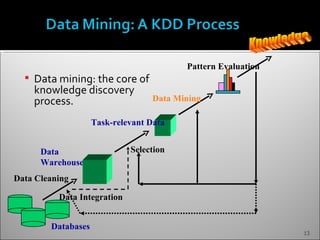
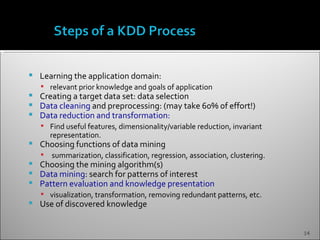
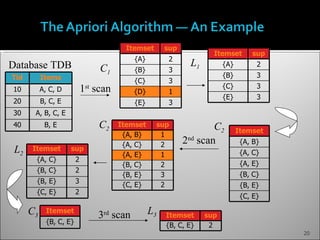
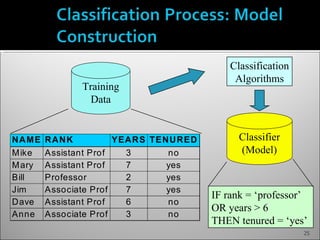
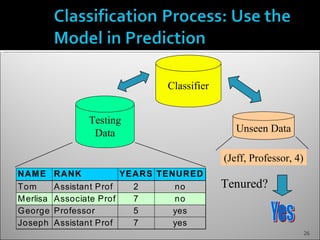
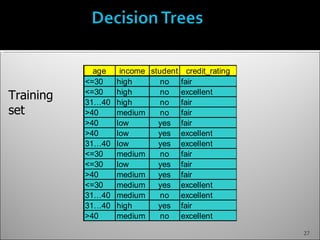
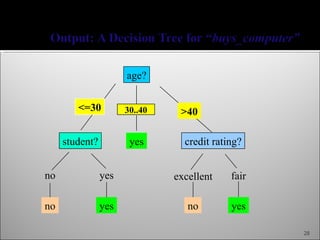
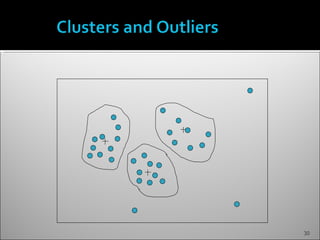
The document discusses data mining and its history and applications. It explains that data mining involves extracting useful patterns from large amounts of data, and has been used in applications like market analysis, fraud detection, and science. The document outlines the data mining process, including data selection, cleaning, transformation, algorithm selection, and pattern evaluation. It also discusses common data mining techniques like association rule mining to find frequent patterns in transactional data.