Downloaded 730 times














val input = new BufferedReader(new InputStreamReader(System.in))
var done = false
while(!done) {
val line = input.readLine()
if(line == null) {
done = true
} else {
val message = line.trim
producer.send(new ProducerData[String, String](topic, message))
println("Sent: %s (%d bytes)".format(line, message.getBytes.length))
}
}
producer.close()
19](https://image.slidesharecdn.com/joe-stein-apache-kafka-120728092925-phpapp01/75/Apache-Kafka-18-2048.jpg)
![Consumer
core/src/main/scala/kafka/consumer/ConsoleConsumer.scala
/**
* Consumer that dumps messages out to standard out.
*/
val connector = Consumer.create(config) //kafka.consumer.ConsumerConnector
val stream = connector.createMessageStreamsByFilter(filterSpec).get(0)
val iter = if(maxMessages >= 0)
stream.slice(0, maxMessages)
else
stream
val formatter: MessageFormatter = messageFormatterClass.newInstance().asInstanceOf[MessageFormatter]
formatter.init(formatterArgs)
try {
for(messageAndTopic <- iter) {
try {
formatter.writeTo(messageAndTopic.message, System.out)
} catch {
case e =>
if (skipMessageOnError)
error("Error processing message, skipping this message: ", e)
else
throw e
}
if(System.out.checkError()) {
// This means no one is listening to our output stream any more, time to shutdown
System.err.println("Unable to write to standard out, closing consumer.")
formatter.close()
connector.shutdown()
System.exit(1)
}
}
} catch {
20
case e => error("Error processing message, stopping consumer: ", e)](https://image.slidesharecdn.com/joe-stein-apache-kafka-120728092925-phpapp01/75/Apache-Kafka-19-2048.jpg)



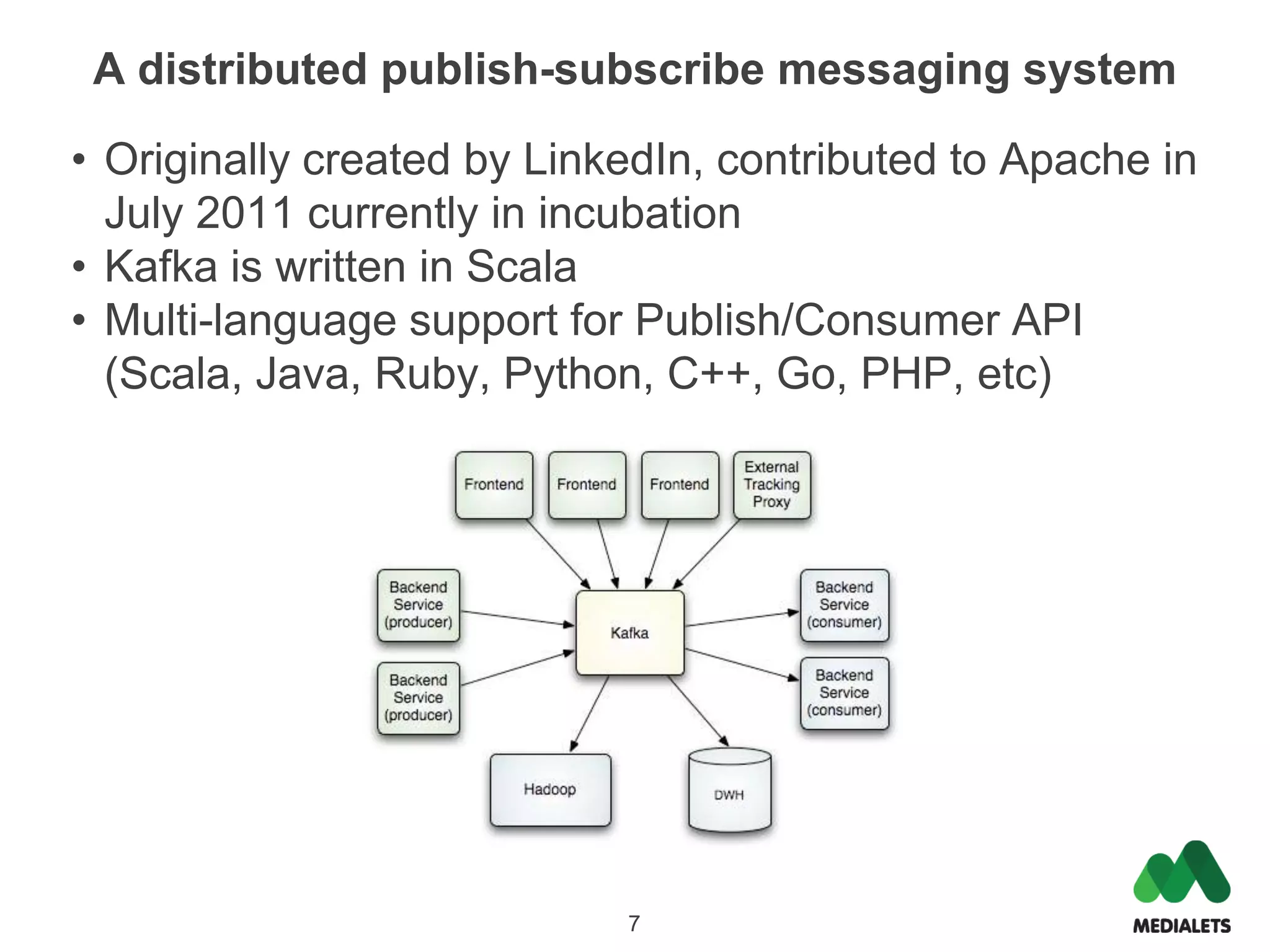
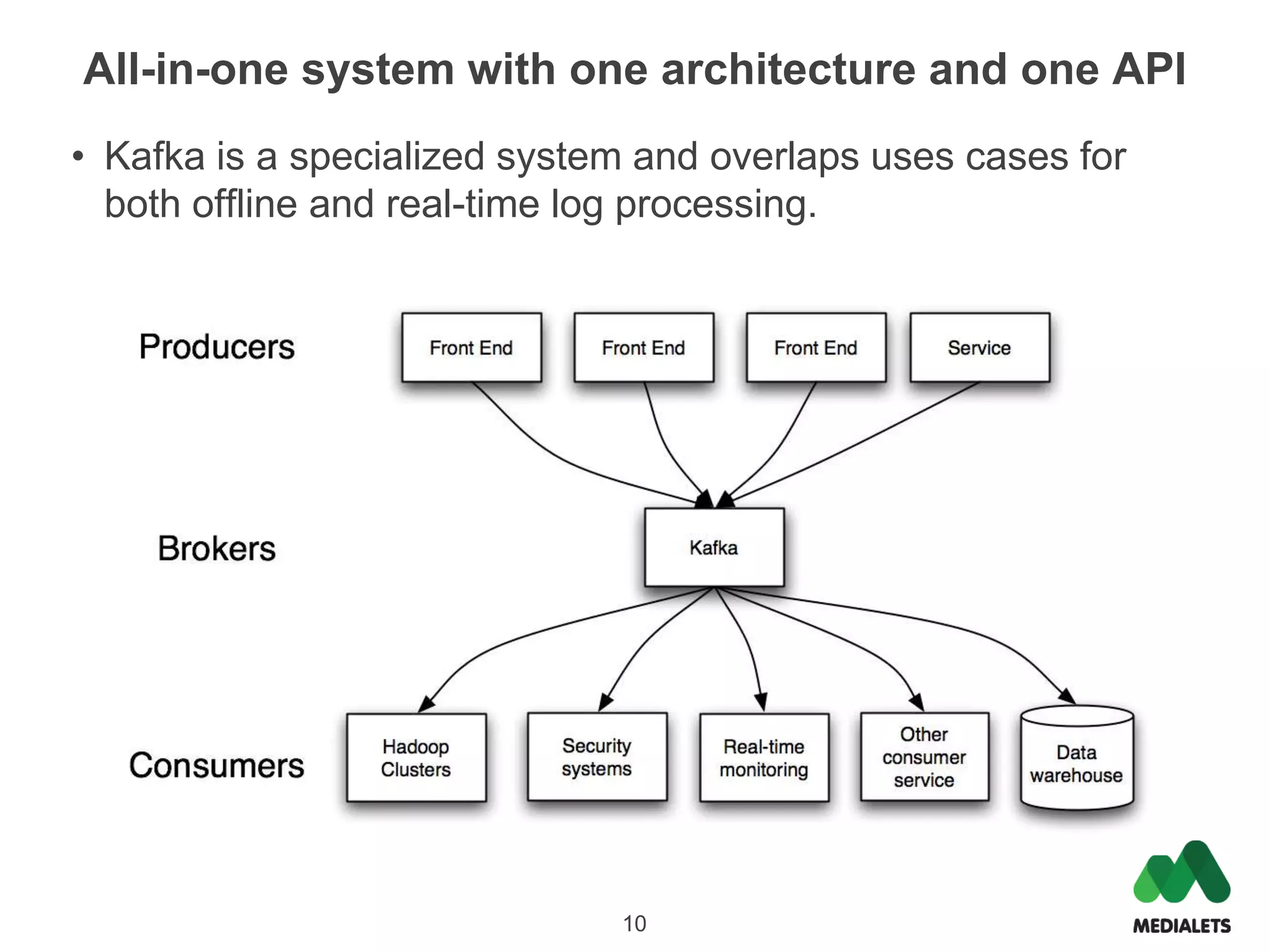
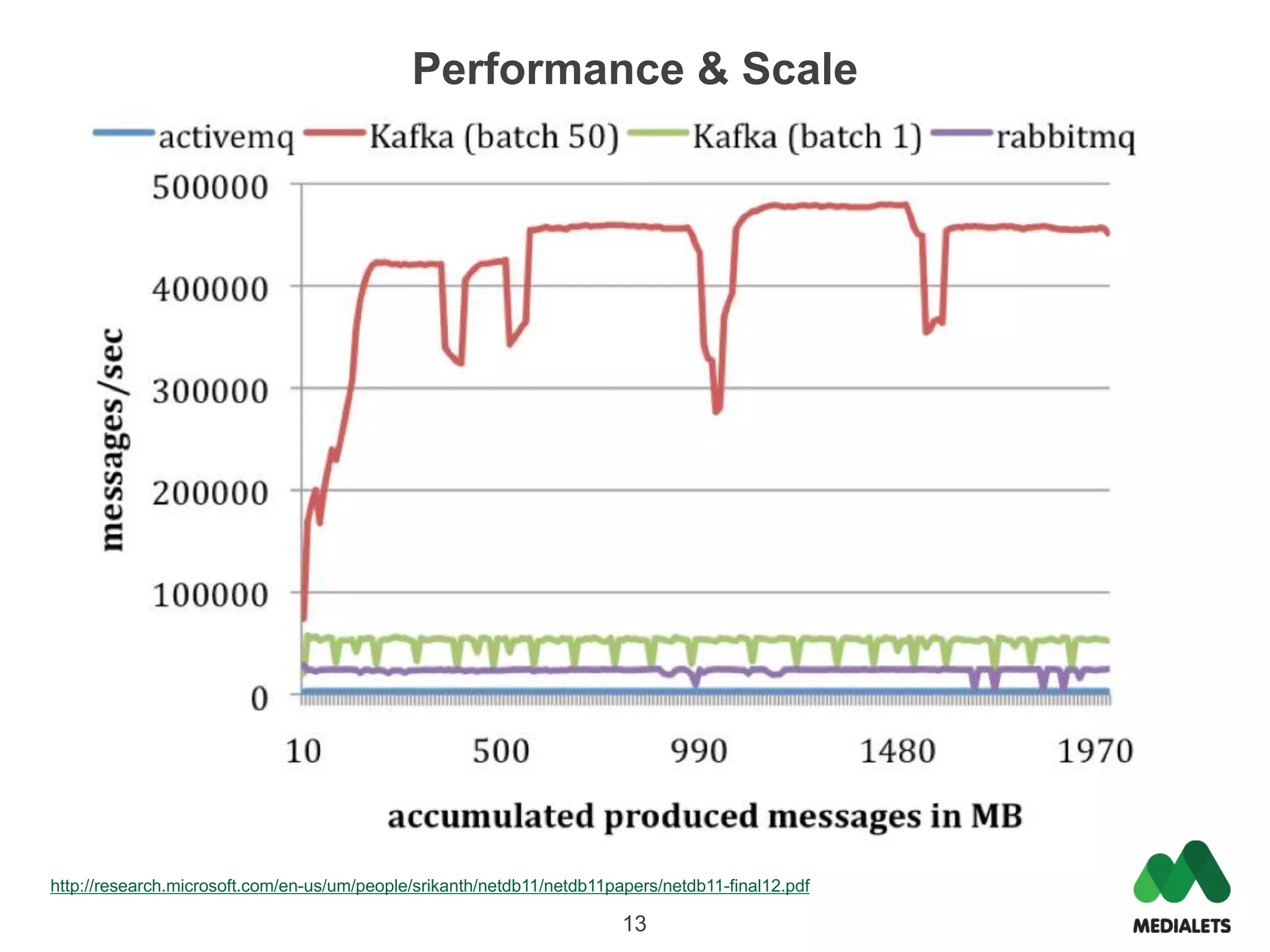
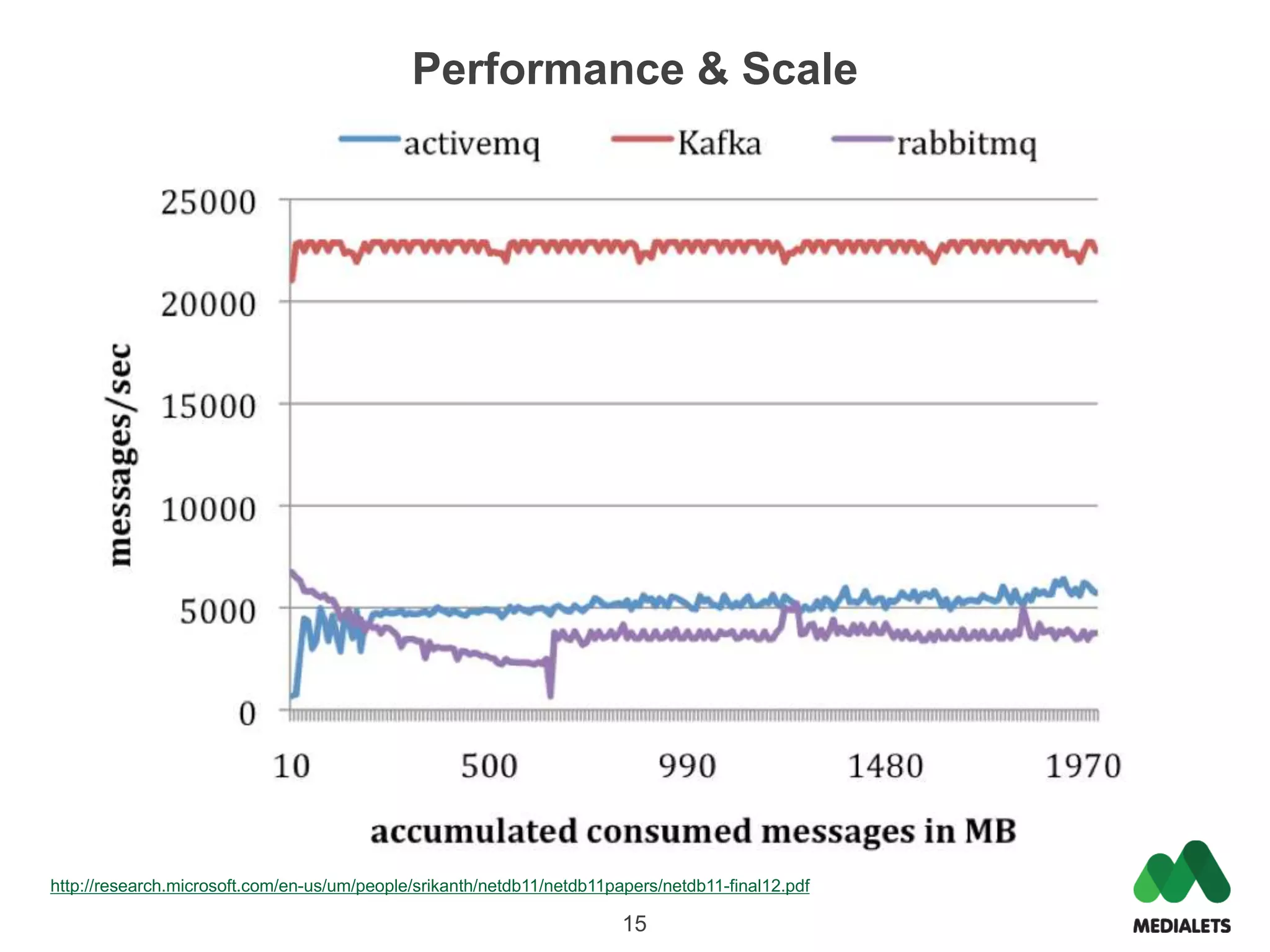
Apache Kafka is a distributed publish-subscribe messaging system that was originally created by LinkedIn and contributed to the Apache Software Foundation. It is written in Scala and provides a multi-language API to publish and consume streams of records. Kafka is useful for both log aggregation and real-time messaging due to its high performance, scalability, and ability to serve as both a distributed messaging system and log storage system with a single unified architecture. To use Kafka, one runs Zookeeper for coordination, Kafka brokers to form a cluster, and then publishes and consumes messages with a producer API and consumer API.































































































![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)



![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)


