Download to read offline



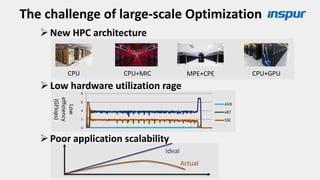

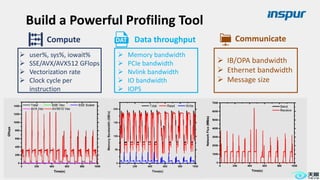


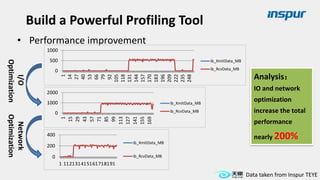
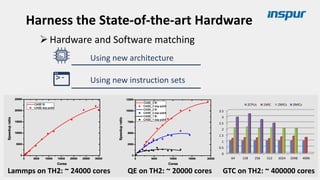
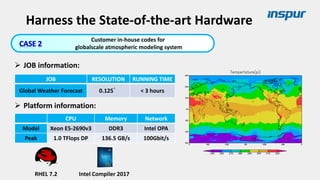
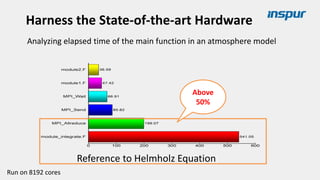
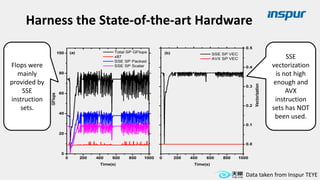
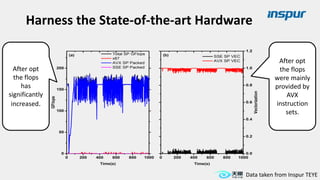
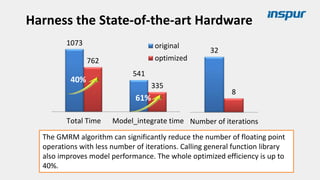
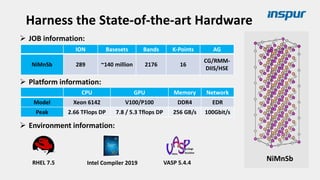
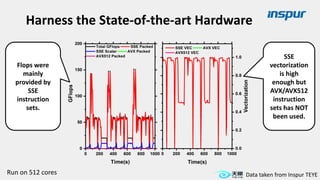
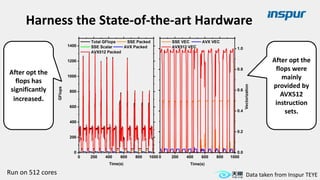
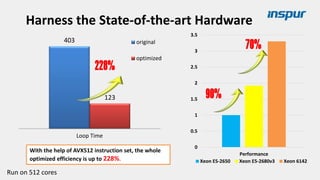
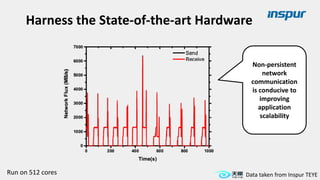
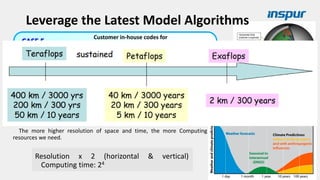
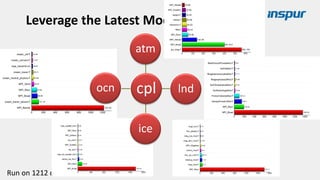
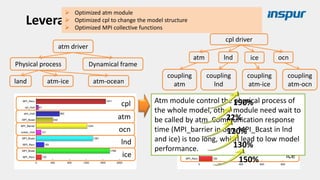
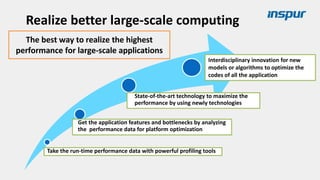



Large-scale optimization strategies for typical HPC workloads include: 1) Building a powerful profiling tool to analyze application performance and identify bottlenecks like inefficient instructions, memory bandwidth, and network utilization. 2) Harnessing state-of-the-art hardware like new CPU architectures, instruction sets, and accelerators to maximize application performance. 3) Leveraging the latest algorithms and computational models that are better suited for large-scale parallelization and new hardware.






















































































