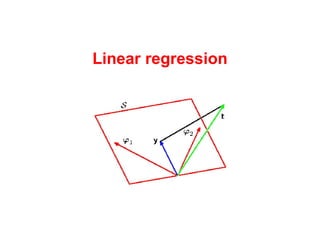
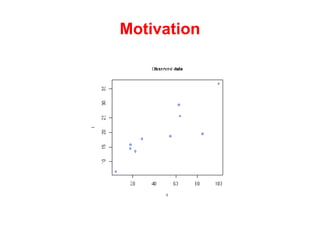
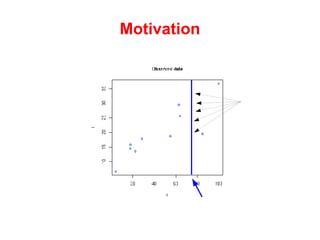
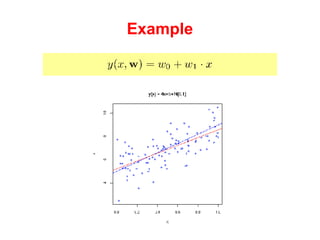
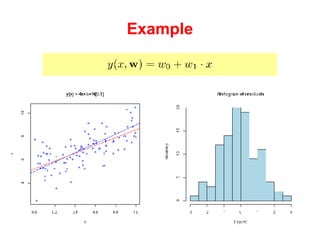
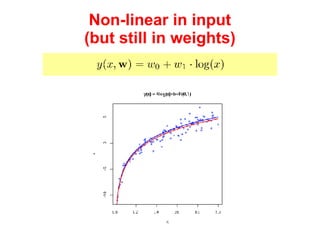
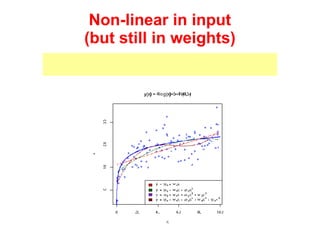
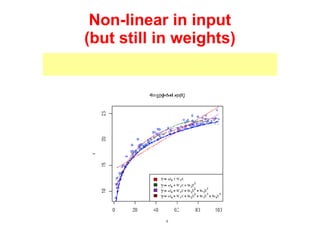
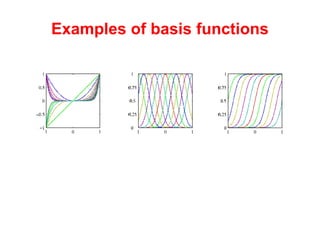
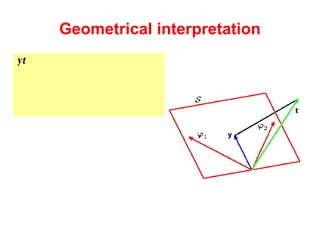
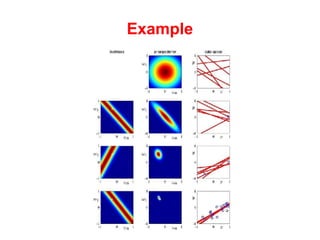
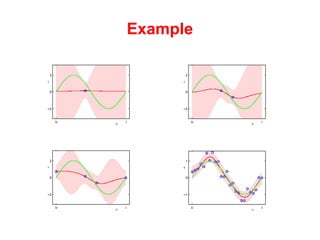
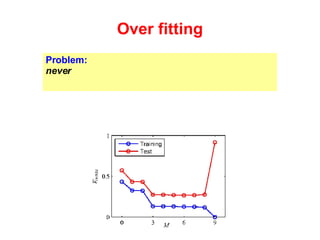
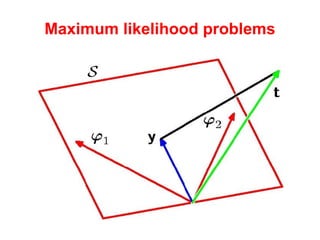
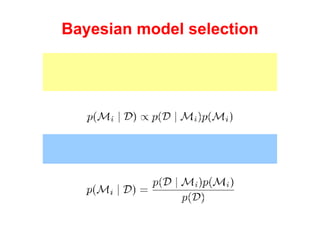
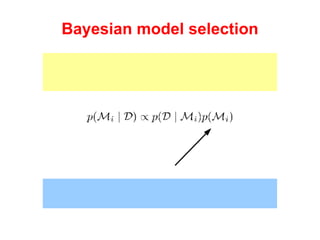
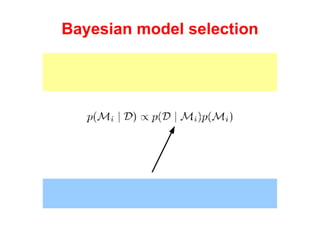
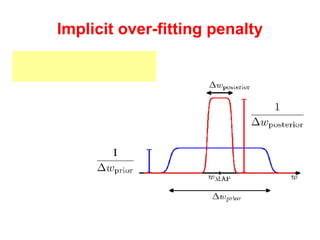
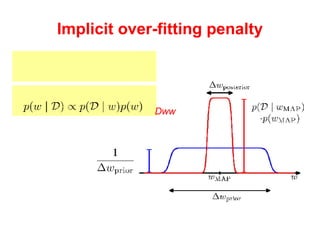
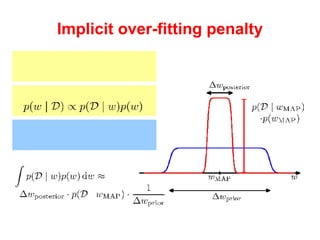
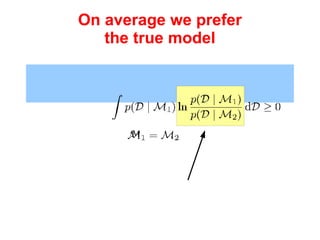
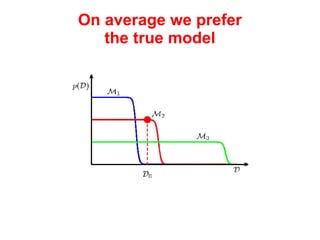
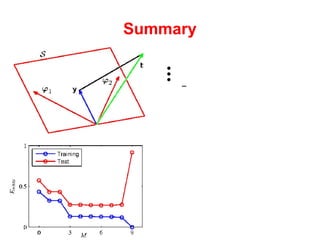
The document discusses linear regression machine learning models. It describes modeling data using a linear Gaussian distribution and estimating the model parameters using maximum likelihood or Bayesian methods. Bayesian estimation avoids the overfitting problems of maximum likelihood estimation by implicitly penalizing models that overfit the data. However, Bayesian methods can still be affected by using an incorrectly specified model.