This document discusses strategies for efficiently loading and transforming large datasets in PostgreSQL for analytics use cases. It presents several case studies:
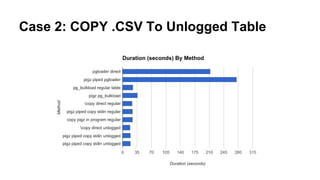
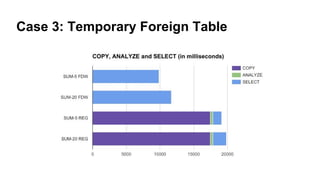
1) Loading a large CSV file - different methods like pgloader, COPY, and temporary foreign tables are compared. Temporary foreign tables perform best when filtering columns.
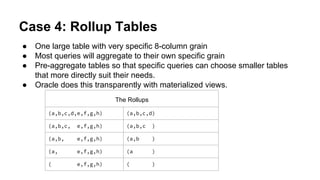
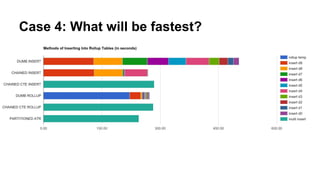
2) Pre-aggregating ("rolling up") data into multiple tables at different granularities for optimized querying. Chained INSERTs and CTEs are more efficient than individual inserts.
3) Creating a "dumb rollup table" using GROUPING SETS to pre-aggregate into a single temp table and insert into final tables in one pass. This outperforms multiple round trips or inserts.















![Case 1: Confession 2: Format Discovery
Same as before, but use plpythonu
CREATE OR REPLACE FUNCTION get_header(file_name text)
RETURNS text[]
LANGUAGE PLPYTHONU STRICT SET SEARCH_PATH FROM CURRENT
AS $PYTHON$
import gzip
with gzip.GzipFile(file_name,'rb') as g:
header = g.readline()
if not header:
return None
return header.rstrip().split(',')
$PYTHON$;](https://image.slidesharecdn.com/etlconfessions-pgconfus2017-170420231627/85/Etl-confessions-pg-conf-us-2017-16-320.jpg)






















































![[EPPG] Oracle to PostgreSQL, Challenges to Opportunity](https://cdn.slidesharecdn.com/ss_thumbnails/eppg-oracletopostgresqlchallengestoopportunity-190409033058-thumbnail.jpg?width=640&height=640&fit=bounds)
















![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)














