Downloaded 22 times



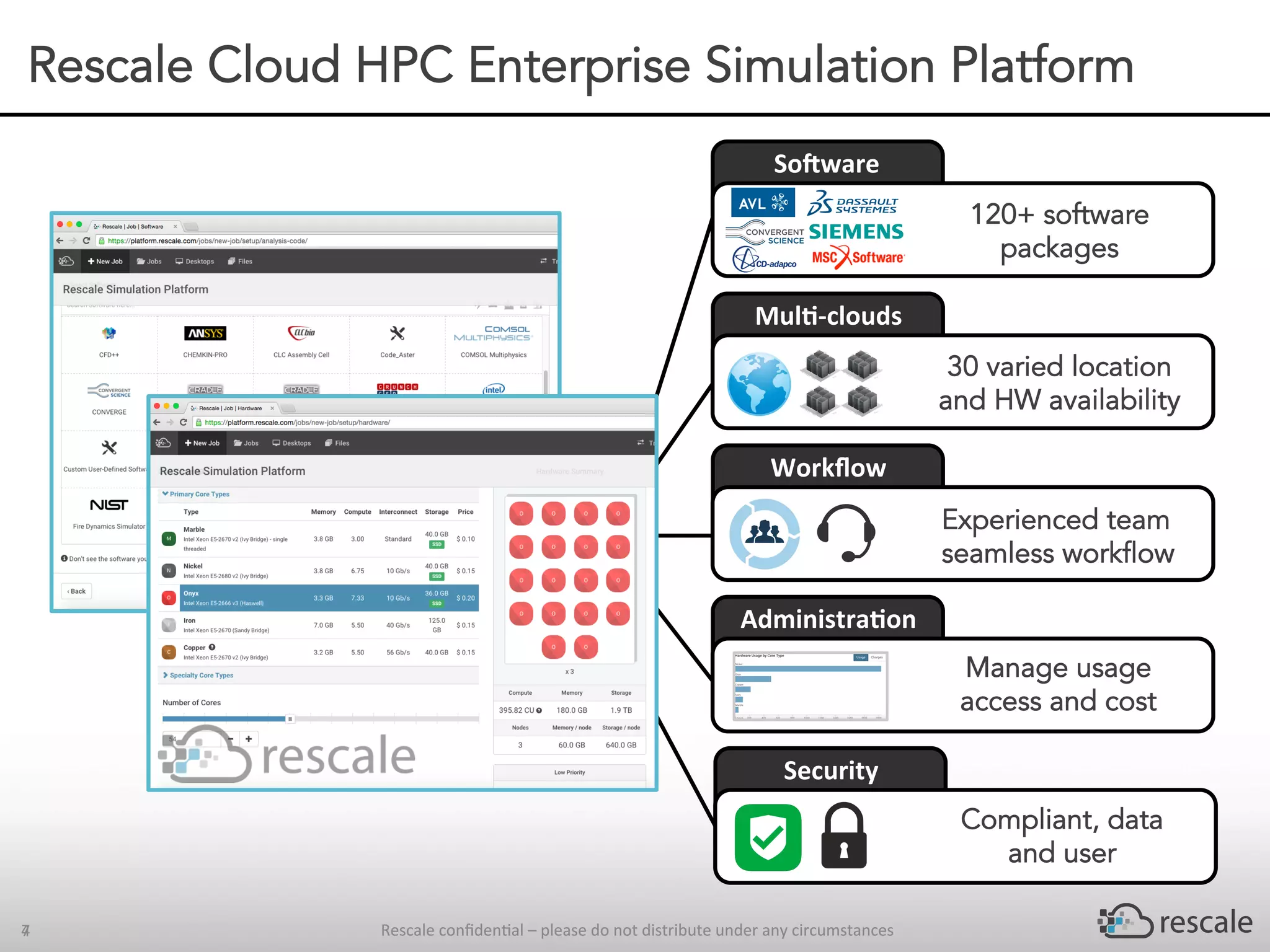
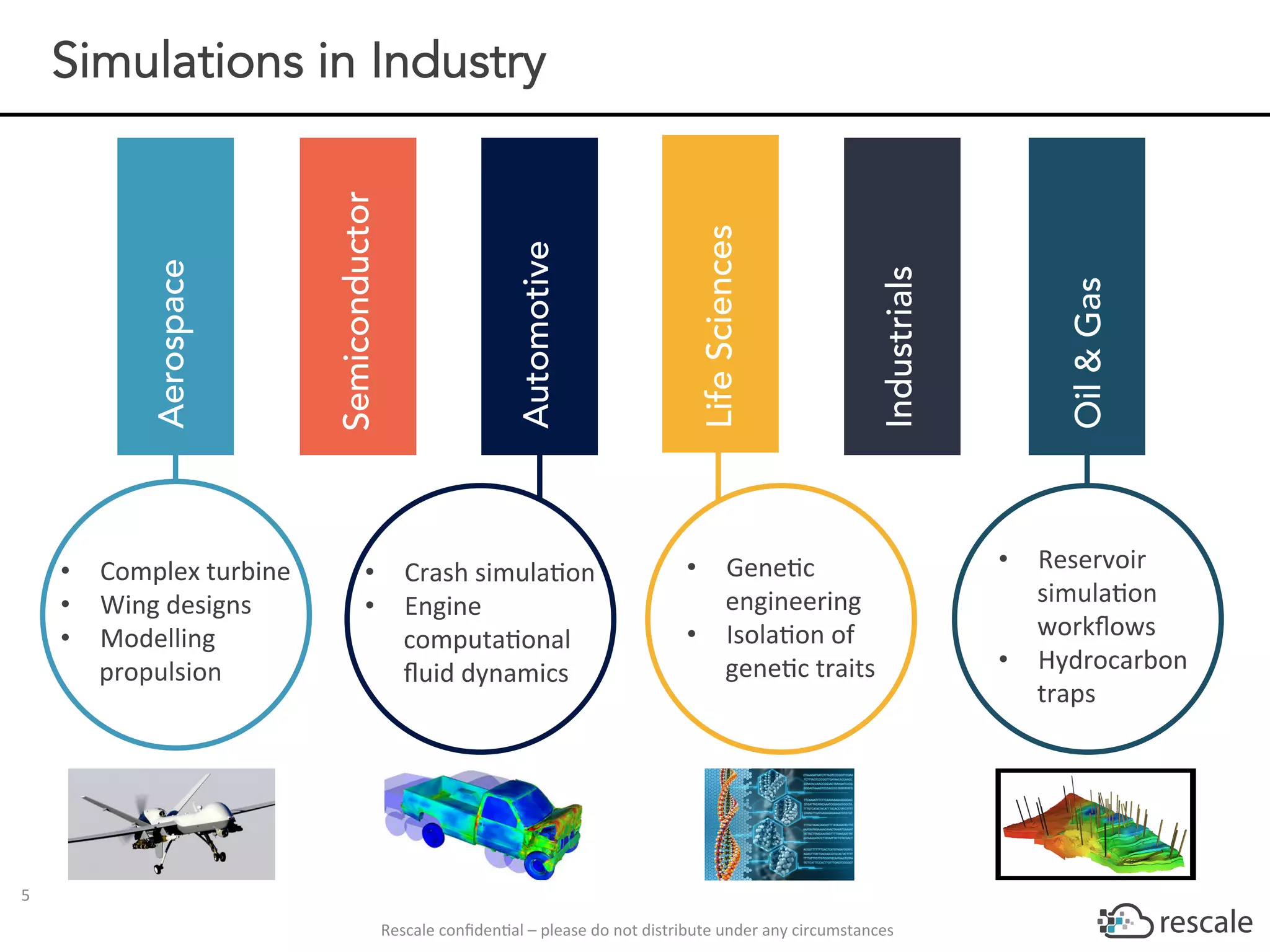
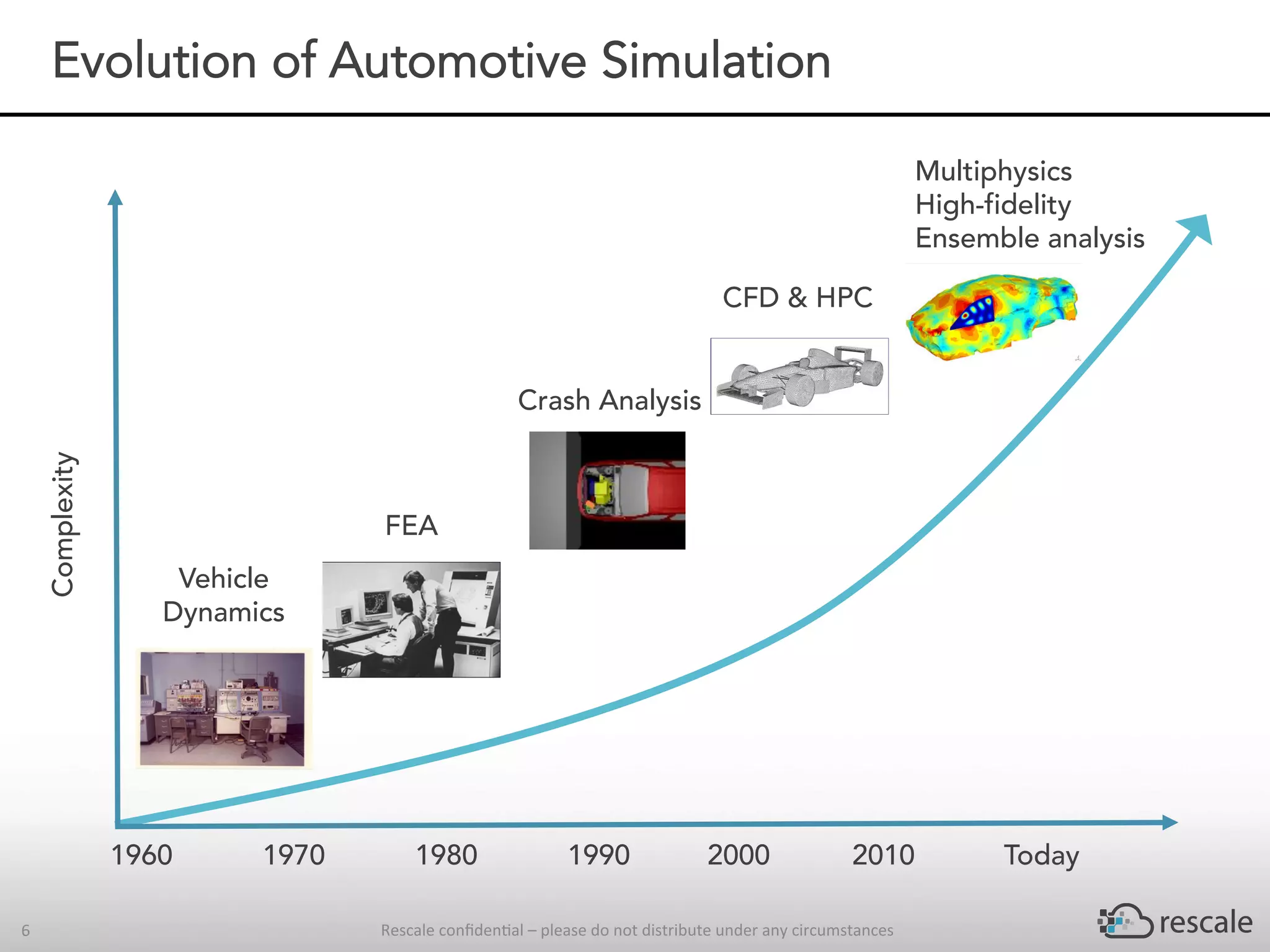
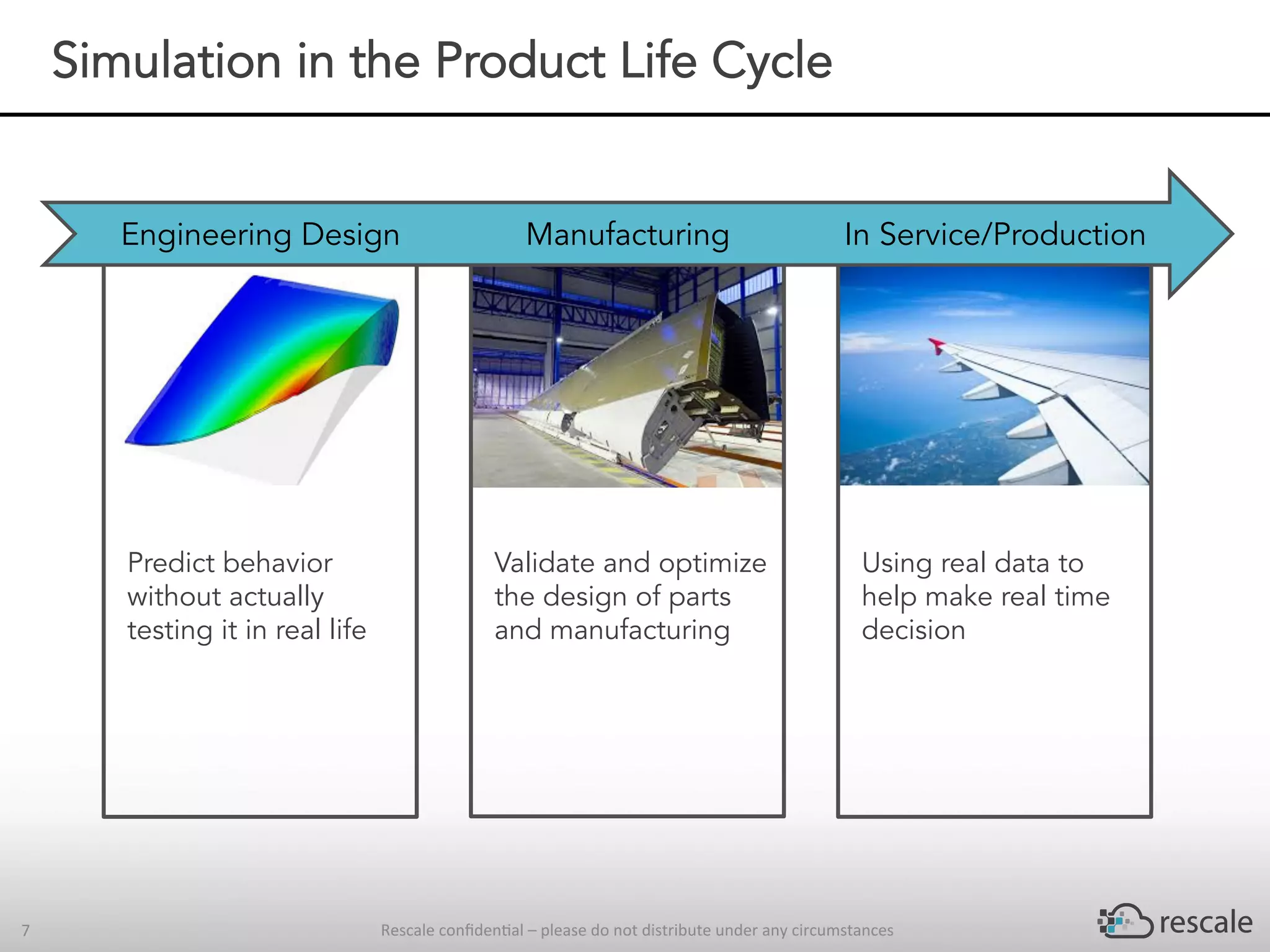


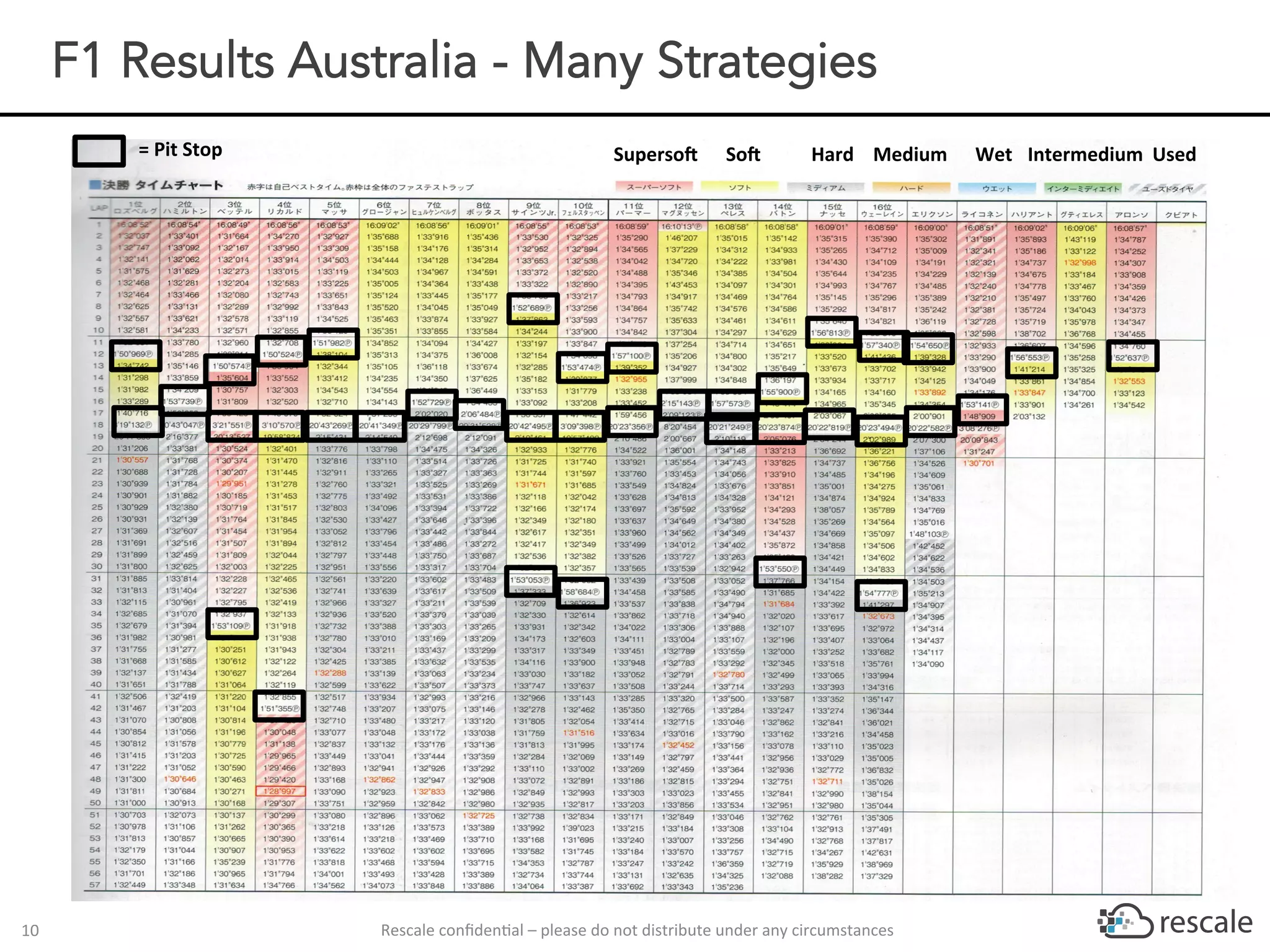



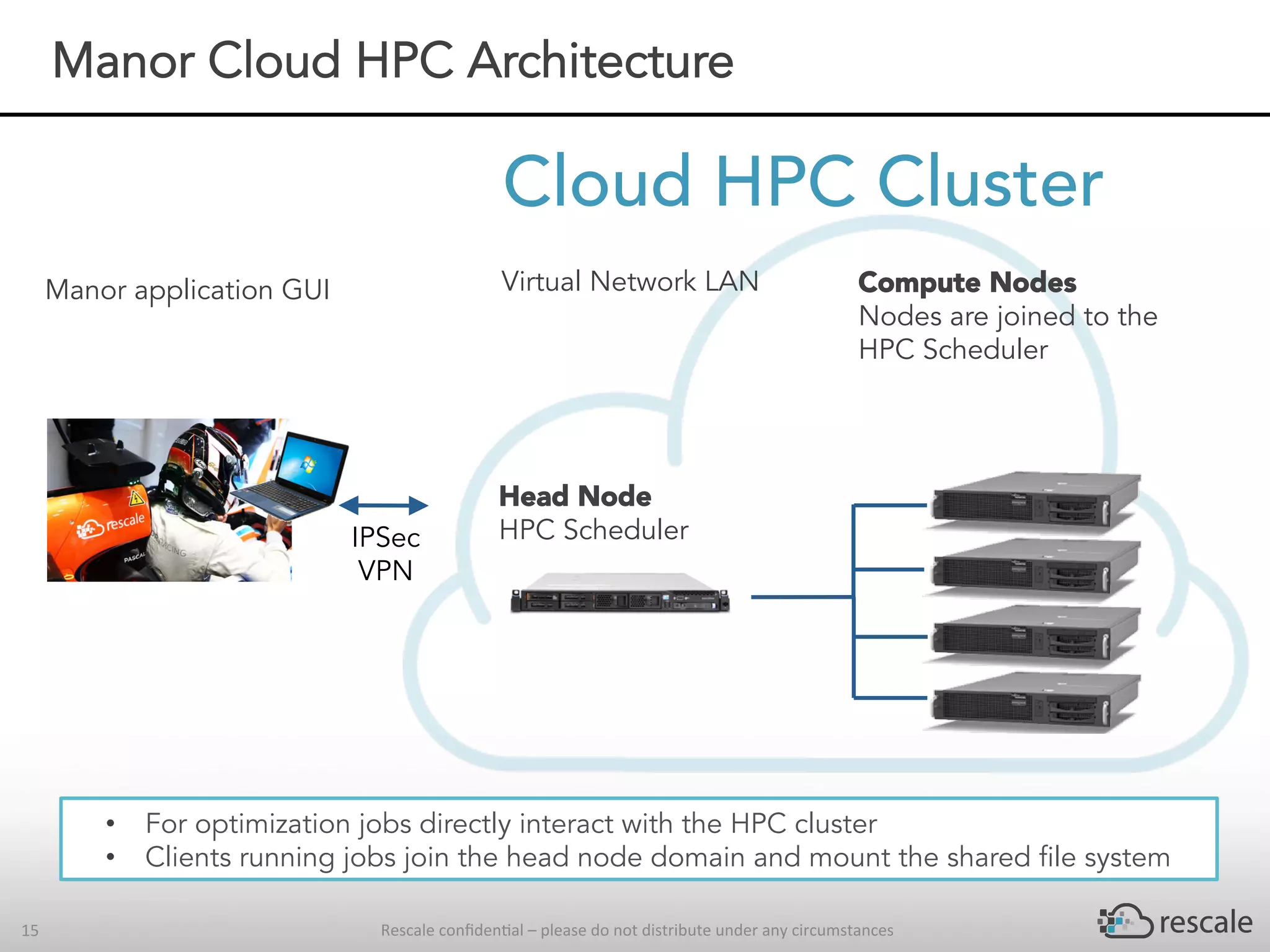
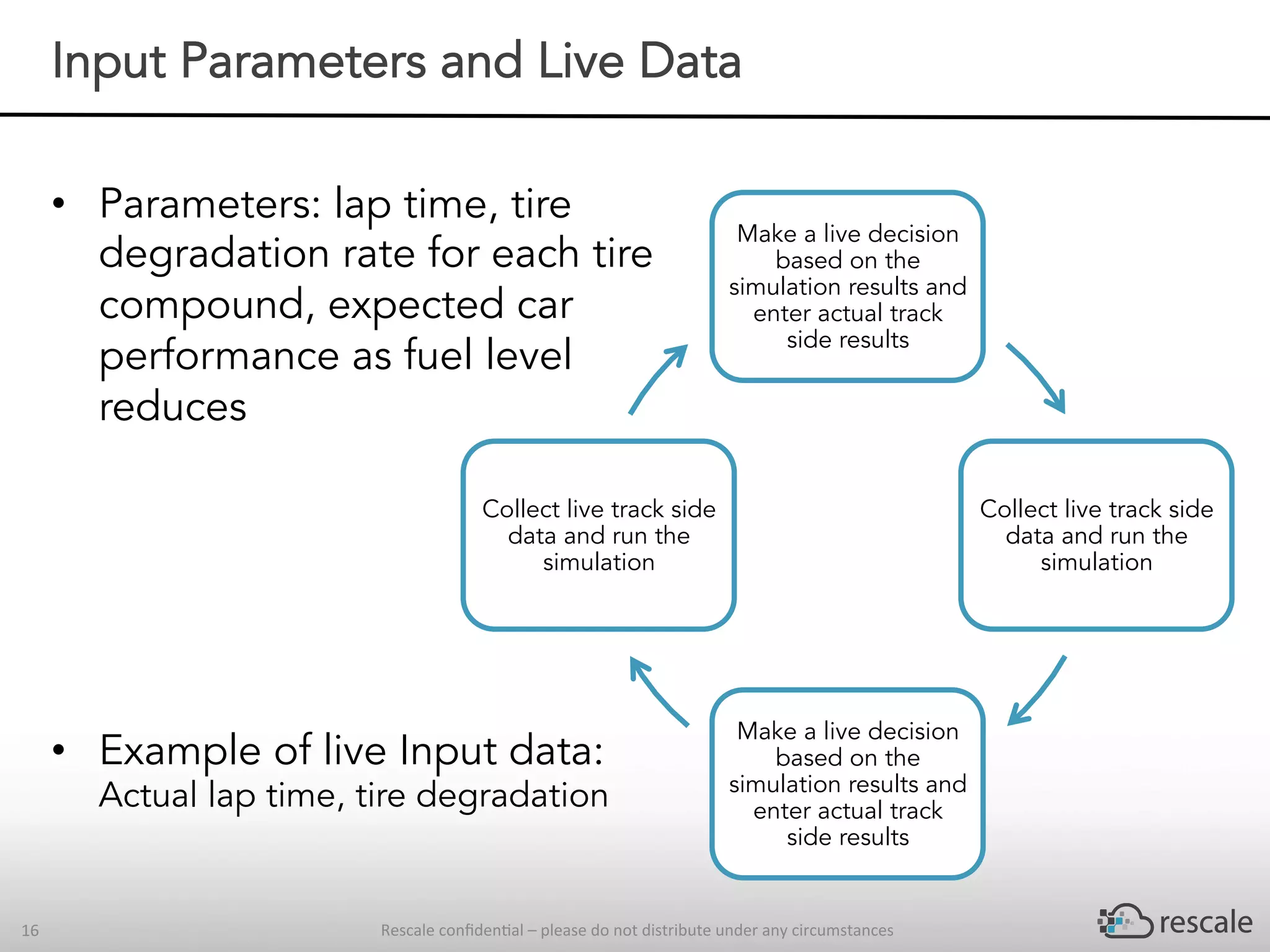
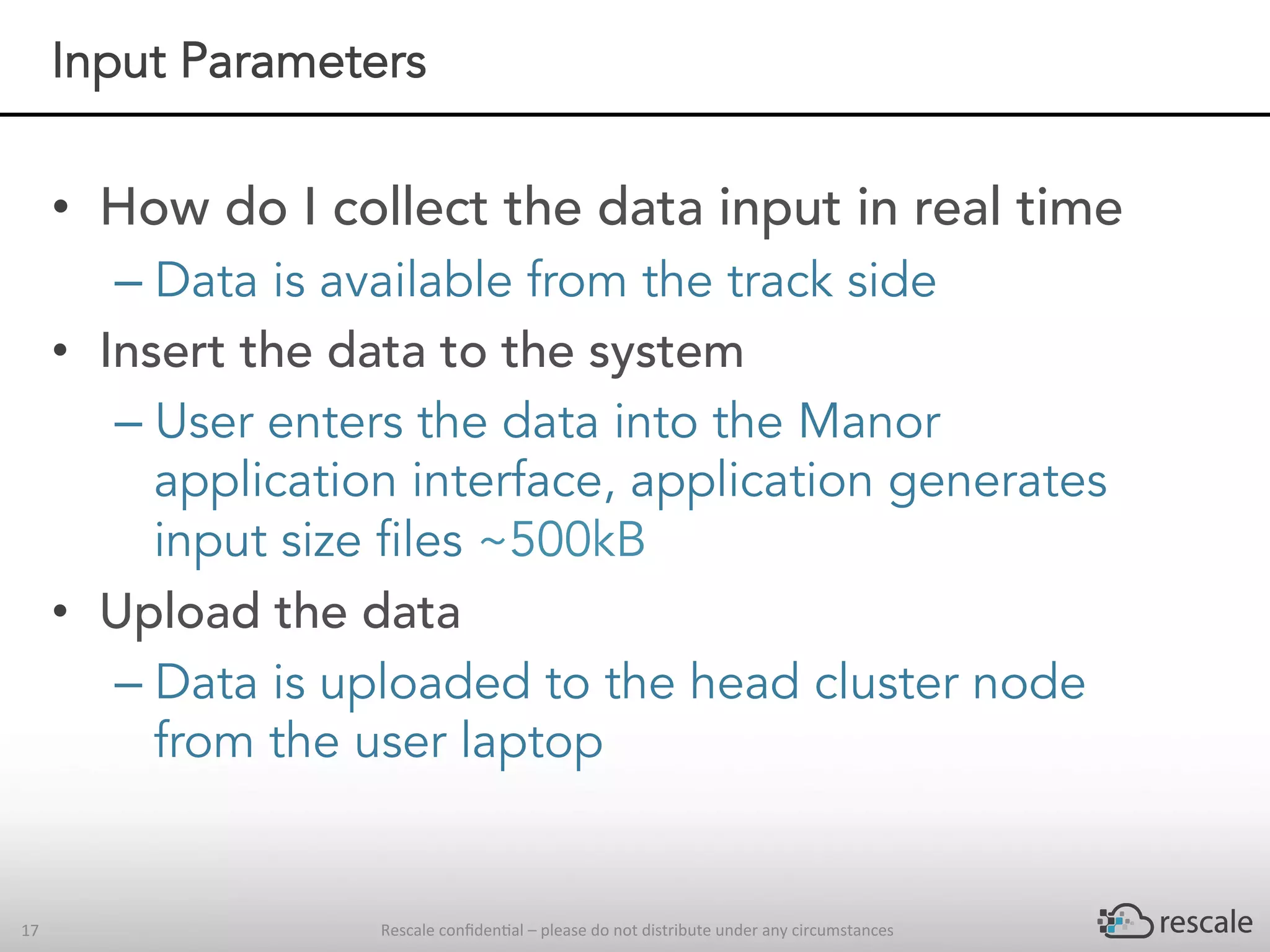

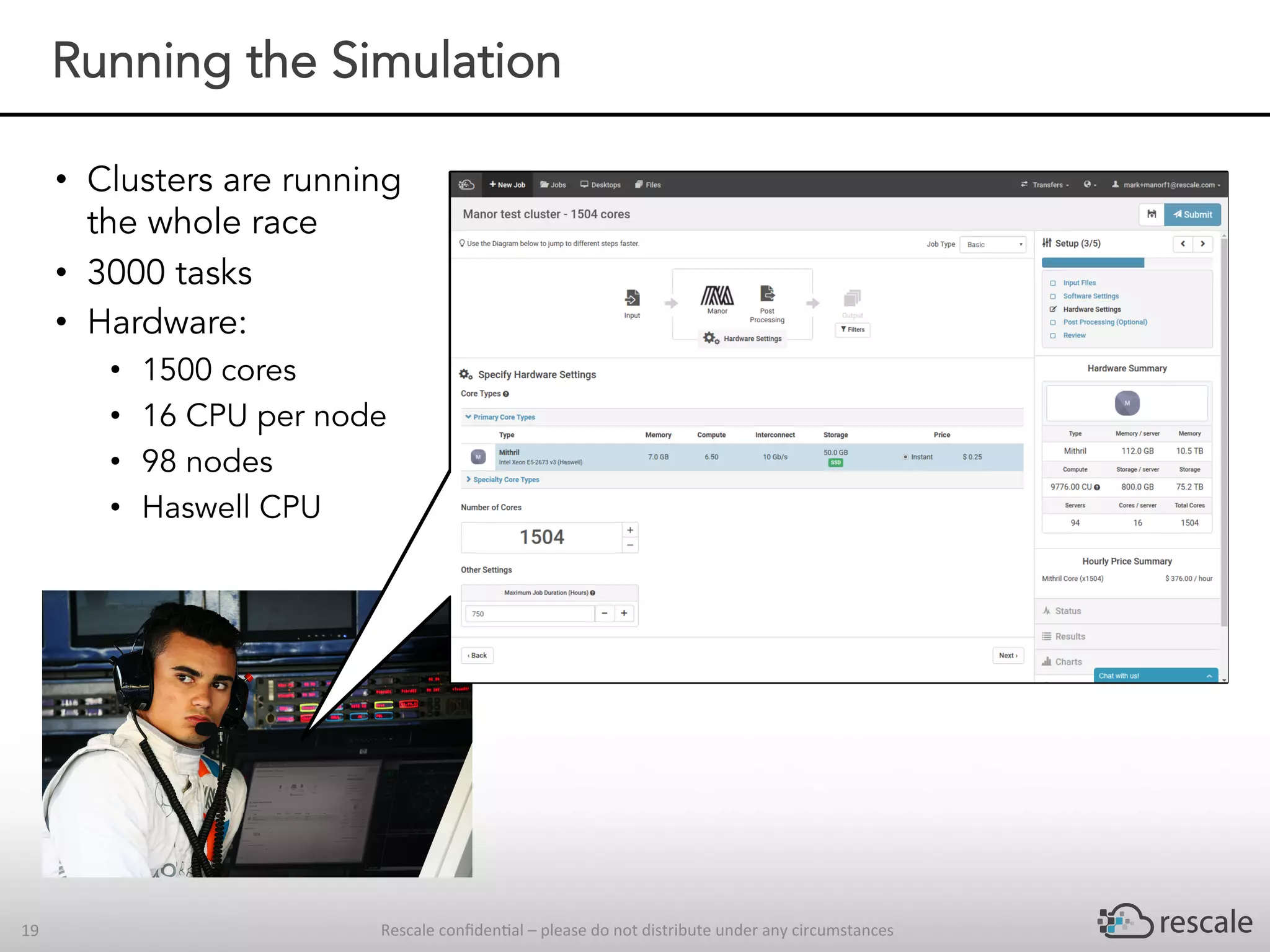

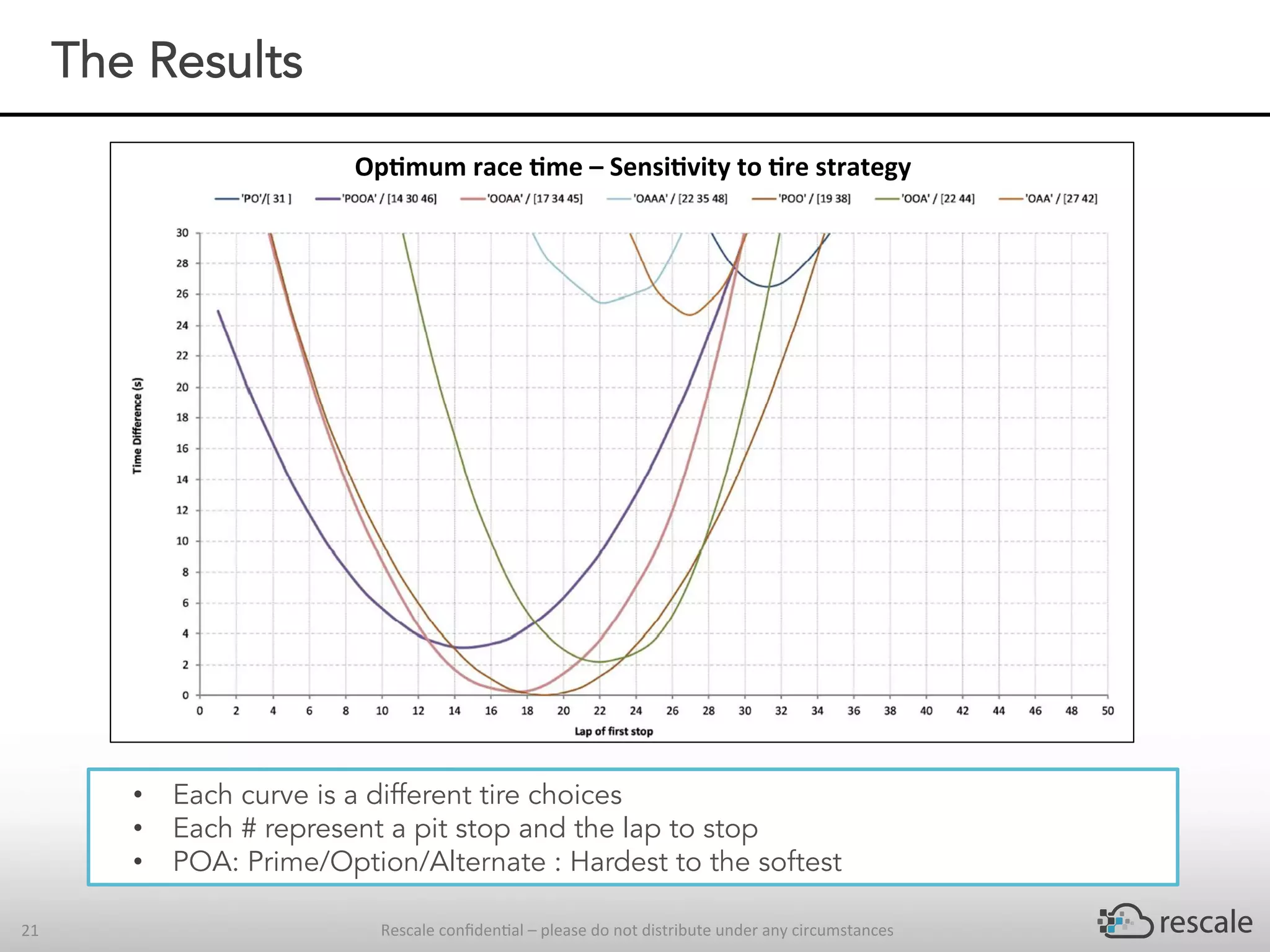


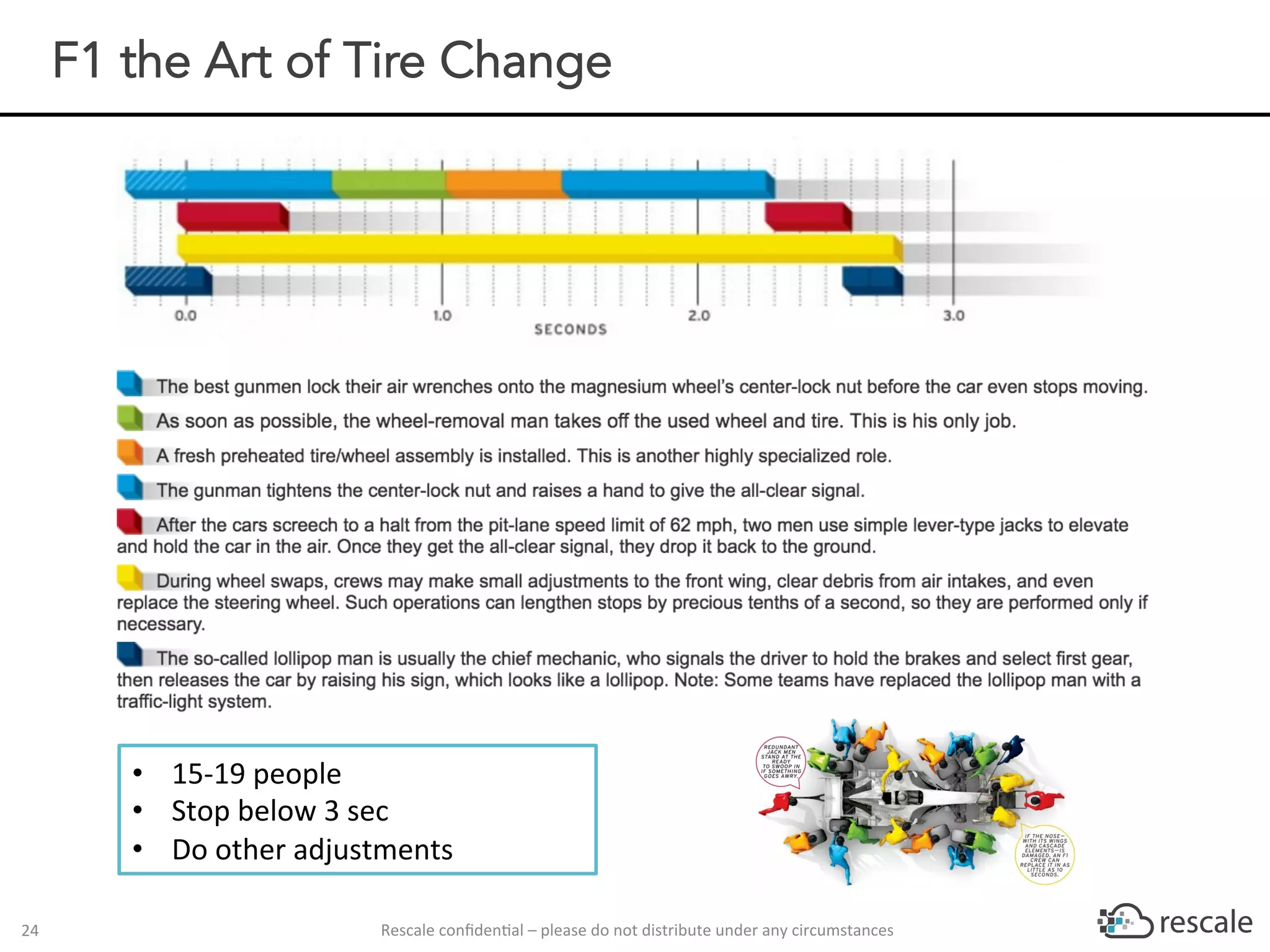


The document outlines the capabilities and advantages of Rescale's cloud HPC platform for real-time decision-making in simulations across various industries, particularly in motorsports like F1 racing. It discusses the importance of simulation in product development and race strategy, detailing how Manor Racing utilizes real-time data and HPC to determine optimal pit stop strategies. Additionally, it highlights the evolution of automotive simulations and technical requirements for successful implementation in racing scenarios.


























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















