




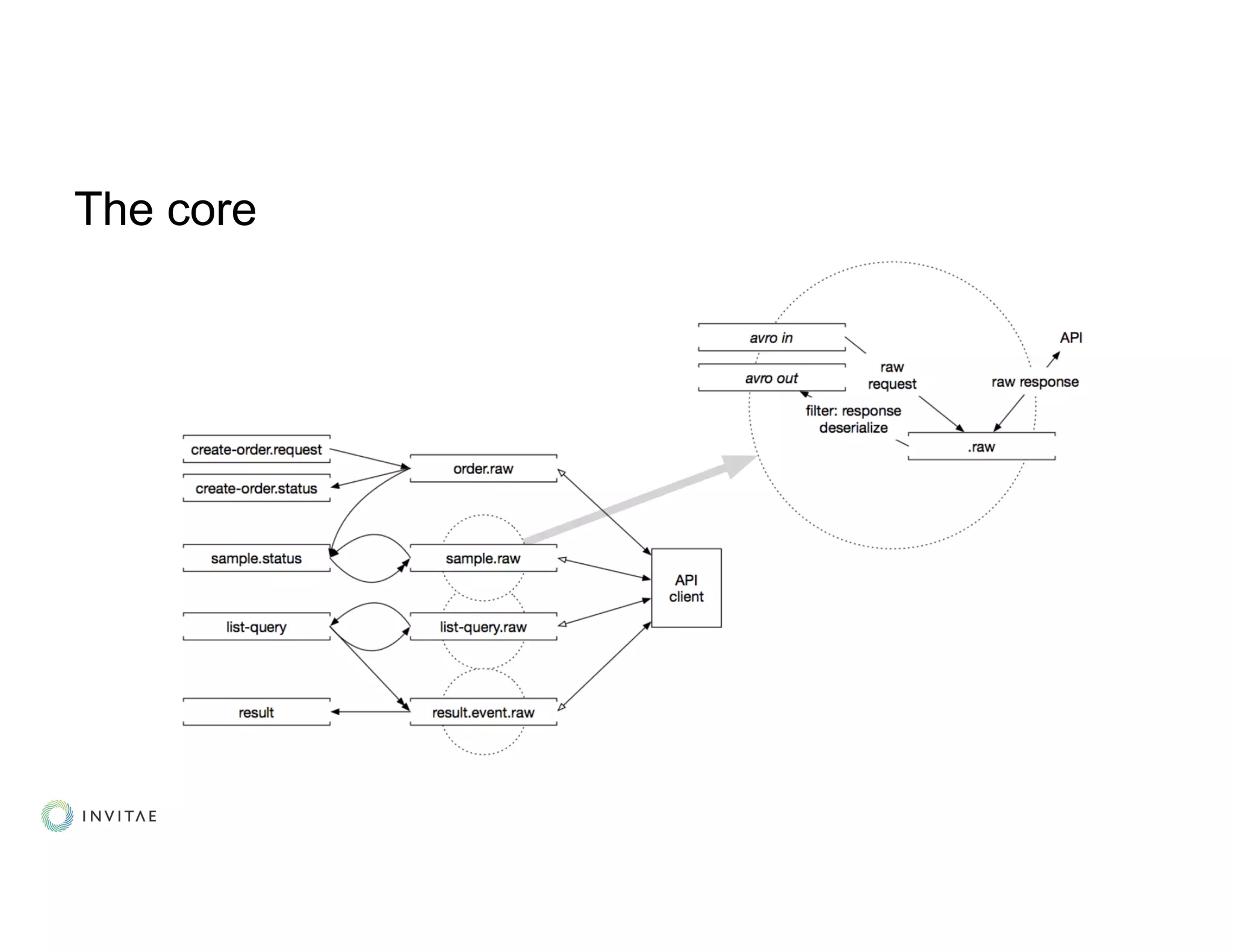




: KStream[K,V] fixes K,V
● Having to think about (de)serializers: never!
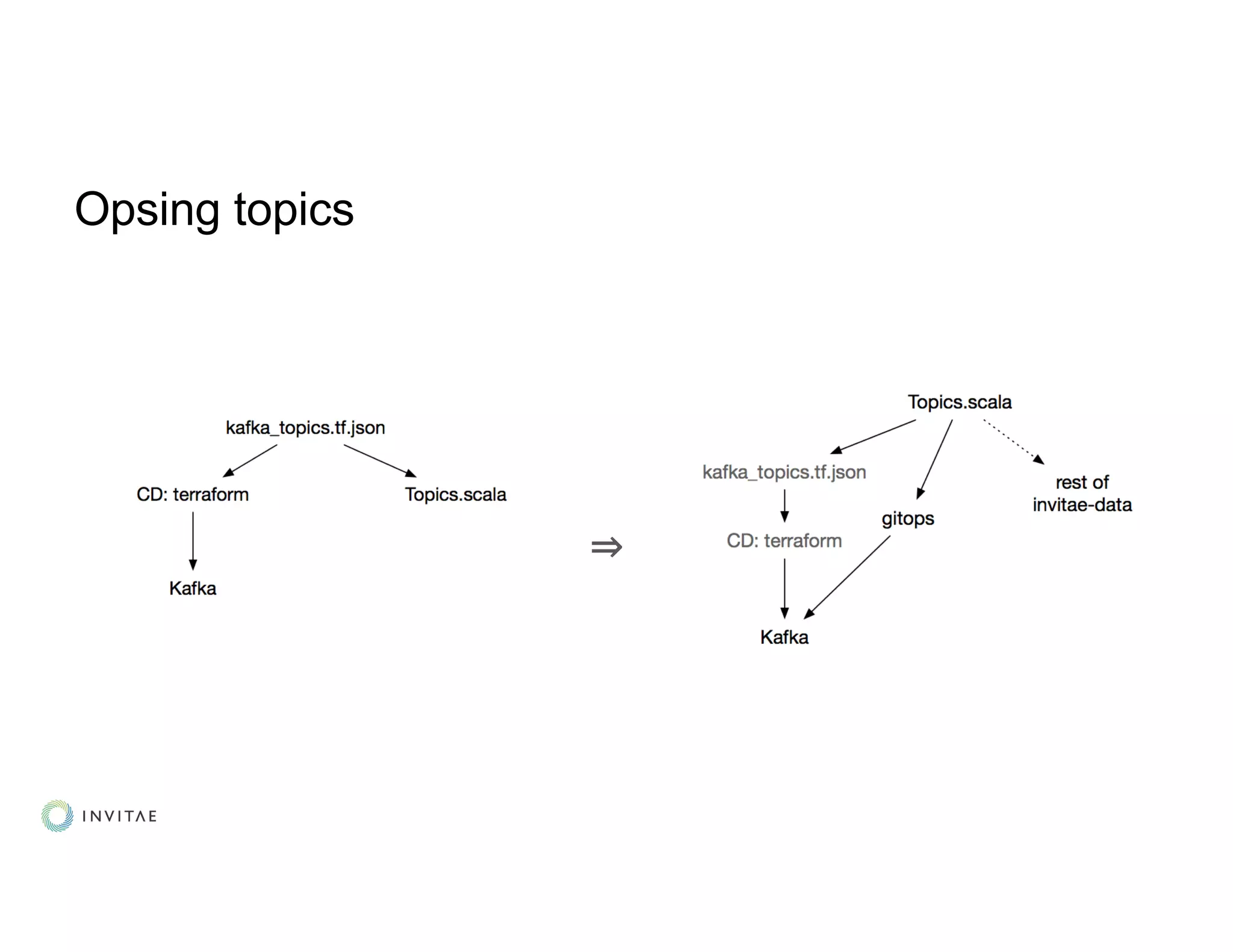
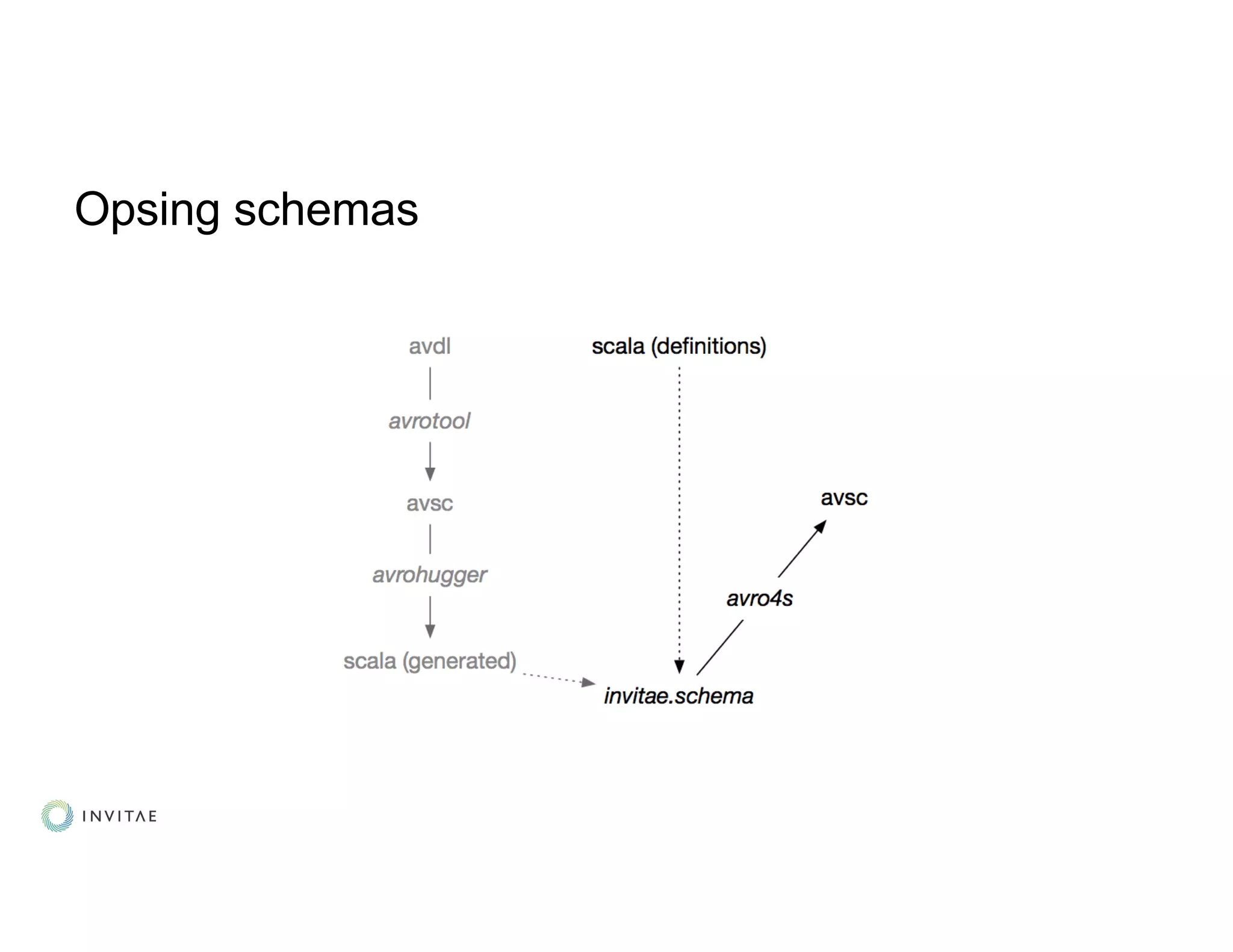
● Topic creation, schema registration and compatibility checks: automated!](https://image.slidesharecdn.com/kouznetsovalexander-191007040149/75/From-Zero-to-Streaming-Healthcare-in-Production-Alexander-Kouznetsov-Invitae-Kafka-Summit-SF-2019-16-2048.jpg)


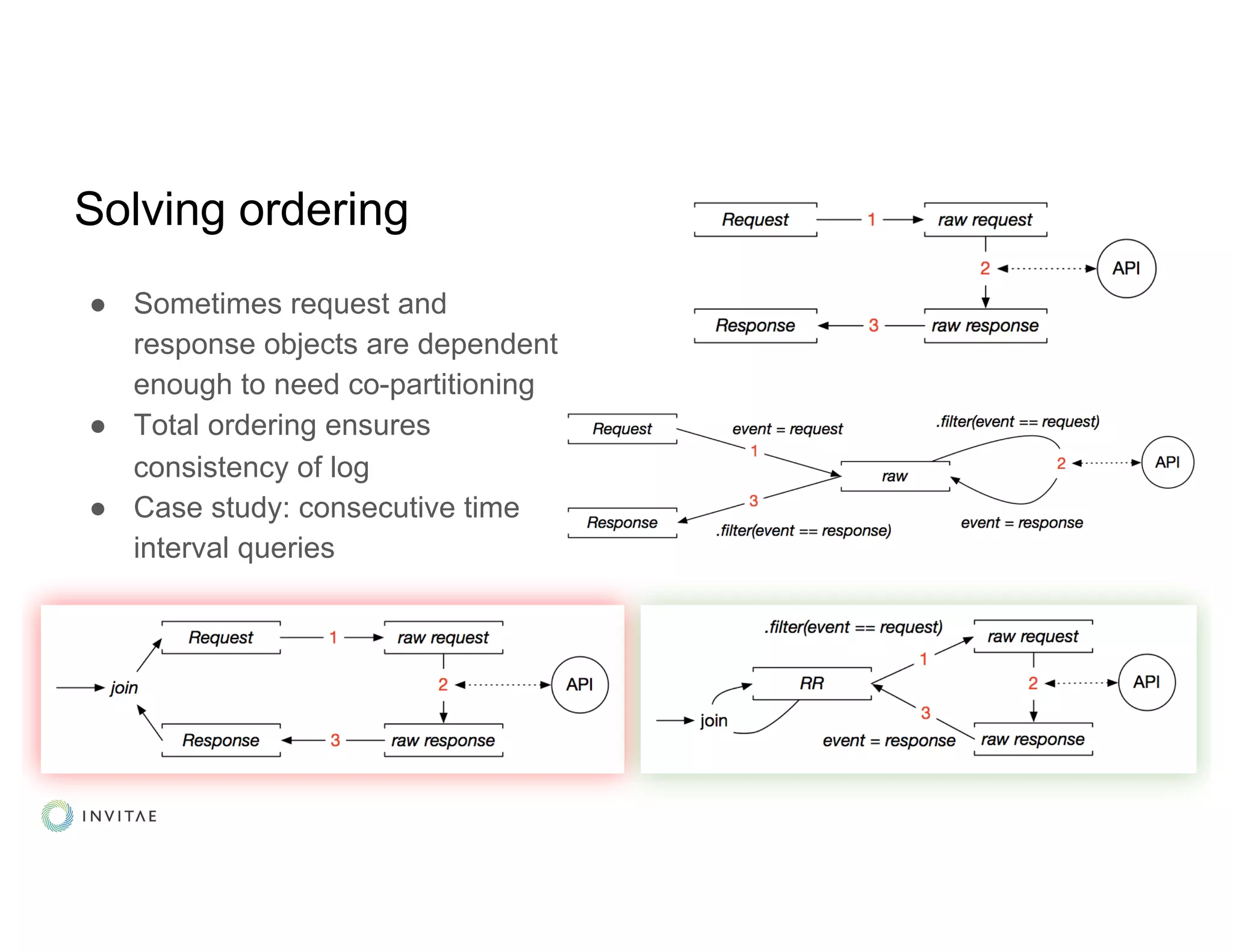











This document provides an overview of a company's first Kafka Streams project to build a streaming data pipeline. Some key lessons learned include adopting a data-first mindset where the data defines the application behavior and architecture. All business logic is modeled as data transformations. Testing was done using TopologyTestDriver for unit tests and emulators for external systems. Kafka Streams was determined to be a good fit as it provided an ordered, fault-tolerant processing pipeline with exactly-once guarantees. Future work includes open sourcing components and improving the declarative side effect handling in the KStreams DSL.























































































