Downloaded 12 times









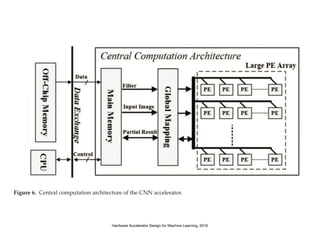
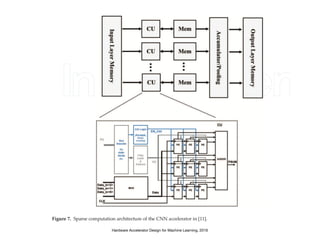

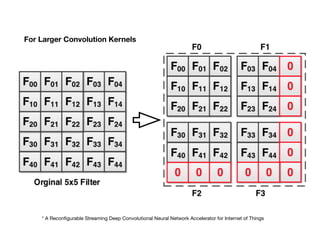
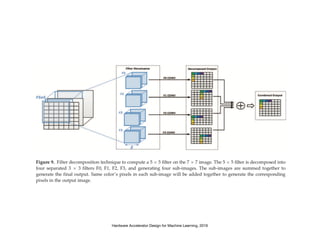

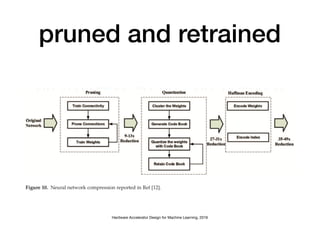
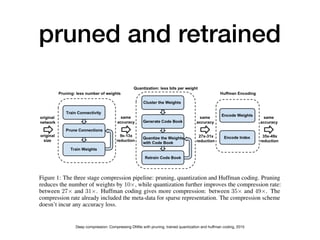

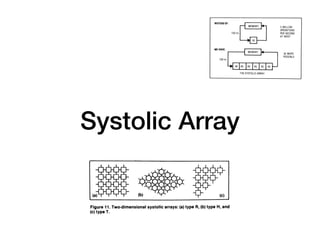






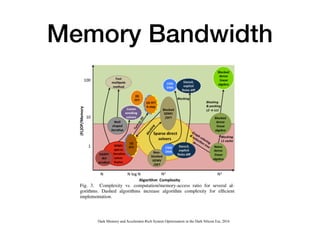





The document discusses various design techniques for deep learning accelerators (DLA). It covers topics such as convolution layers, fully-connected layers, CNN accelerators, filter decomposition, model compression through pruning and retraining, tensor cores, systolic arrays, burst fetching, analog computing, thermal management, memory bandwidth optimization, and zero-copy techniques.
















































































