Downloaded 50 times


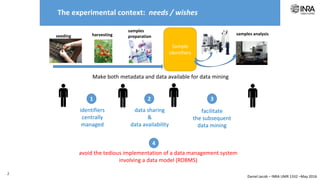
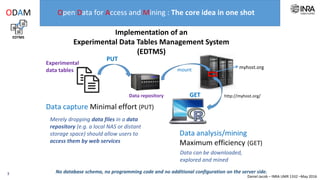


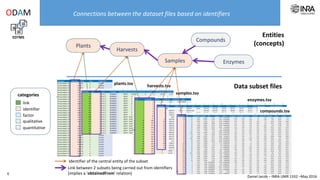

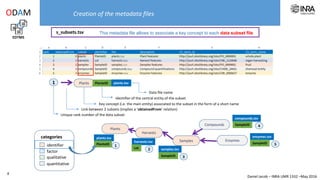



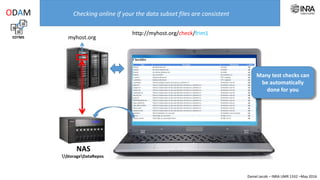

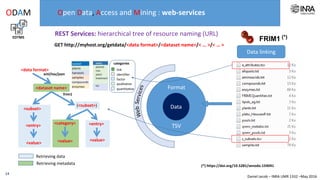


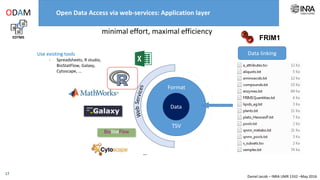
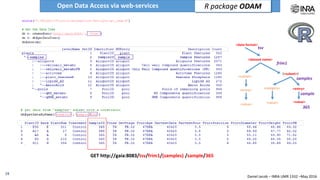



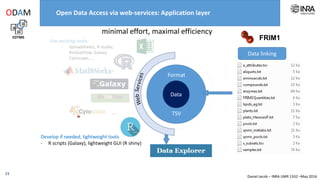
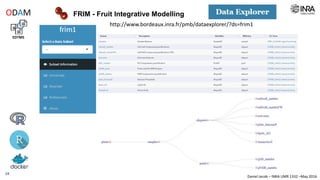

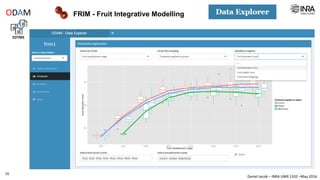

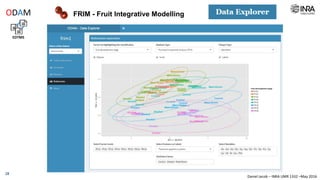
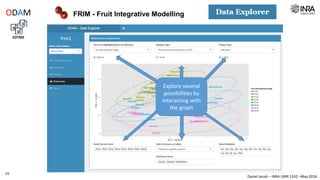




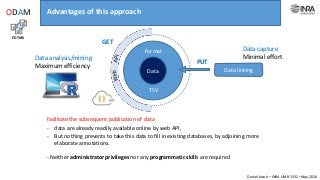



The document outlines a framework for making experimental data openly accessible and ready for mining using a centralized data repository, emphasizing the importance of compliant metadata files for effective data sharing. It details the procedures for data preparation, cleaning, and establishing connections between datasets through identifiers, along with the development of a web API for data retrieval. The approach aims to facilitate data analysis while minimizing effort and technical skills required for users.



















































































