Overview of ParallelHardware
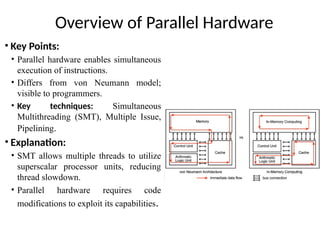
• Key Points:
• Parallel hardware enables simultaneous
execution of instructions.
• Differs from von Neumann model;
visible to programmers.
• Key techniques: Simultaneous
Multithreading (SMT), Multiple Issue,
Pipelining.
• Explanation:
• SMT allows multiple threads to utilize
superscalar processor units, reducing
thread slowdown.
• Parallel hardware requires code
modifications to exploit its capabilities.
3.
Flynn’s Taxonomy
• KeyPoints:
• Classifies parallel computers by
instruction and data streams.
• Types:
• SISD: Single Instruction, Single Data
(von Neumann).
• SIMD: Single Instruction, Multiple
Data.
• MIMD: Multiple Instruction, Multiple
Data.
• Explanation:
• SIMD: Same instruction applied to
multiple data items.
• MIMD: Independent instruction
streams on multiple data.
4.
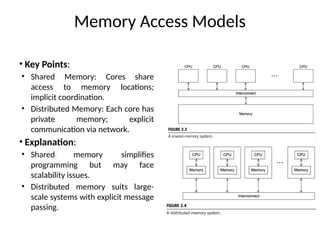
Memory Access Models
•Key Points:
• Shared Memory: Cores share
access to memory locations;
implicit coordination.
• Distributed Memory: Each core has
private memory; explicit
communication via network.
• Explanation:
• Shared memory simplifies
programming but may face
scalability issues.
• Distributed memory suits large-
scale systems with explicit message
passing.
5.
SIMD Systems
• KeyPoints:
• Single control unit broadcasts
instructions to multiple datapaths.
• Ideal for data-parallel problems
(e.g., vector addition).
• Example:
for (i=0; i<n; i++) x[i] += y[i];
• Explanation:
• Datapaths execute synchronously;
idle if instruction not applicable.
• Performance degrades with
conditional operations (e.g., if (y[i] > 0)).
Diagram of SIMD architecture with control unit and datapaths.
6.
Vector Processors
• KeyPoints:
• Operate on arrays/vectors, not scalars.
• Features: Vector registers, vectorized
functional units, interleaved memory,
strided access.
• Explanation:
• Vector registers store 4–256 elements;
operations applied simultaneously.
• High memory bandwidth; efficient for
large, regular data but less scalable.
7.
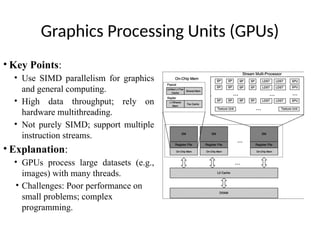
Graphics Processing Units(GPUs)
• Key Points:
• Use SIMD parallelism for graphics
and general computing.
• High data throughput; rely on
hardware multithreading.
• Not purely SIMD; support multiple
instruction streams.
• Explanation:
• GPUs process large datasets (e.g.,
images) with many threads.
• Challenges: Poor performance on
small problems; complex
programming.
8.
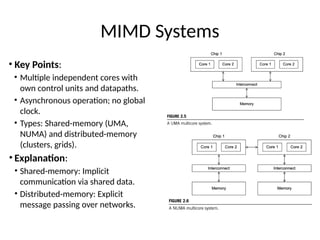
MIMD Systems
• KeyPoints:
• Multiple independent cores with
own control units and datapaths.
• Asynchronous operation; no global
clock.
• Types: Shared-memory (UMA,
NUMA) and distributed-memory
(clusters, grids).
• Explanation:
• Shared-memory: Implicit
communication via shared data.
• Distributed-memory: Explicit
message passing over networks.
9.
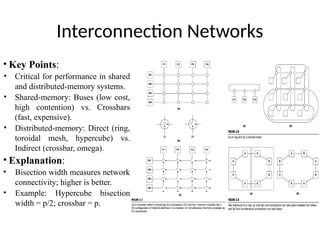
Interconnection Networks
• KeyPoints:
• Critical for performance in shared
and distributed-memory systems.
• Shared-memory: Buses (low cost,
high contention) vs. Crossbars
(fast, expensive).
• Distributed-memory: Direct (ring,
toroidal mesh, hypercube) vs.
Indirect (crossbar, omega).
• Explanation:
• Bisection width measures network
connectivity; higher is better.
• Example: Hypercube bisection
width = p/2; crossbar = p.
10.
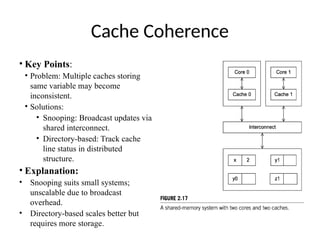
Cache Coherence
• KeyPoints:
• Problem: Multiple caches storing
same variable may become
inconsistent.
• Solutions:
• Snooping: Broadcast updates via
shared interconnect.
• Directory-based: Track cache
line status in distributed
structure.
• Explanation:
• Snooping suits small systems;
unscalable due to broadcast
overhead.
• Directory-based scales better but
requires more storage.
11.
False Sharing
• KeyPoints:
• Occurs when cores access
different variables in the same
cache line.
• Causes unnecessary memory
accesses, degrading performance.
• Example: Parallel loop updating
shared array y[i].
• Explanation:
• Solution: Use local temporary
storage to minimize shared cache
line updates.
• Does not affect correctness, only
performance.
12.
Shared vs. DistributedMemory
• Key Points:
• Shared-memory: Easier to program;
limited by interconnect scalability.
• Distributed-memory: Scales to
thousands of processors; requires
explicit communication.
• Explanation:
• Shared-memory suits smaller
systems; distributed-memory for
large-scale problems.
• Hybrid systems combine both (e.g.,
clusters with shared-memory nodes).
13.
Parallel Software Challenges
•Key Points:
• Parallel hardware is widespread
(multicore CPUs, GPUs).
• Software lags: Many programs are
single-threaded; programmers lack
parallel expertise.
• Terminology: Threads (shared-
memory) vs. Processes (distributed-
memory).
• Explanation:
• Developers must write parallel code to
leverage hardware.
• Requires understanding of
shared/distributed architectures and
SIMD/MIMD systems.

![SIMD Systems
• Key Points:
• Single control unit broadcasts
instructions to multiple datapaths.
• Ideal for data-parallel problems
(e.g., vector addition).
• Example:
for (i=0; i<n; i++) x[i] += y[i];
• Explanation:
• Datapaths execute synchronously;
idle if instruction not applicable.
• Performance degrades with
conditional operations (e.g., if (y[i] > 0)).
Diagram of SIMD architecture with control unit and datapaths.](https://image.slidesharecdn.com/parallelcomputingmodule1parta-250805065248-554a4926/85/Parallel-Computing-Module-1-Part-A-VTU-PPT-5-320.jpg)

![False Sharing
• Key Points:
• Occurs when cores access
different variables in the same
cache line.
• Causes unnecessary memory
accesses, degrading performance.
• Example: Parallel loop updating
shared array y[i].
• Explanation:
• Solution: Use local temporary
storage to minimize shared cache
line updates.
• Does not affect correctness, only
performance.](https://image.slidesharecdn.com/parallelcomputingmodule1parta-250805065248-554a4926/85/Parallel-Computing-Module-1-Part-A-VTU-PPT-11-320.jpg)





































































