Download to read offline




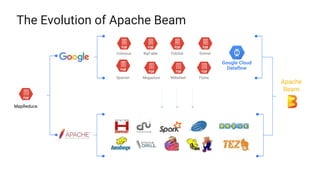
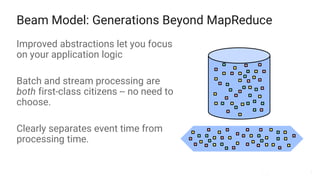
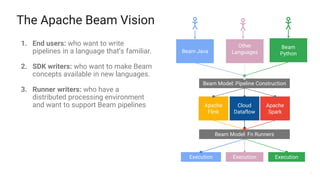
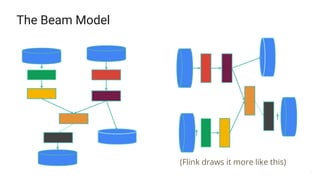
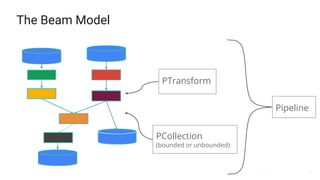


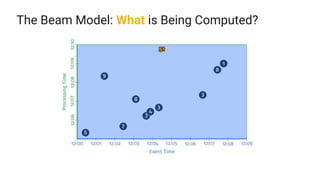

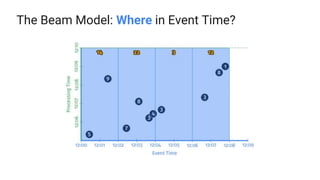

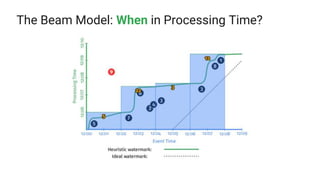

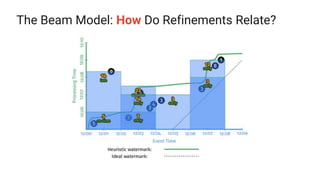
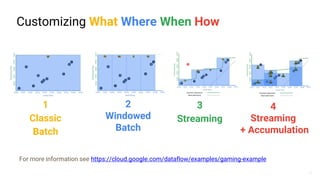




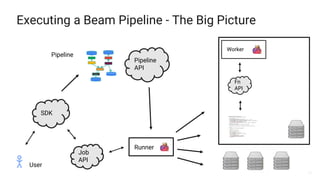




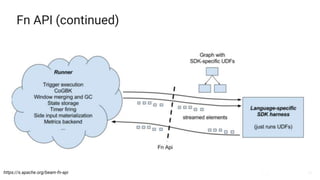
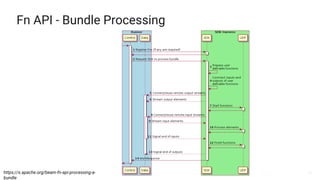
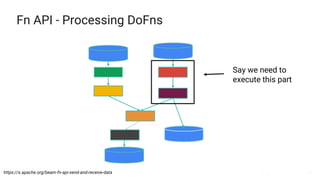
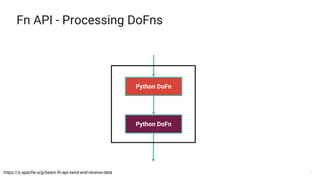
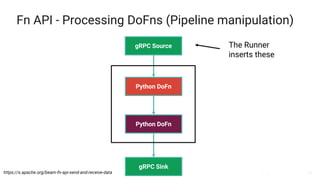
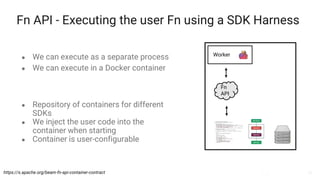







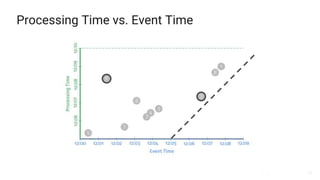

The document presents a detailed overview of Apache Beam, emphasizing its model for batch and stream processing, which integrates user-defined functions and allows execution across different programming languages. It discusses the architecture of Beam pipelines, the role of various APIs (pipeline, job, fn) in managing and executing data processing tasks, and highlights the interoperability between Apache Beam and Apache Flink. Future development directions and resources for further information on Beam and Flink are also provided.


















































































