Download as PDF, PPTX



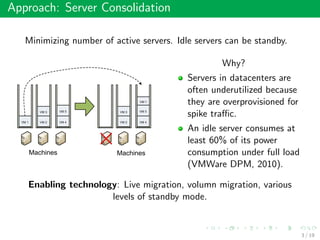

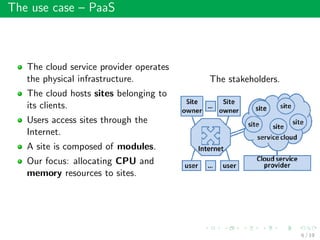
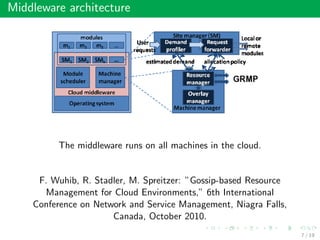
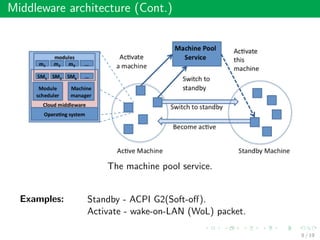





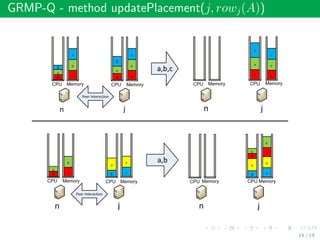


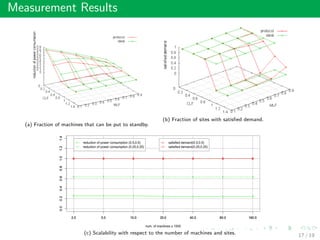



This document summarizes an approach called Gossip-based Resource Allocation for Green Computing in Large Clouds. The approach uses a distributed middleware architecture and gossip-based algorithms to dynamically consolidate virtual machines on the minimum number of active servers for energy efficiency. It aims to maximize utility and minimize power consumption and reconfiguration costs in large cloud environments with over 100,000 machines. The Generic Resource Management Protocol (GRMP) is presented as a scalable solution that can be instantiated in different ways, such as GRMP-Q, to achieve server consolidation under low load and fair allocation under high load. Simulation results show GRMP-Q reduces power consumption while maintaining satisfied demand and fairness across large systems.















































