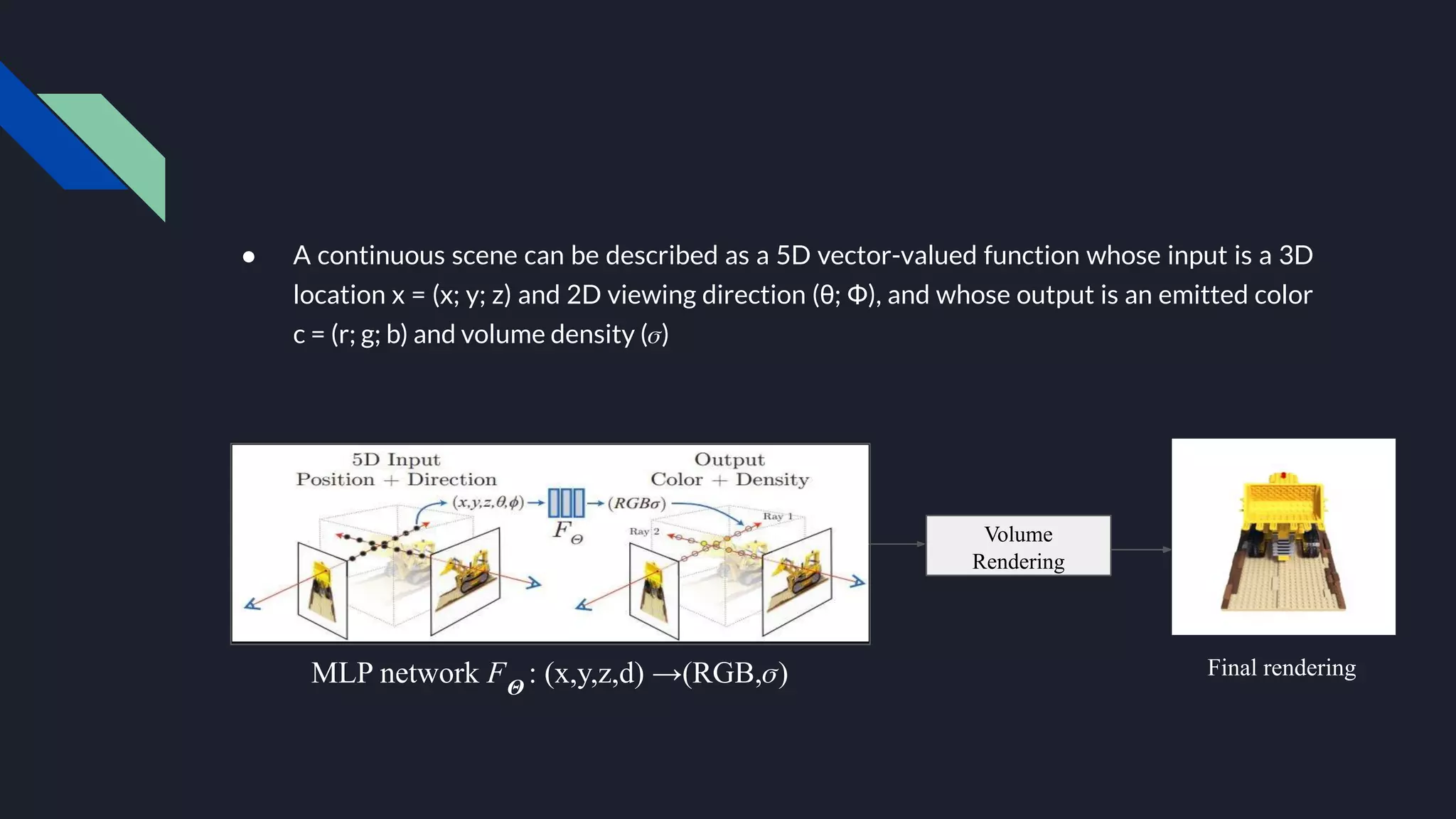
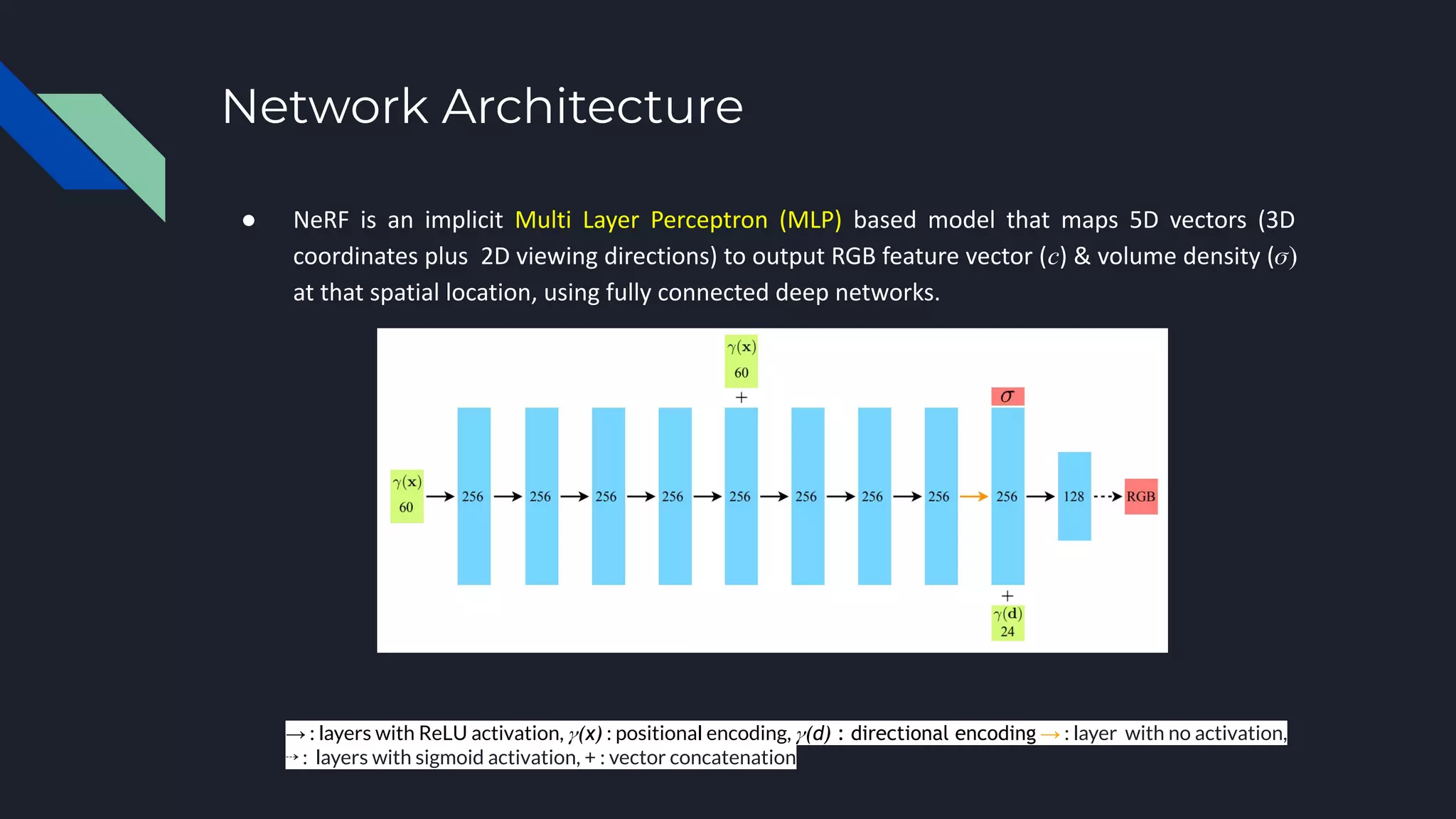
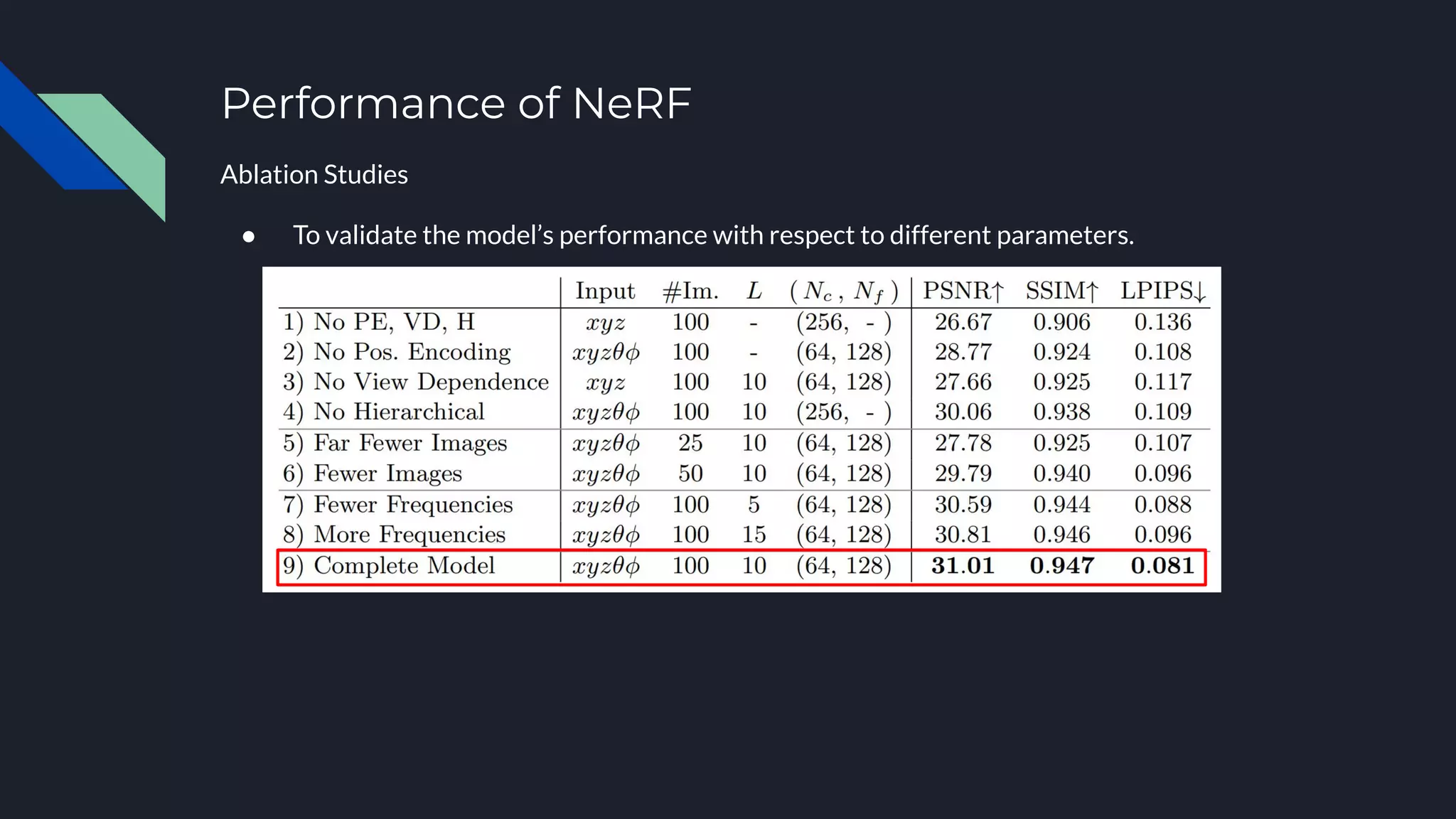
Neural Radiance Fields (NeRF) represents scenes as neural radiance fields that can be used for novel view synthesis. NeRF learns a continuous radiance field from a sparse set of input views using a multi-layer perceptron that maps 5D coordinates to RGB color and density values. It uses volumetric rendering to integrate these values along camera rays and optimizes the network via differentiable rendering and a reconstruction loss. NeRF produces high-fidelity novel views and has inspired extensions like handling dynamic scenes and reconstructing scenes from unstructured internet photos.









![NeRF Optimization - Hierarchical Sampling
● During the volume rendering phase, our model simultaneously optimizes two networks: coarse and fine
● We first sample a set of NC
locations with the RGB feature vector and density [σ (t)] outputs from the proposed
NeRF model, using stratified sampling, and evaluate the “coarse” network at these locations.
● The main function of coarse network is to compute the final rendered color of the ray for the coarse samples.
● a second set of Nf
locations are sampled from the [RGB + density] distribution using inverse transform sampling &
evaluate our “fine” network.
● All the samples are considered while computing the final rendered ray color, i.e, (NC
+ Nf
), at fine network stage.
This is done to ensure that more samples are allocated to regions we expect to contain visible content.](https://image.slidesharecdn.com/neuralradiancefieldsneuralrendering-230301200937-fa8ea534/75/Neural-Radiance-Fields-Neural-Rendering-pdf-12-2048.jpg)


















![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Paper] GIRAFFE: Representing Scenes as Compositional Generative Neural Featu...](https://cdn.slidesharecdn.com/ss_thumbnails/papergirafferepresentingscenesascompositionalgenerativeneuralfeaturefields-210823043723-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)























