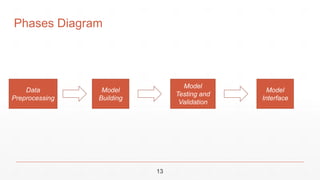
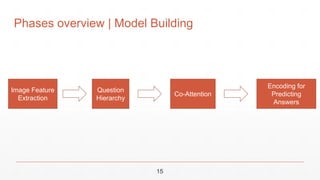
This document outlines a project to build a visual question answering system using hierarchical co-attention techniques. The system aims to take an image and question as input and output an answer by understanding how a region-based convolutional neural network comprehends the question. It describes the team members and supervisor overseeing the project. It also provides an outline of the introduction, motivation, problem definition, objectives, working phases, time plan, and tools to be used. The working phases include data preprocessing, model building using hierarchical co-attention, model testing and validation, and developing a user interface. The time plan and tools sections describe the timeline and programming languages, libraries, and frameworks that will be implemented.














































![Cells and Organs of immune system [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/cellsandorgansofimmunesystemautosaved-260123152717-ea0cb261-thumbnail.jpg?width=640&height=640&fit=bounds)


















