








































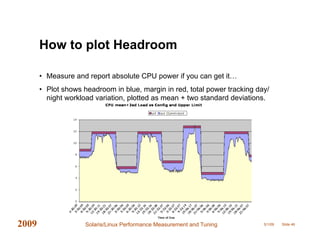
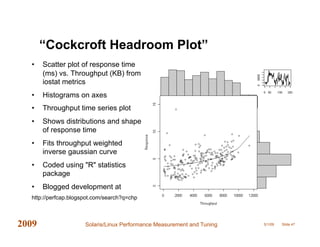



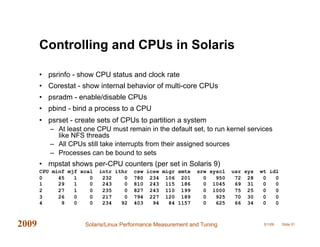






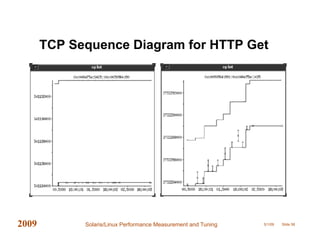












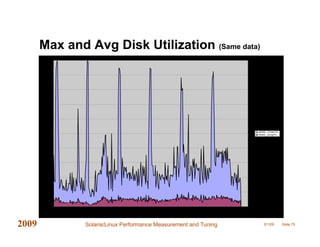







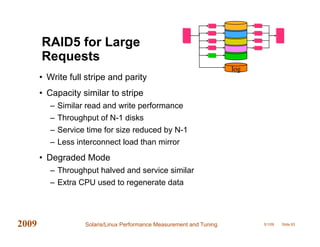
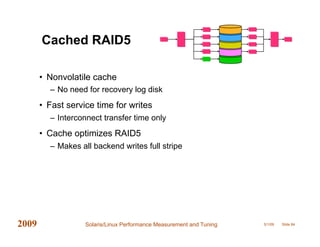














This document provides an overview of performance measurement and tuning techniques for Solaris and Linux systems, focusing on capacity planning, workload analysis, and metric evaluation. It highlights common pitfalls in performance metrics, the significance of various tuning parameters, and the use of free tools for capacity planning. The author, Adrian Cockcroft, draws on over 20 years of experience and offers insights into advanced metrics and system behaviors, with practical advice for optimizing resource utilization.
































![Workload design[1]](https://cdn.slidesharecdn.com/ss_thumbnails/workloaddesign1-130603070133-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






















































