


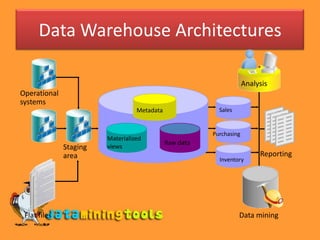
















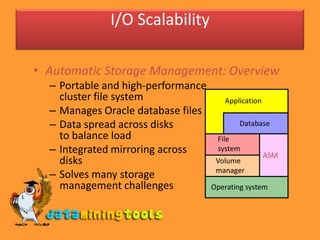


The document discusses key characteristics of data warehouses including that they contain historical data derived from transactions for querying, reporting, and analysis. It also compares online transaction processing (OLTP) systems to data warehouses. Additionally, it covers data warehouse architectures, design considerations, logical and physical design, and managing large volumes of data through techniques like partitioning and parallelism. Optimizing input/output performance is also highlighted as critical for data warehouses.











































































































