Download to read offline



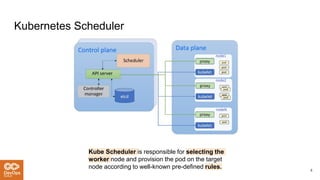
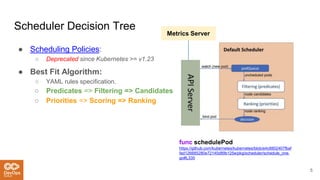





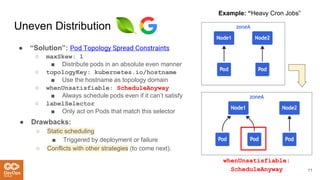
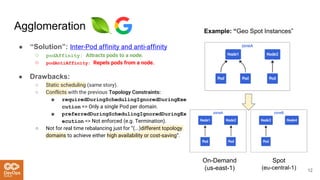



The document provides an overview of the Kubernetes scheduler, including its architecture and decision-making processes like the best fit algorithm for job scheduling. It discusses challenges such as uneven distribution of pods and the complexities involved in achieving optimal scheduling, highlighted as an NP-complete problem. Key takeaways suggest that while Kubernetes is useful for steady workloads, it poses reliability issues and lacks a one-size-fits-all solution.



































































