Download as PDF, PPTX

































![/ 5638
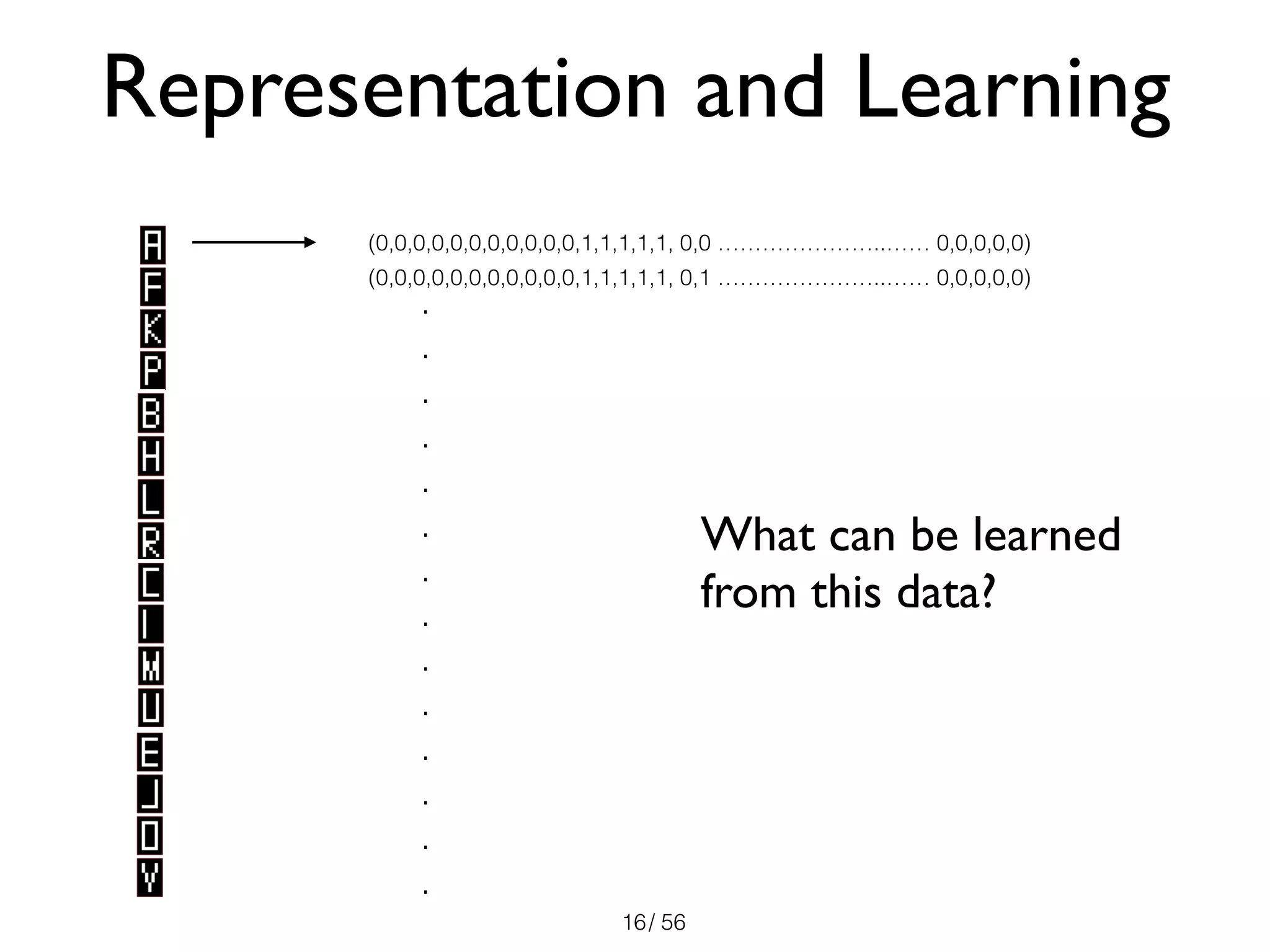
Estimating the distributions
• Use training data to estimate the prior and the
class-conditional distributions
✴ MNIST dataset: 60K training data, 10K test data
• Estimating the is easy:
• From MNIST:
• But estimating the is difficult!
⇡j = Pr[y = j]
Pj(x) = P(x | y = j)
⇡j
Pj(x)
ˆ⇡j =
nj
n
=
# of examples of class j
total # of examples
j 0 1 2 3 4 5 6 7 8 9
ˆ⇡j (%) 9.87 11.24 9.93 10.22 9.74 9.03 9.86 10.44 9.75 9.92
Source: Umesh Vazirani
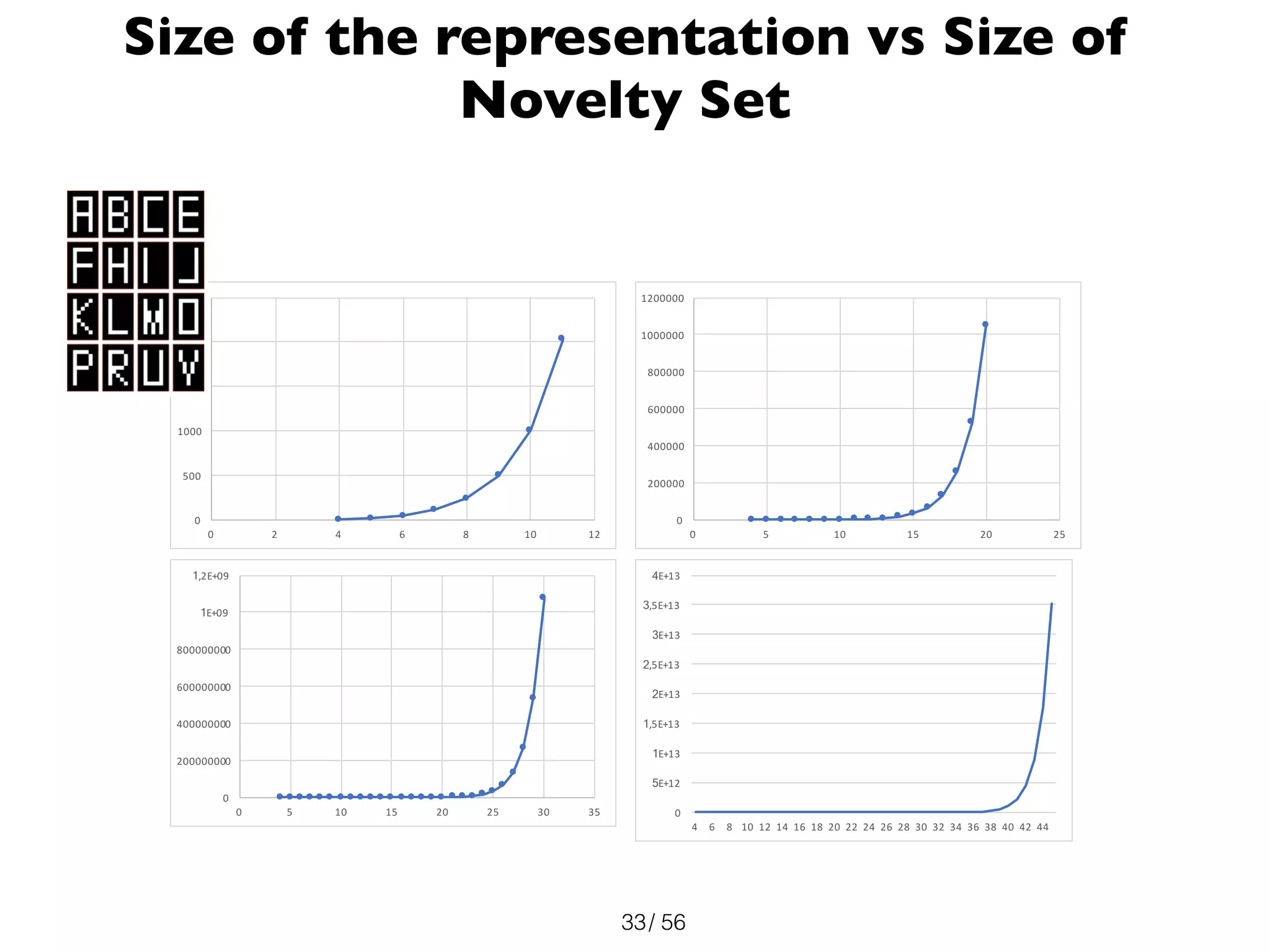
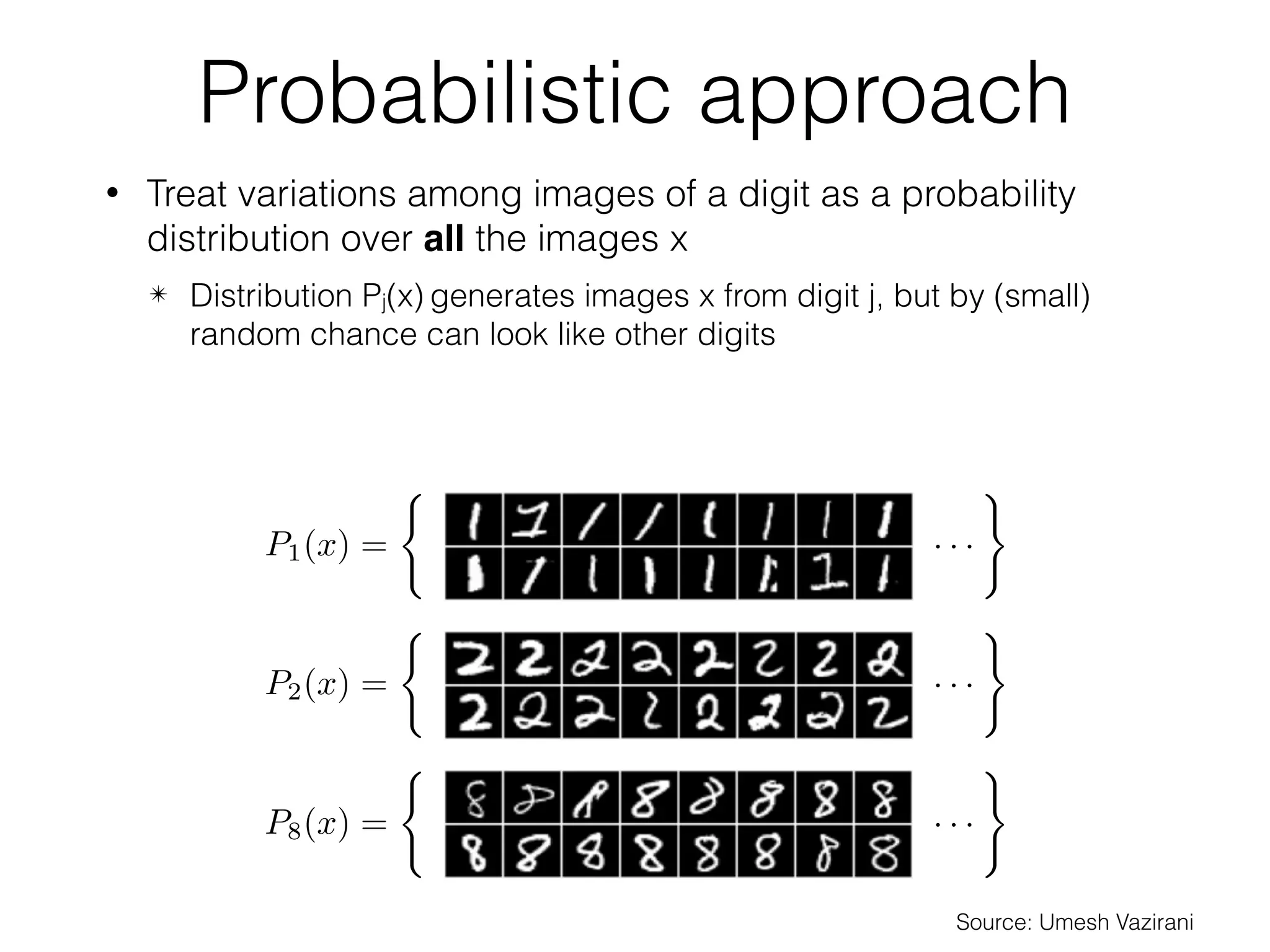
Naive Bayes
• Convert grayscale images to binary
• A general distribution over has parameters
threshold binary data
x 2 {0, 1}784
{0, 1}784
2784
1
• Assume that within each class, the individual pixel values
are independent:
• Each is a coin flip: easy to estimate!
• Now only have 784 parameters to learn
Pj(x) = Pj1(x1) · Pj2(x2) · · · Pj,784(x784)
Pji
Source: Umesh Vazirani](https://image.slidesharecdn.com/coursintrogenerative-180205085929/75/Learning-Representations-Generative-modelling-38-2048.jpg)






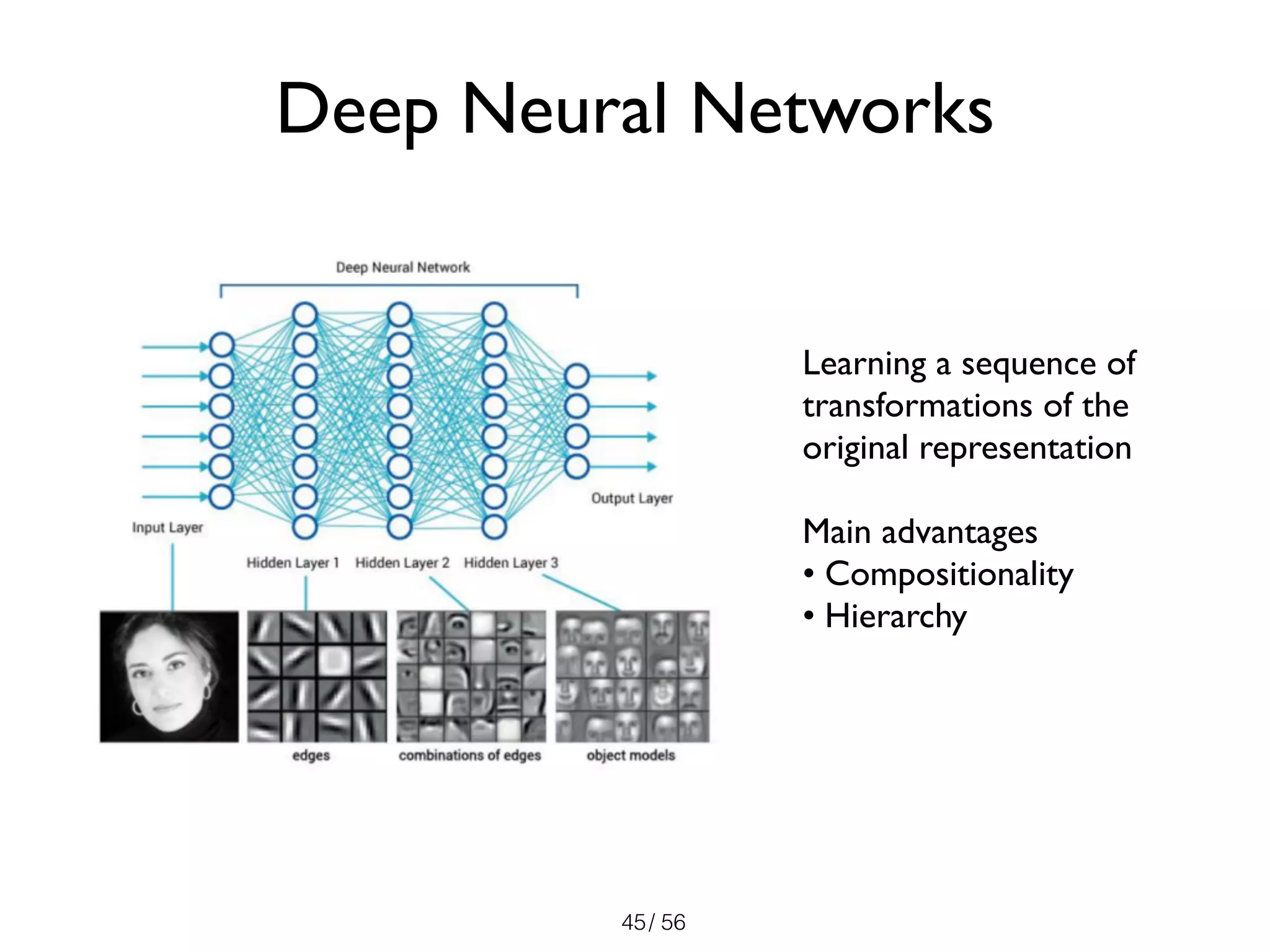
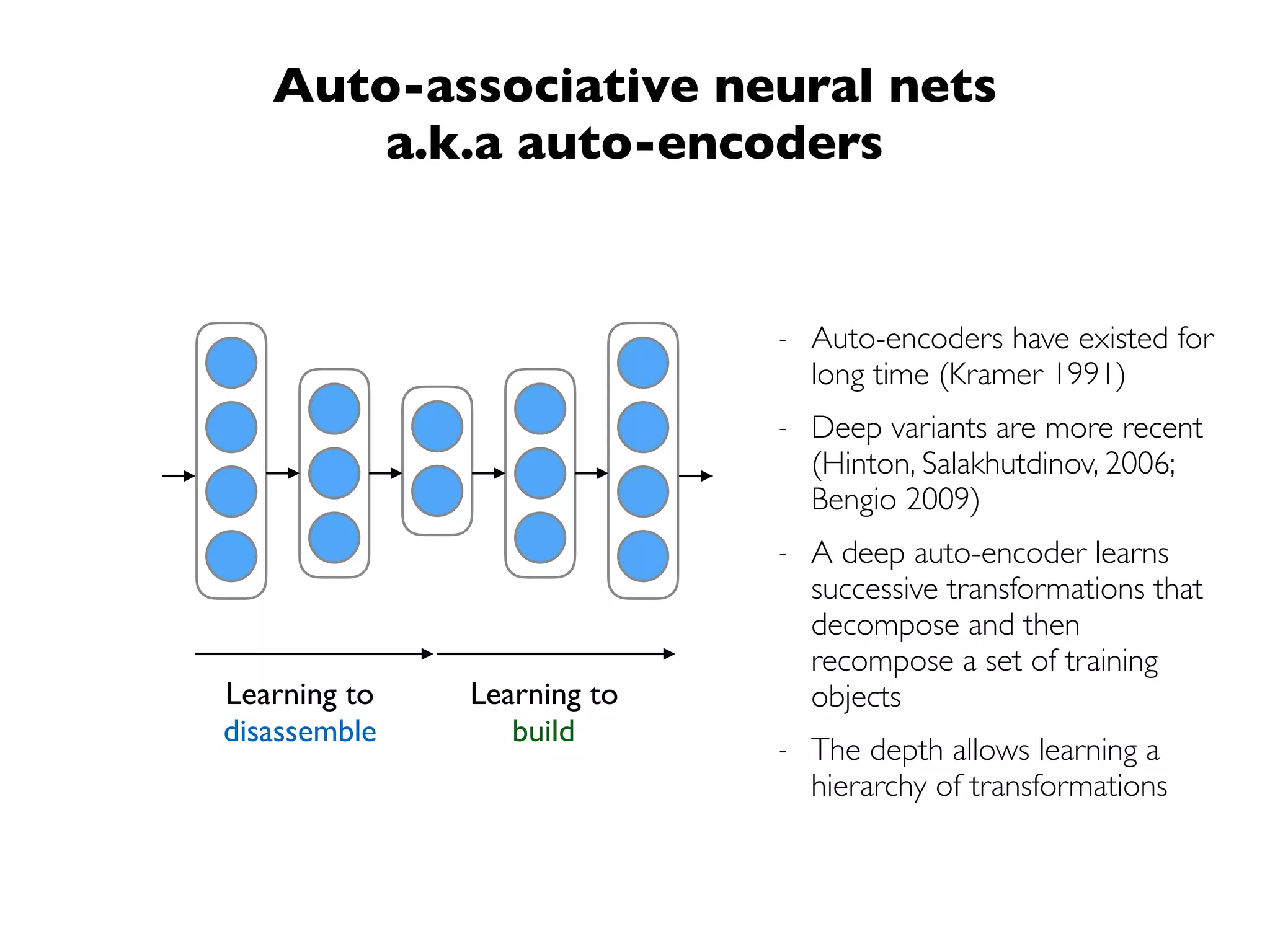
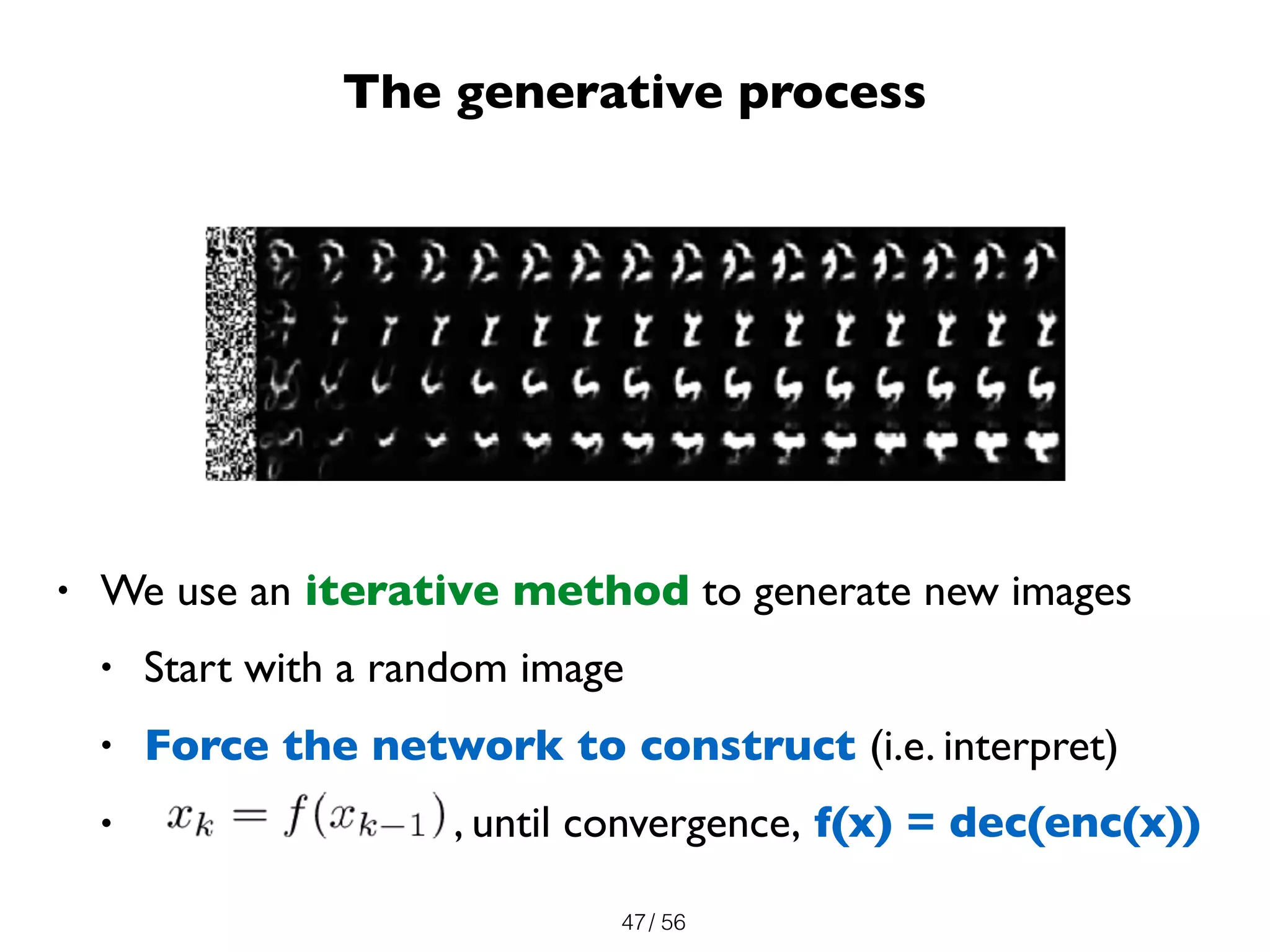

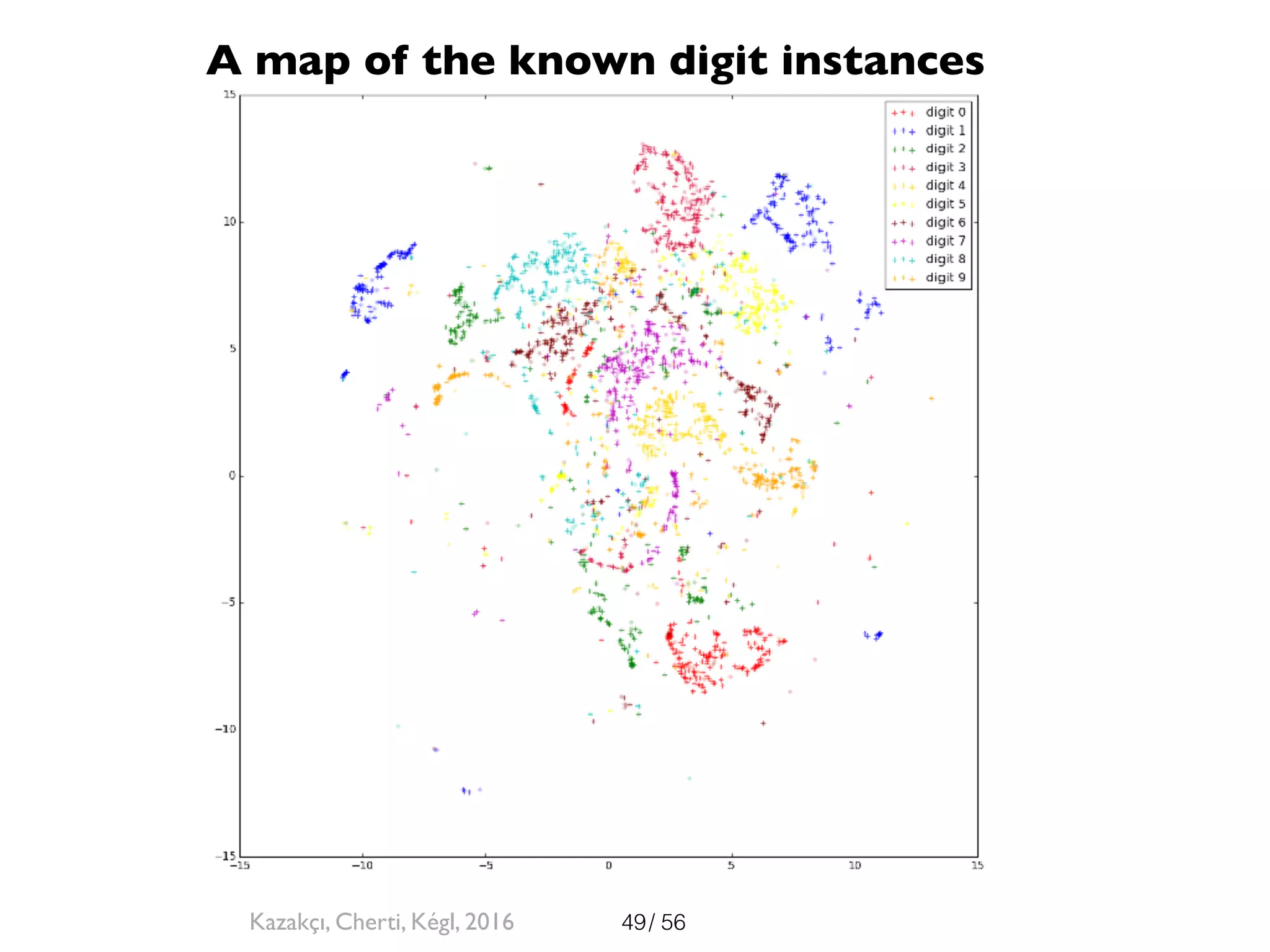
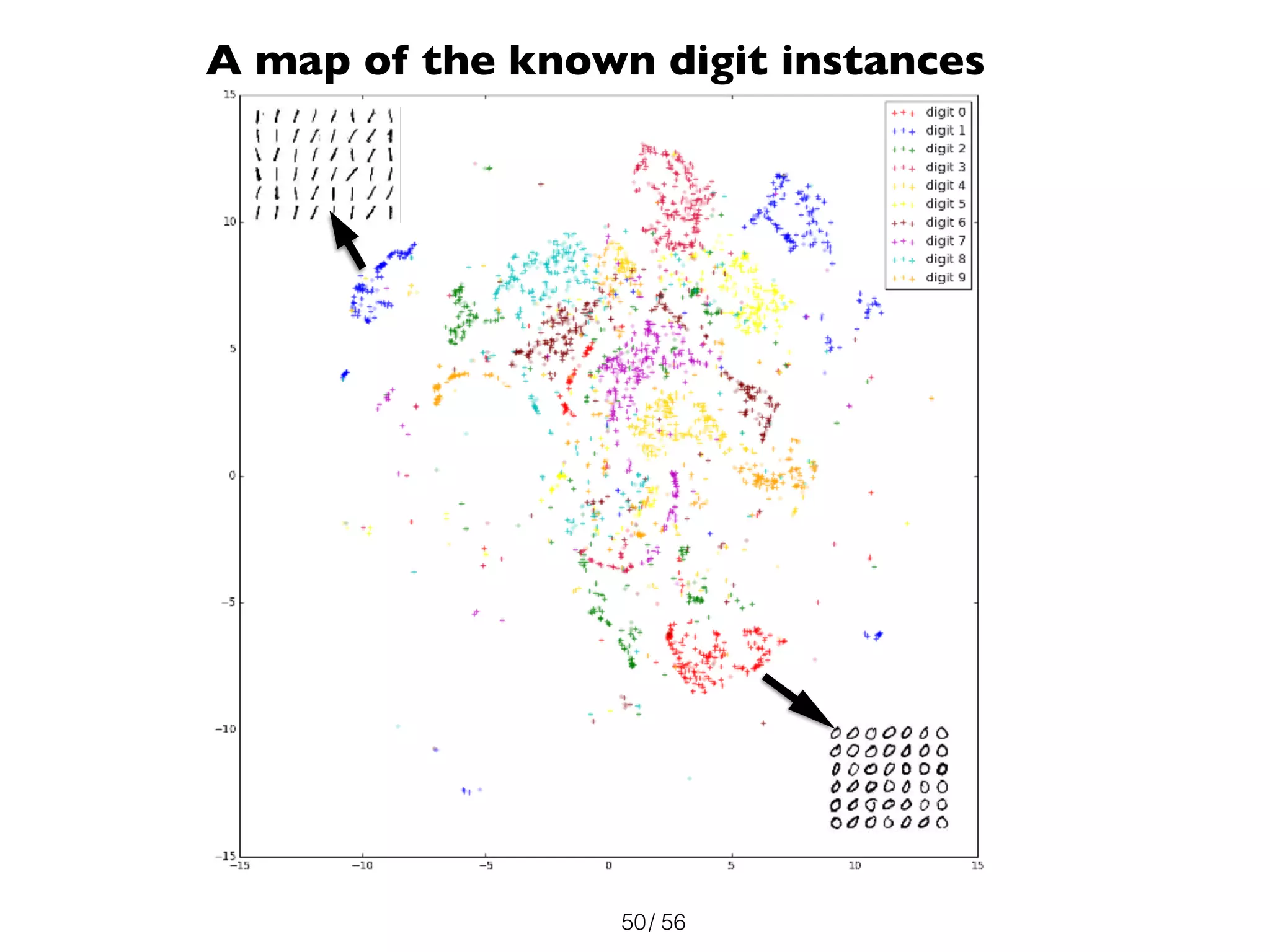

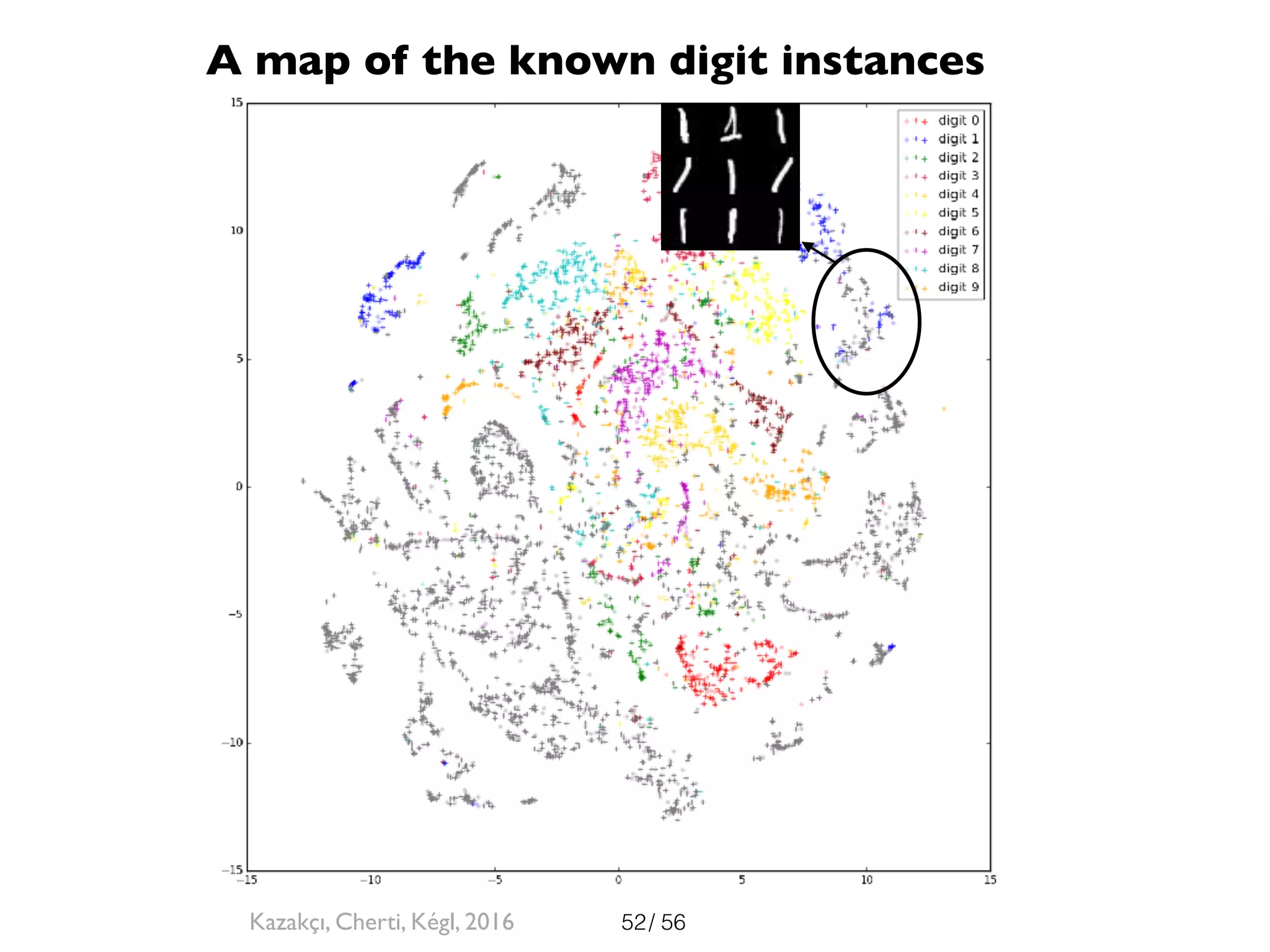
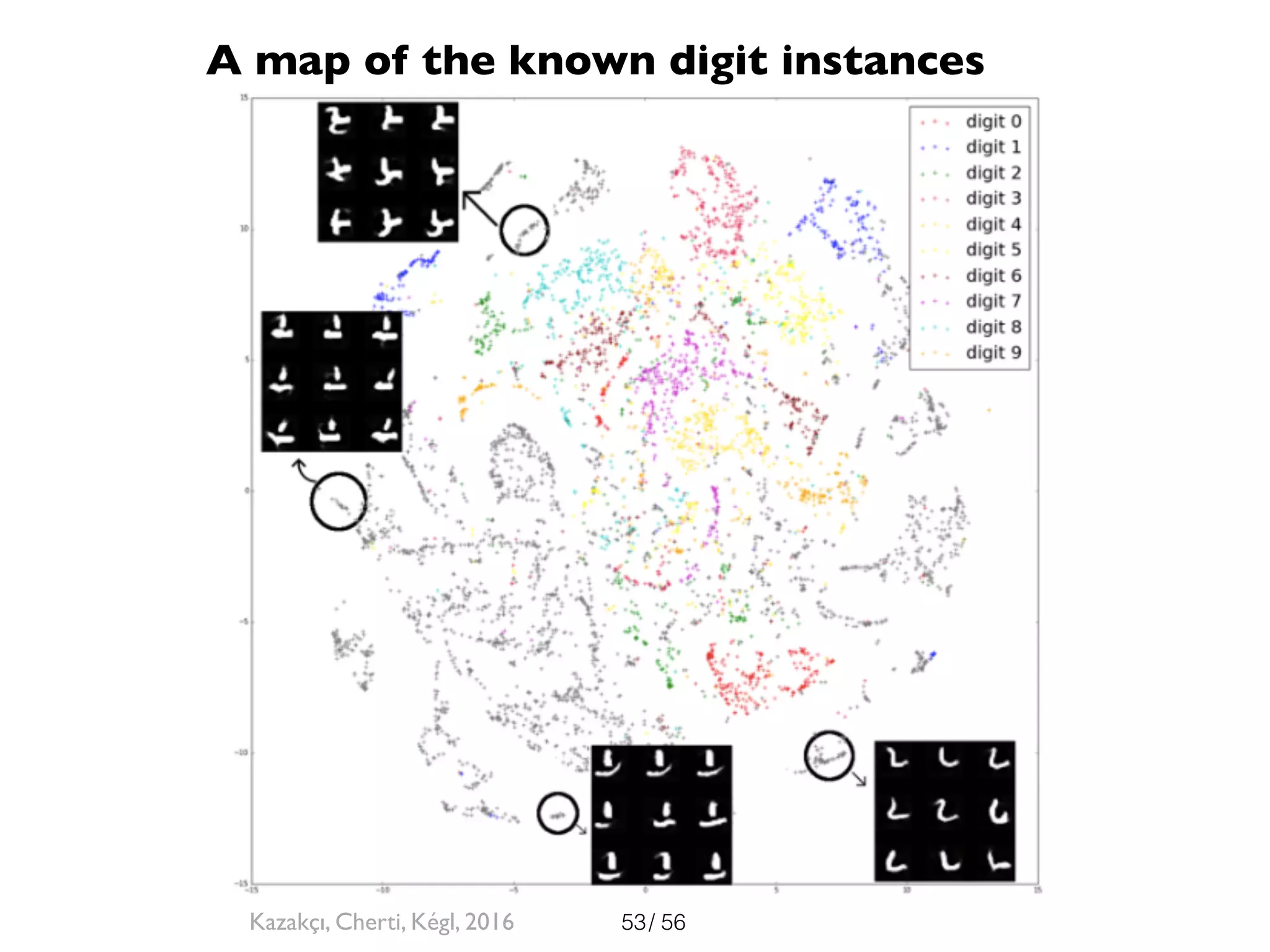
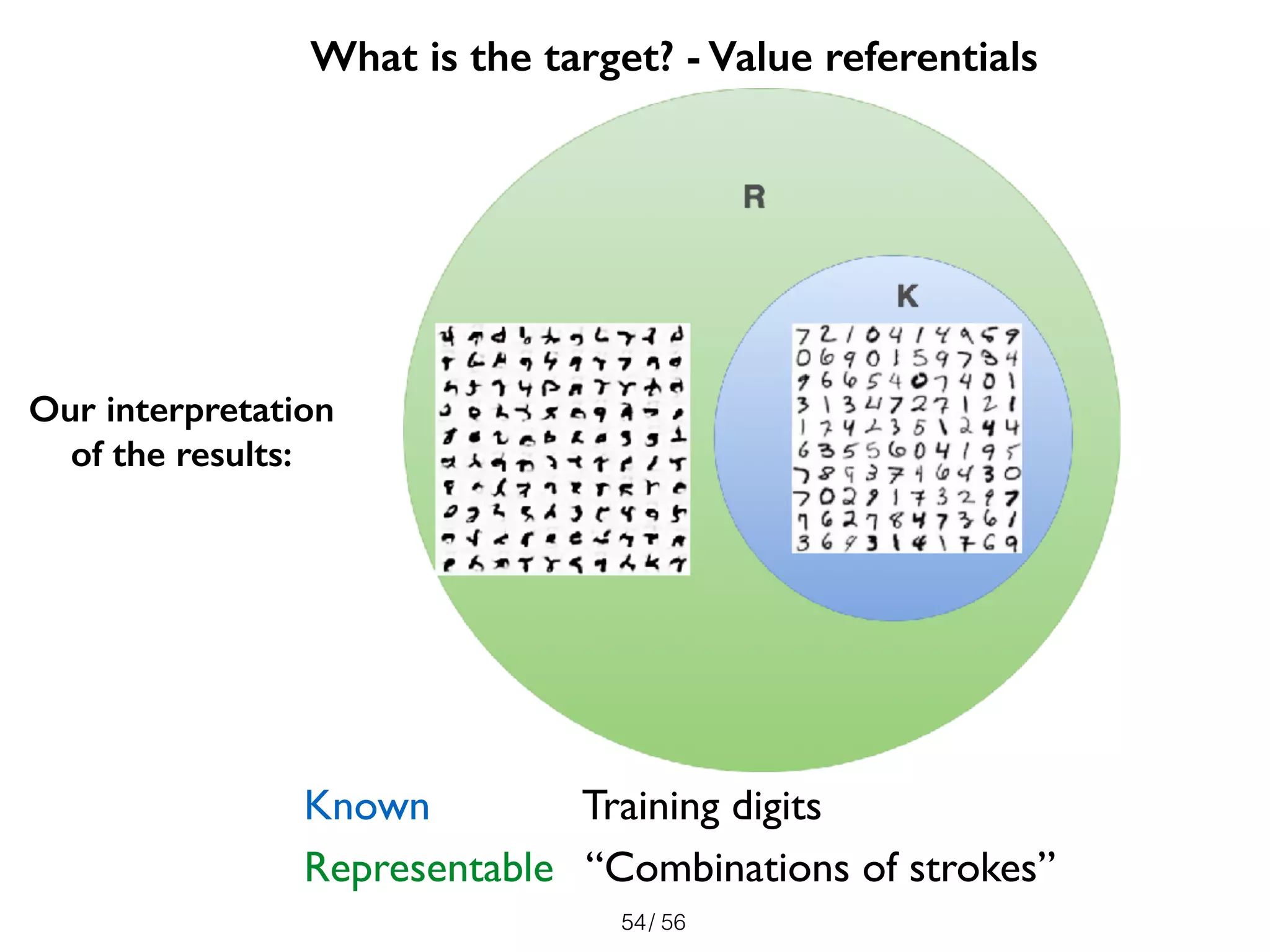
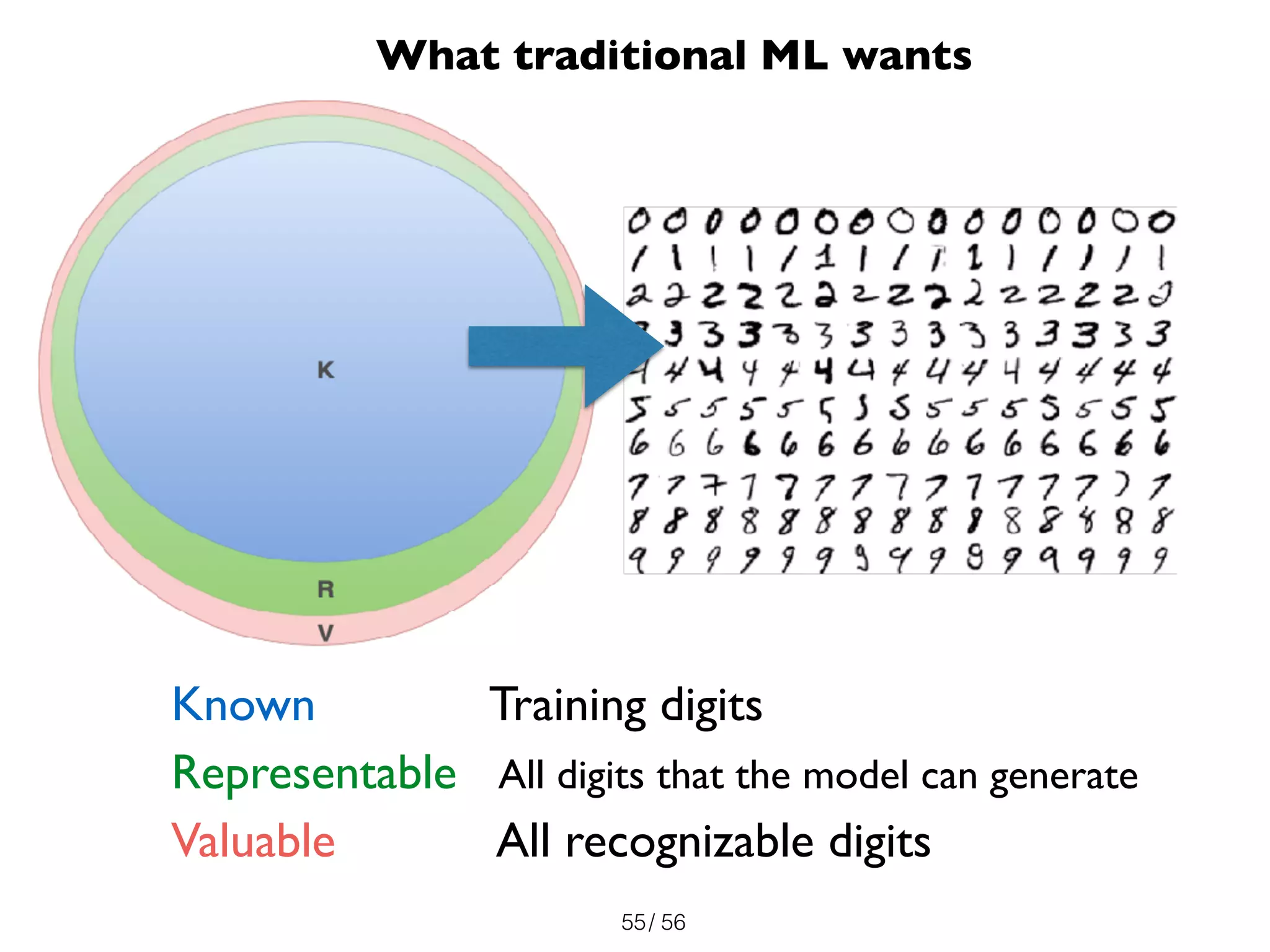
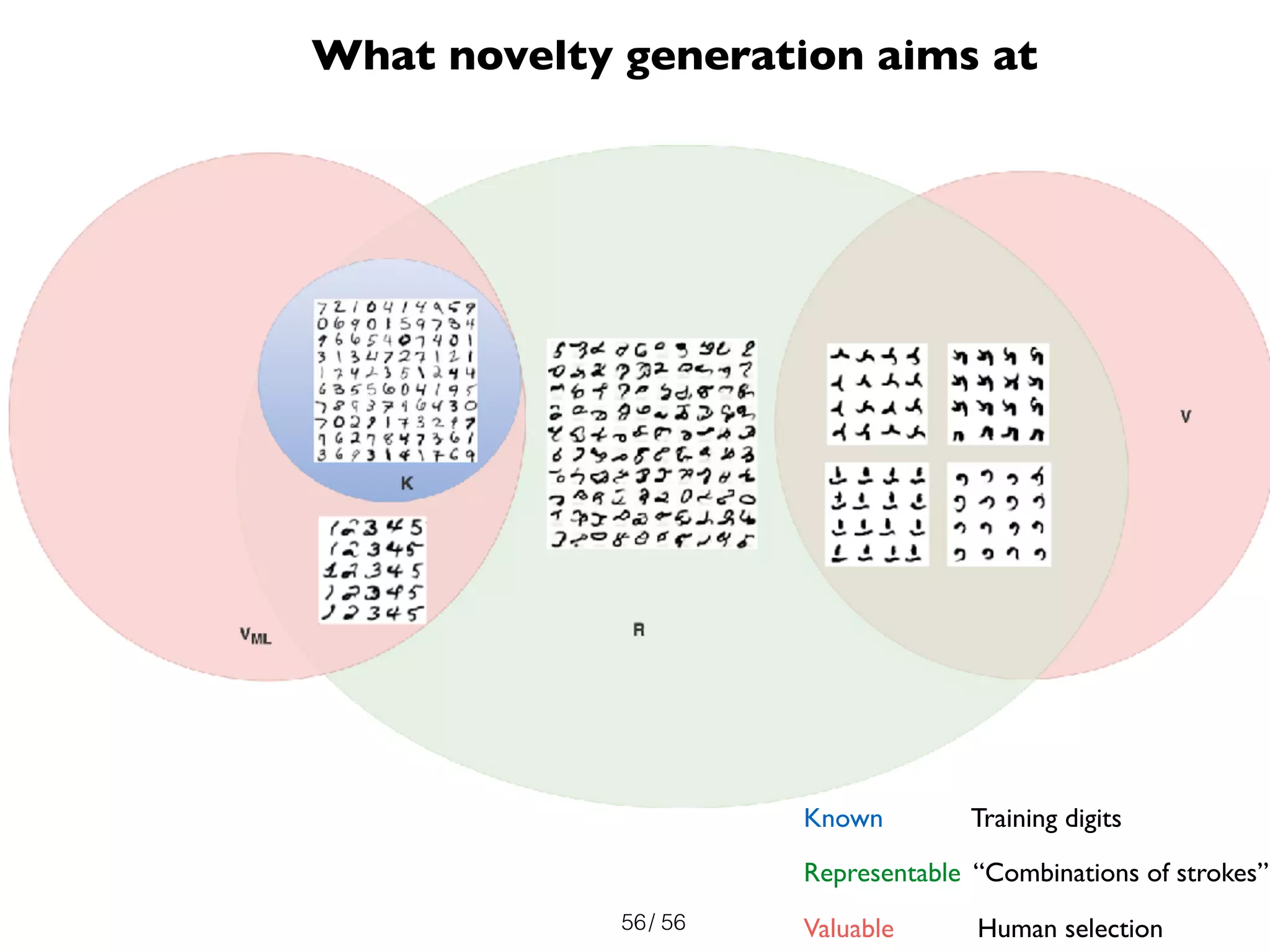


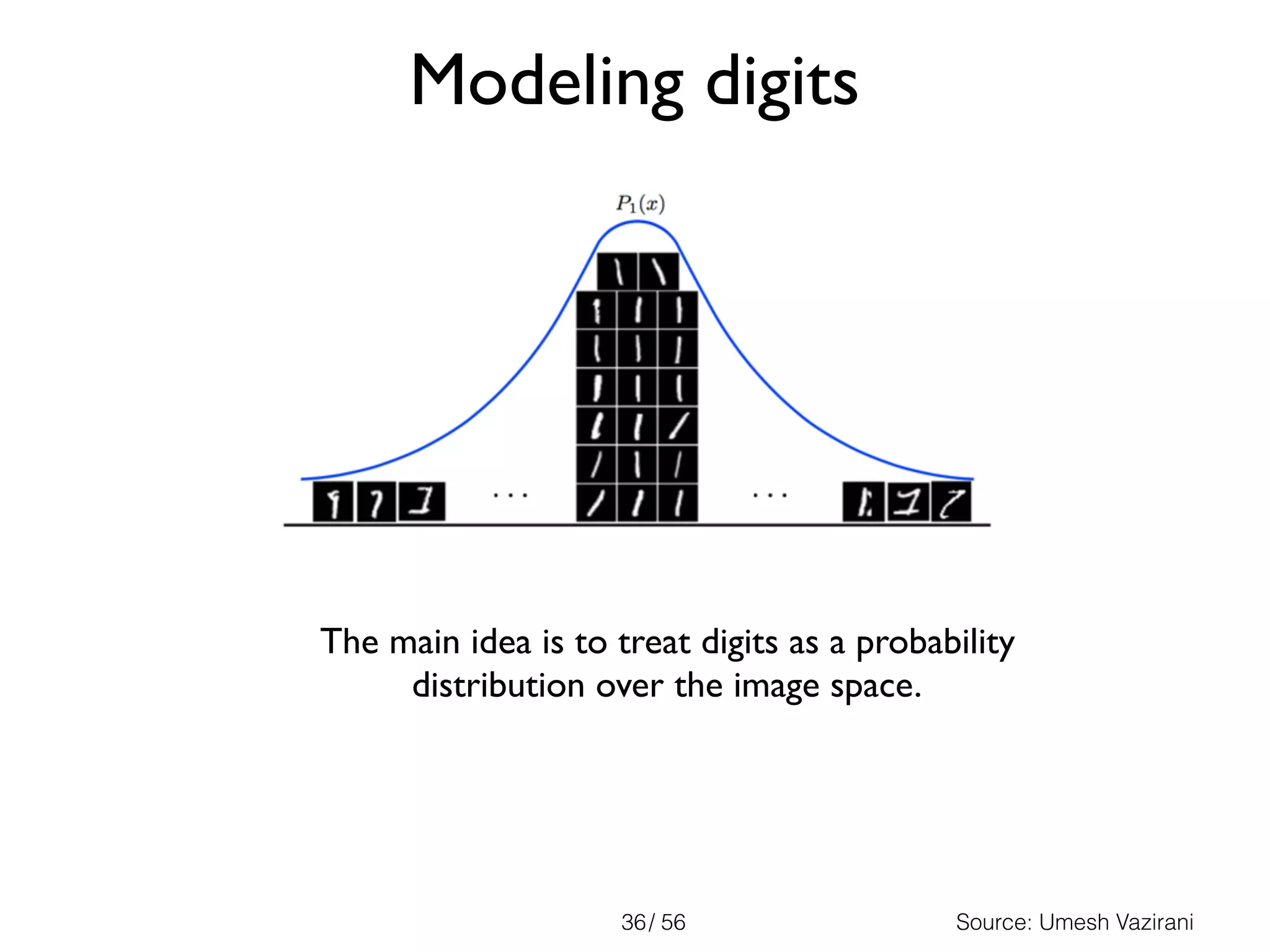
The document discusses the significance of representations in data science, specifically regarding learning and generating novelty through neural networks. It explores how various representations affect the modeling of objects, including handwritten digits, using techniques like Naive Bayes and deep neural networks. The emphasis is on understanding the generative potential of these models and the implications of representation on learning and novelty generation.






























































![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)