Downloaded 47 times











![Data sharing attribute clauses shared : visible and accessible by all threads simultaneously. Default (!i) . a[i]=a[i-1].. private : each thread will have a local copy, value is not maintained for use outside firstprivate : like private except initialized to original value. lastprivate : like private except original value is updated after construct. reduction (->reduction ops)](https://image.slidesharecdn.com/multicore-tumfug-110130102416-phpapp02/85/Multicore-20-320.jpg)














![This talk was given to the TumFUG Linux/Unix-User group at the TU München. Contact me via [email_address] You may use the pictures of the processors (not the screenshots, not the overview pic which I only adapted), but please do notify and credit me accordingly. Some of the code was copy-pasted from Wikipedia. I've removed copy-right problematic parts.](https://image.slidesharecdn.com/multicore-tumfug-110130102416-phpapp02/85/Multicore-39-320.jpg)

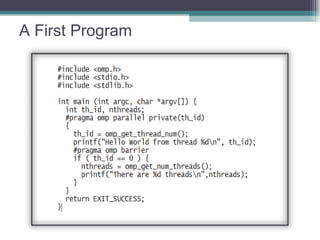
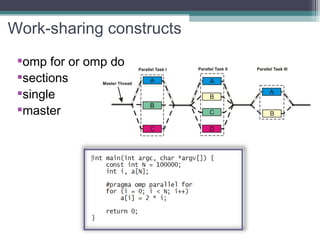
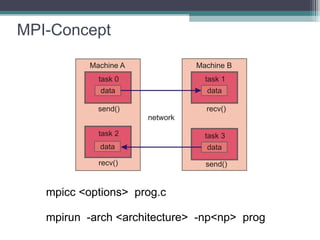
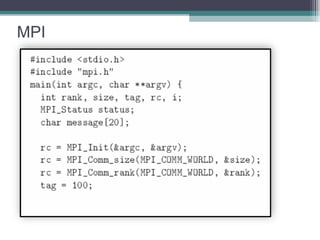
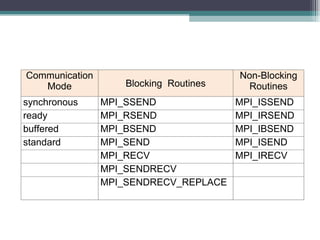
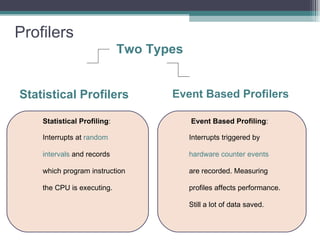
The document discusses parallel programming with an emphasis on multicore architectures using OpenMP and MPI. Key concepts include thread management, data sharing, communication modes, and profiling tools like PAPI. It is geared towards enhancing performance and understanding of multicore systems for both academic and practical applications.