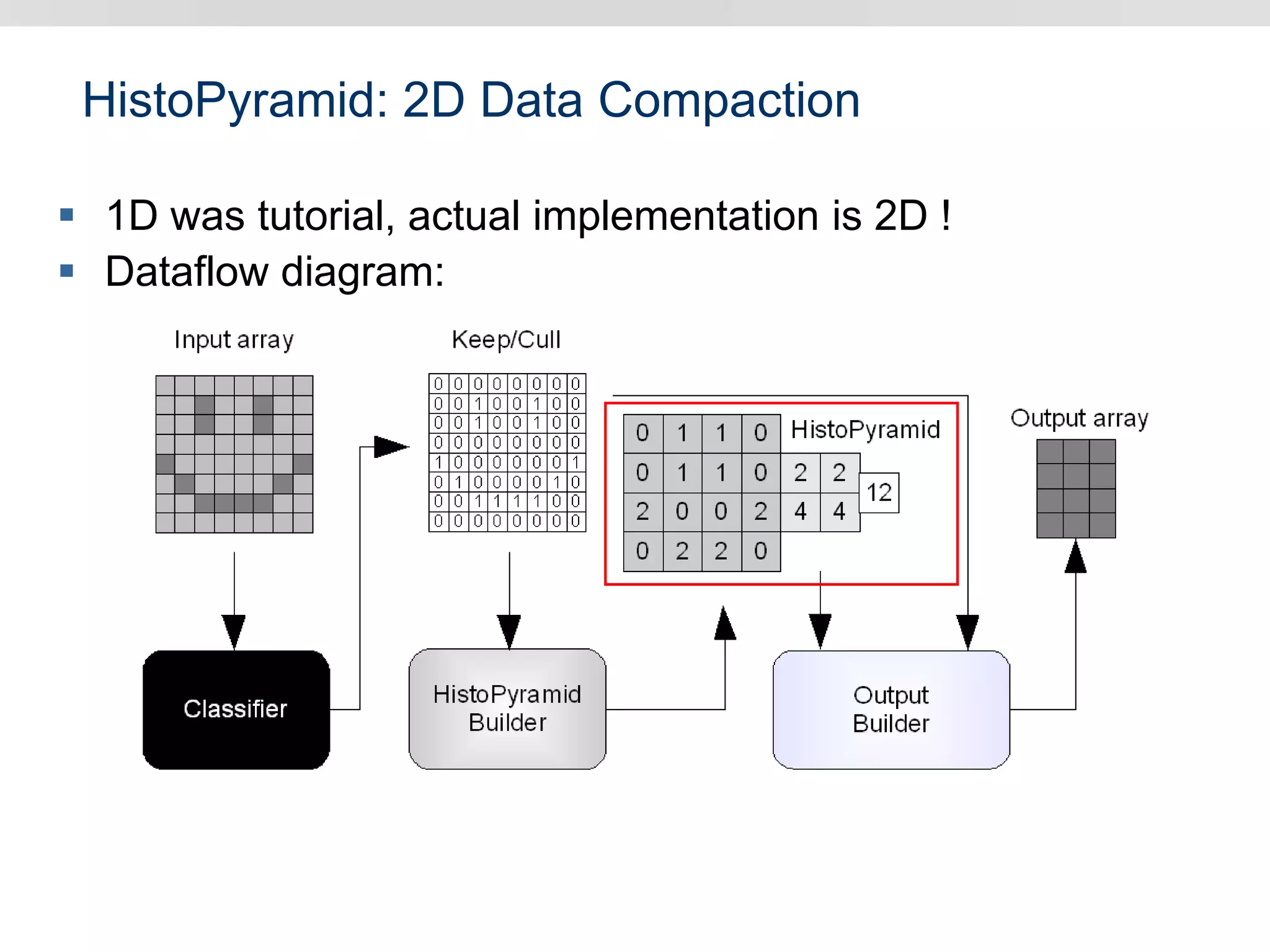
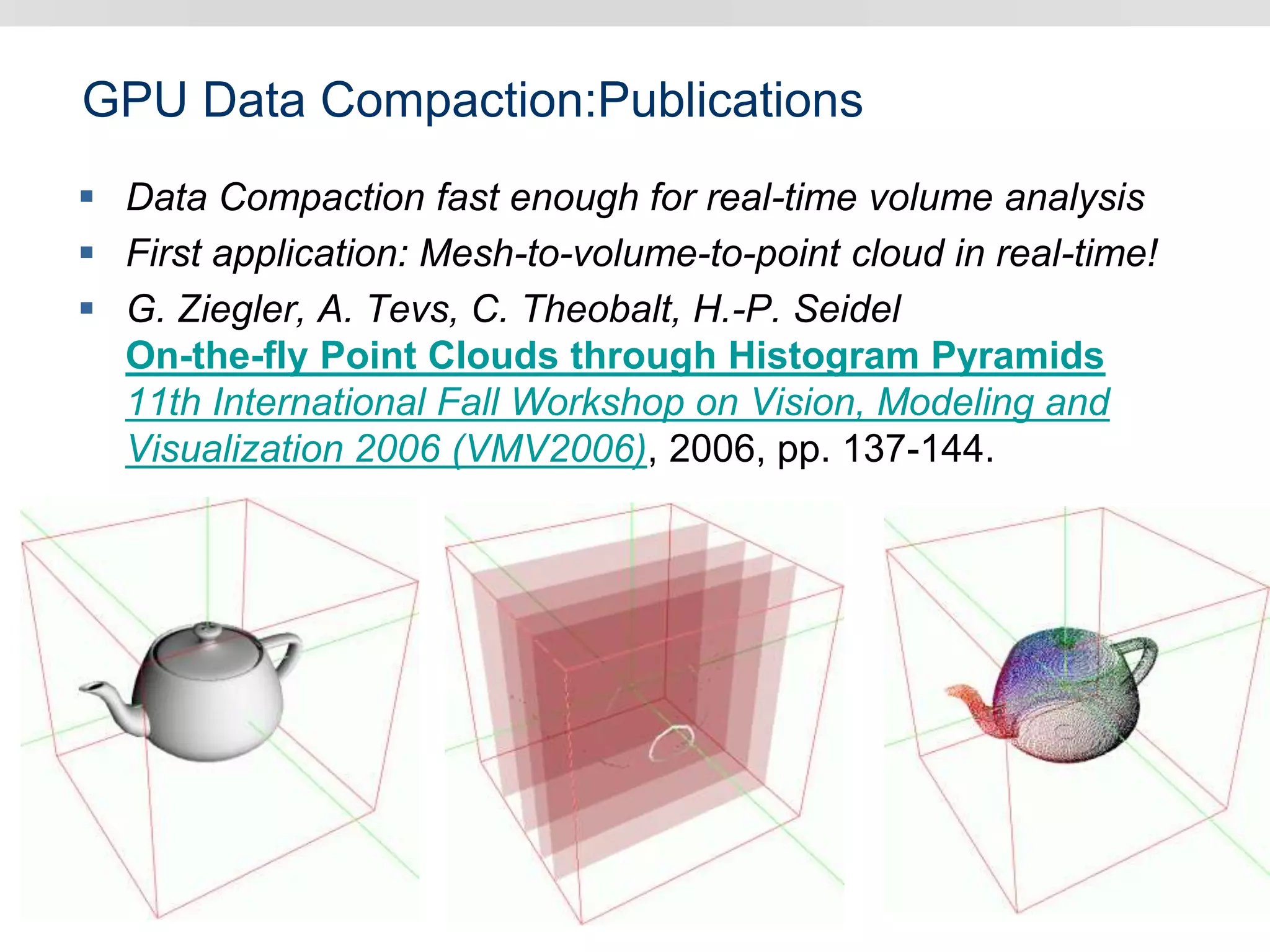



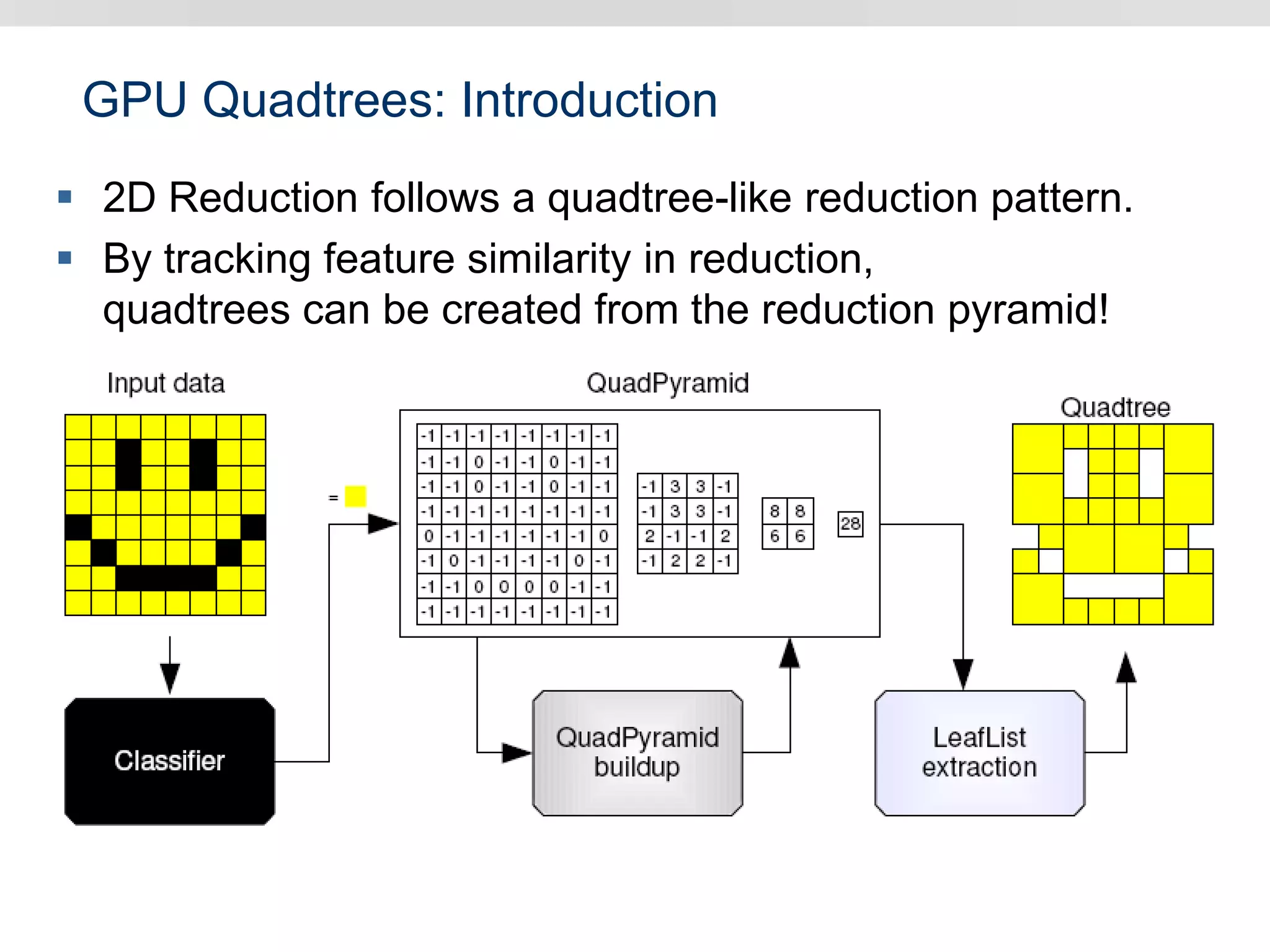





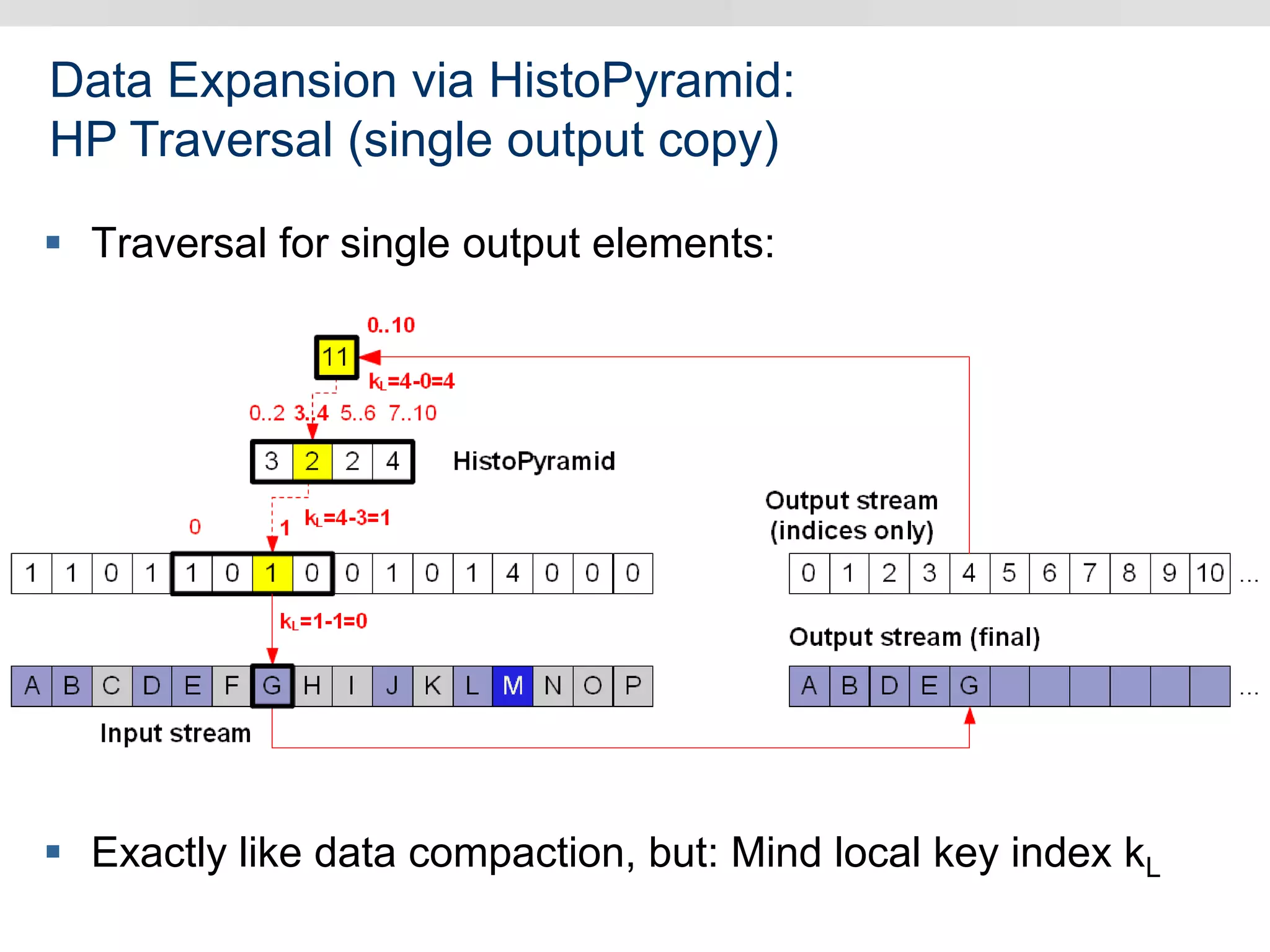



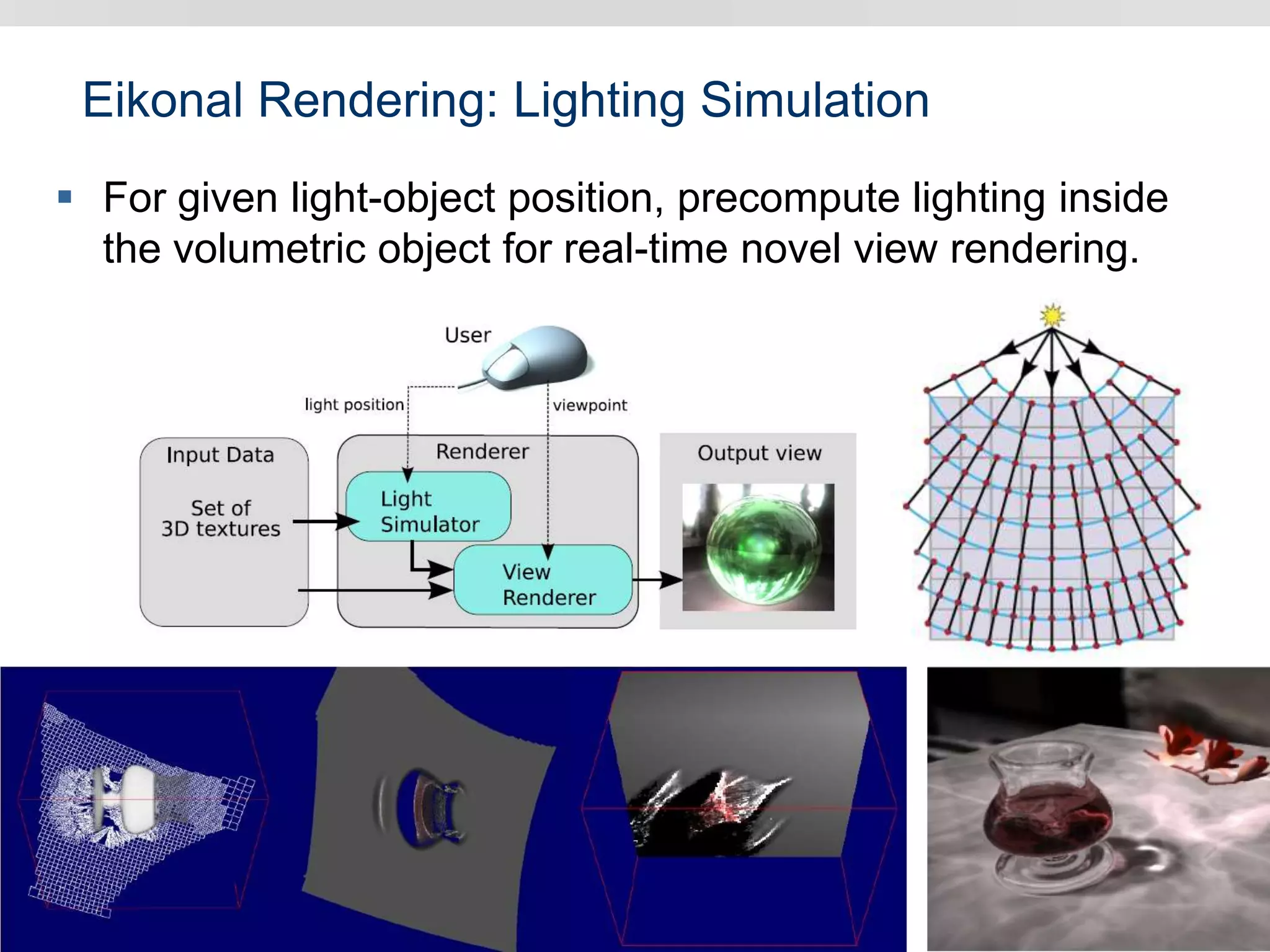



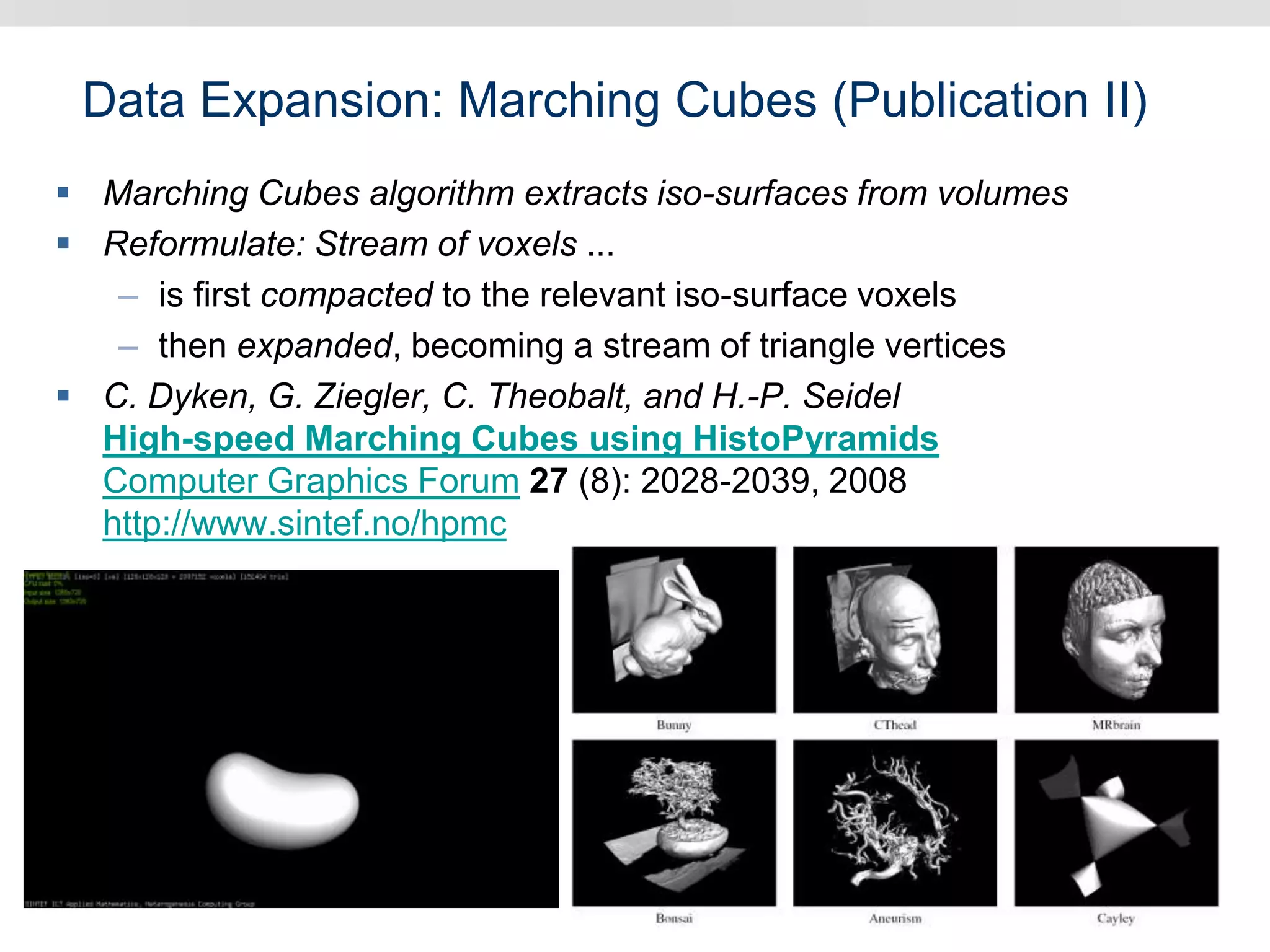












Graphics hardware has evolved from specialized graphics processors to general purpose GPUs capable of parallel data processing. This document outlines several ways GPUs can be used for visual computing and general data processing tasks. It describes using GPUs for classical computer vision tasks like stereo reconstruction as well as general data structures like quadtrees, octrees, and data compaction/expansion algorithms. The key challenges of parallelizing algorithms on GPUs and techniques like histogram pyramids for data-parallel processing of feature streams are discussed. Several publications applying these GPU techniques to problems in lighting simulation, point cloud generation, and iso-surface extraction are also summarized.



































































