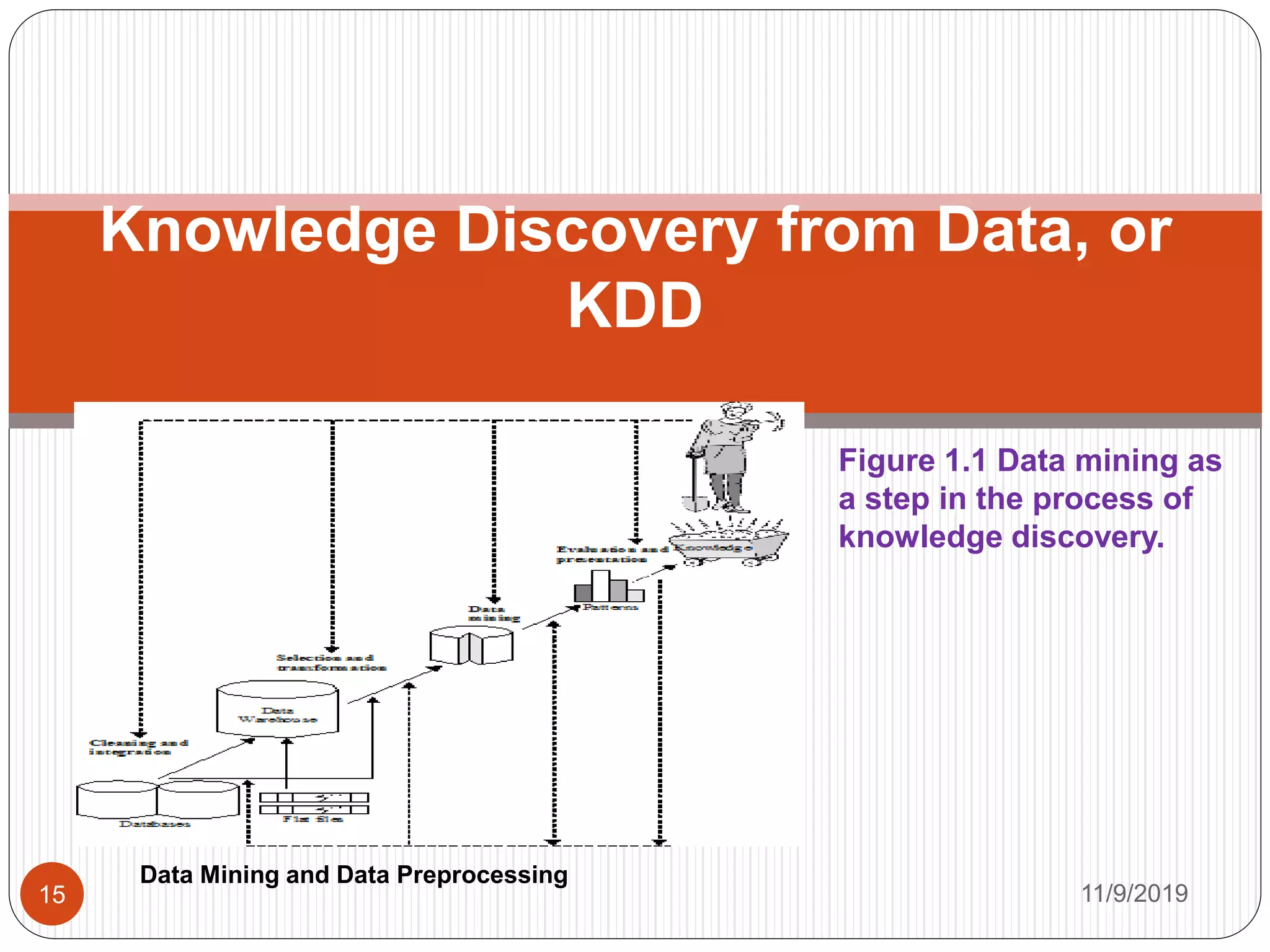
The document discusses data mining and data preprocessing. It notes that vast amounts of data are collected daily and analyzing this data is important. One emerging data repository is the data warehouse, which contains multiple heterogeneous data sources. Data mining transforms large collections of data into useful knowledge. Effective data preprocessing is important for improving data quality and mining accuracy. Techniques like data cleaning, integration, reduction, and transformation are used to handle issues like missing values, noise, inconsistencies and improve the overall quality of the data.