Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Nobuaki Oshiro
PPTX, PDF
8,520 views
20161127 doradora09 japanr2016_lt
https://japanr.connpass.com/event/43919/
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 10 times
1
/ 33
2
/ 33
3
/ 33
4
/ 33
5
/ 33
6
/ 33
7
/ 33
8
/ 33
9
/ 33
10
/ 33
11
/ 33
12
/ 33
13
/ 33
14
/ 33
15
/ 33
16
/ 33
17
/ 33
18
/ 33
19
/ 33
20
/ 33
21
/ 33
22
/ 33
23
/ 33
24
/ 33
25
/ 33
26
/ 33
27
/ 33
28
/ 33
29
/ 33
30
/ 33
31
/ 33
32
/ 33
33
/ 33
More Related Content
PDF
10分で分かるr言語入門ver2.15 15 1010
by
Nobuaki Oshiro
PDF
10分で分かるr言語入門ver2.14 15 0905
by
Nobuaki Oshiro
PDF
20170312 r言語環境構築&dplyr ハンズオン
by
Nobuaki Oshiro
PDF
TokyoR LT Rで連続データを離散化
by
tetsuro ito
PDF
10分で分かるr言語入門ver2 upload用
by
Nobuaki Oshiro
PPTX
Tokyo r50 beginner_2
by
Takashi Minoda
PDF
rstanで個人のパラメーターを推定した話
by
Yuya Matsumura
PDF
HiroshimaR4_LT_sakaue
by
SAKAUE, Tatsuya
10分で分かるr言語入門ver2.15 15 1010
by
Nobuaki Oshiro
10分で分かるr言語入門ver2.14 15 0905
by
Nobuaki Oshiro
20170312 r言語環境構築&dplyr ハンズオン
by
Nobuaki Oshiro
TokyoR LT Rで連続データを離散化
by
tetsuro ito
10分で分かるr言語入門ver2 upload用
by
Nobuaki Oshiro
Tokyo r50 beginner_2
by
Takashi Minoda
rstanで個人のパラメーターを推定した話
by
Yuya Matsumura
HiroshimaR4_LT_sakaue
by
SAKAUE, Tatsuya
What's hot
PDF
10分で分かるr言語入門ver2 6
by
Nobuaki Oshiro
PDF
Hiroshimar4_Rintro
by
SAKAUE, Tatsuya
PDF
10分で分かるr言語入門ver2.5
by
Nobuaki Oshiro
PPTX
Tokyo r30 beginner
by
Takashi Minoda
PDF
2016年6月版データマエショリスト入門
by
Yuya Matsumura
PDF
10分で分かるr言語入門ver2.8 14 0712
by
Nobuaki Oshiro
PDF
Gensim
by
saireya _
PDF
初心者のためのRとRStudio入門 vol.2
by
OWL.learn
PDF
LDA入門
by
正志 坪坂
PDF
AutoEncoderで特徴抽出
by
Kai Sasaki
PDF
HiRoshimaR3_IntroR
by
SAKAUE, Tatsuya
PDF
HiroshimaR5_Intro
by
SAKAUE, Tatsuya
PDF
Rstudio事始め
by
Takashi Yamane
PDF
トピックモデルの話
by
kogecoo
PDF
2017年3月版データマエショリスト入門
by
Yuya Matsumura
PDF
2017年3月版データマエショリスト入門(誤植修正版)
by
Yuya Matsumura
PDF
HiroshimaR6_Introduction
by
SAKAUE, Tatsuya
PDF
Sendai r01 beginnerssession1
by
kotora_0507
PDF
10分で分かるr言語入門ver2.7
by
Nobuaki Oshiro
PDF
知って得するWebで便利なpostgre sqlの3つの機能
by
Soudai Sone
10分で分かるr言語入門ver2 6
by
Nobuaki Oshiro
Hiroshimar4_Rintro
by
SAKAUE, Tatsuya
10分で分かるr言語入門ver2.5
by
Nobuaki Oshiro
Tokyo r30 beginner
by
Takashi Minoda
2016年6月版データマエショリスト入門
by
Yuya Matsumura
10分で分かるr言語入門ver2.8 14 0712
by
Nobuaki Oshiro
Gensim
by
saireya _
初心者のためのRとRStudio入門 vol.2
by
OWL.learn
LDA入門
by
正志 坪坂
AutoEncoderで特徴抽出
by
Kai Sasaki
HiRoshimaR3_IntroR
by
SAKAUE, Tatsuya
HiroshimaR5_Intro
by
SAKAUE, Tatsuya
Rstudio事始め
by
Takashi Yamane
トピックモデルの話
by
kogecoo
2017年3月版データマエショリスト入門
by
Yuya Matsumura
2017年3月版データマエショリスト入門(誤植修正版)
by
Yuya Matsumura
HiroshimaR6_Introduction
by
SAKAUE, Tatsuya
Sendai r01 beginnerssession1
by
kotora_0507
10分で分かるr言語入門ver2.7
by
Nobuaki Oshiro
知って得するWebで便利なpostgre sqlの3つの機能
by
Soudai Sone
Viewers also liked
PPTX
Tidyverseとは
by
yutannihilation
PDF
高速・省メモリにlibsvm形式で ダンプする方法を研究してみた
by
Keisuke Hosaka
PDF
統計的因果推論勉強会 第1回
by
Hikaru GOTO
PDF
木と電話と選挙(causalTree)
by
Shota Yasui
PDF
Randomforestで高次元の変数重要度を見る #japanr LT
by
Akifumi Eguchi
PPTX
てかLINEやってる? (Japan.R 2016 LT) #JapanR
by
cancolle
PDF
傾向スコア:その概念とRによる実装
by
takehikoihayashi
PDF
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
PDF
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
PDF
Rで学ぶ 傾向スコア解析入門 - 無作為割り当てが出来ない時の因果効果推定 -
by
Yohei Sato
Tidyverseとは
by
yutannihilation
高速・省メモリにlibsvm形式で ダンプする方法を研究してみた
by
Keisuke Hosaka
統計的因果推論勉強会 第1回
by
Hikaru GOTO
木と電話と選挙(causalTree)
by
Shota Yasui
Randomforestで高次元の変数重要度を見る #japanr LT
by
Akifumi Eguchi
てかLINEやってる? (Japan.R 2016 LT) #JapanR
by
cancolle
傾向スコア:その概念とRによる実装
by
takehikoihayashi
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
Rで学ぶ 傾向スコア解析入門 - 無作為割り当てが出来ない時の因果効果推定 -
by
Yohei Sato
Similar to 20161127 doradora09 japanr2016_lt
PDF
PyDataTokyo201-05-22
by
Yuta Kashino
PPTX
トピックモデルの基礎と応用
by
Tomonari Masada
PPTX
20151221 public
by
Katsuhiko Ishiguro
PDF
第47回TokyoWebMining, トピックモデリングによる評判分析
by
I_eric_Y
PDF
20140614 tokyo r lt
by
tetsuro ito
PDF
データに隠れた構造を推定して予測に活かす 〜行列分解とそのテストスコアデータへの応用〜
by
Atsunori Kanemura
PDF
クラスタリングとレコメンデーション資料
by
洋資 堅田
PPTX
トピックモデル勉強会: 第2章 Latent Dirichlet Allocation
by
Haruka Ozaki
PDF
第二回機械学習アルゴリズム実装会 - LDA
by
Masayuki Isobe
PDF
潜在ディリクレ配分法
by
y-uti
PDF
Sakuteki02 yokkuns
by
Yohei Sato
PyDataTokyo201-05-22
by
Yuta Kashino
トピックモデルの基礎と応用
by
Tomonari Masada
20151221 public
by
Katsuhiko Ishiguro
第47回TokyoWebMining, トピックモデリングによる評判分析
by
I_eric_Y
20140614 tokyo r lt
by
tetsuro ito
データに隠れた構造を推定して予測に活かす 〜行列分解とそのテストスコアデータへの応用〜
by
Atsunori Kanemura
クラスタリングとレコメンデーション資料
by
洋資 堅田
トピックモデル勉強会: 第2章 Latent Dirichlet Allocation
by
Haruka Ozaki
第二回機械学習アルゴリズム実装会 - LDA
by
Masayuki Isobe
潜在ディリクレ配分法
by
y-uti
Sakuteki02 yokkuns
by
Yohei Sato
More from Nobuaki Oshiro
PDF
20181117_データ分析プロジェクトの流れを理解する_PDCAとKPIツリー
by
Nobuaki Oshiro
PDF
20170909 reafletでお手軽可視化 on_r_20分ver_up用
by
Nobuaki Oshiro
PPTX
20170826 fukuoka.r告知_reafletでお手軽可視化_on_r
by
Nobuaki Oshiro
PPTX
20170707 rでkaggle入門
by
Nobuaki Oshiro
PDF
15 0117 kh-coderご紹介 for R users
by
Nobuaki Oshiro
PDF
15 0117 kh-coderご紹介
by
Nobuaki Oshiro
PDF
15 0117 r言語活用事例-外部公開用
by
Nobuaki Oshiro
PDF
10分で分かるr言語入門 短縮バージョン 15-0117_upload用
by
Nobuaki Oshiro
PDF
10分で分かるr言語入門ver2.10 14 1101
by
Nobuaki Oshiro
PDF
10分で分かるr言語入門ver2.9 14 0920
by
Nobuaki Oshiro
PDF
10分で分かるr言語入門ver2.4
by
Nobuaki Oshiro
PDF
Doradora09 lt tokyo_r33
by
Nobuaki Oshiro
PDF
10分で分かるr言語入門ver2.3
by
Nobuaki Oshiro
PDF
10分で分かるr言語入門ver2.2 13 0223
by
Nobuaki Oshiro
PPT
Code iq×japanr 公開用
by
Nobuaki Oshiro
PDF
10分で分かるR言語入門ver2.1
by
Nobuaki Oshiro
PDF
10分で分かるR言語入門ver2_0906
by
Nobuaki Oshiro
PDF
10min r study_tokyor25
by
Nobuaki Oshiro
PDF
10min r study_tokyor25
by
Nobuaki Oshiro
PDF
Tokyor24 doradora09
by
Nobuaki Oshiro
20181117_データ分析プロジェクトの流れを理解する_PDCAとKPIツリー
by
Nobuaki Oshiro
20170909 reafletでお手軽可視化 on_r_20分ver_up用
by
Nobuaki Oshiro
20170826 fukuoka.r告知_reafletでお手軽可視化_on_r
by
Nobuaki Oshiro
20170707 rでkaggle入門
by
Nobuaki Oshiro
15 0117 kh-coderご紹介 for R users
by
Nobuaki Oshiro
15 0117 kh-coderご紹介
by
Nobuaki Oshiro
15 0117 r言語活用事例-外部公開用
by
Nobuaki Oshiro
10分で分かるr言語入門 短縮バージョン 15-0117_upload用
by
Nobuaki Oshiro
10分で分かるr言語入門ver2.10 14 1101
by
Nobuaki Oshiro
10分で分かるr言語入門ver2.9 14 0920
by
Nobuaki Oshiro
10分で分かるr言語入門ver2.4
by
Nobuaki Oshiro
Doradora09 lt tokyo_r33
by
Nobuaki Oshiro
10分で分かるr言語入門ver2.3
by
Nobuaki Oshiro
10分で分かるr言語入門ver2.2 13 0223
by
Nobuaki Oshiro
Code iq×japanr 公開用
by
Nobuaki Oshiro
10分で分かるR言語入門ver2.1
by
Nobuaki Oshiro
10分で分かるR言語入門ver2_0906
by
Nobuaki Oshiro
10min r study_tokyor25
by
Nobuaki Oshiro
10min r study_tokyor25
by
Nobuaki Oshiro
Tokyor24 doradora09
by
Nobuaki Oshiro
20161127 doradora09 japanr2016_lt
1.
Japan.R 2016 LT doradora09
2.
本日のお話 1. LDA-Visパッケージのご紹介 2. doradora09からお知らせ
3.
自己紹介 • 大城信晃 • @doradora09 •
データ分析屋 • ヤフー -> DATUM STUDIO • Tokyo.Rのスタッフ(2010年〜) • 主に初心者セッションと懇親会 (BAR doradora)
4.
自己紹介 • 大城信晃 • @doradora09 •
データ分析屋 • ヤフー -> DATUM STUDIO • Tokyo.Rのスタッフ(2010年〜) • 主に初心者セッションと懇親会 (BAR doradora)
5.
1.LDA-Visパッケージのご紹介
6.
LDAとは • “Latent Dirichlet
Allocation”の略 • 文書中の単語の「トピック」を確率的に求める言語モデル • 各単語が「隠れトピック」(話題、カテゴリー)から生成されて いる、と想定して、そのトピックを文書集合から教師無しで推 定することが目的
7.
トピック分類できると何が嬉しいか • (大量の)文章の要約や分類ができる • 文章の概要把握、効率的な情報収集 •
論点を見つける • 商品のユーザーレビューの解析 • 背景のトピックの発見 • りんごの「apple」と企業の「apple」の区別
8.
例:以下の3つのニュース記事をLDA 1. 博多駅前 再び道路7センチほど沈み込む
通行止めに • 26日未明、福岡市のJR博多駅前の大規模に道路が陥没した現場付近で、再び道路が 最大で深さ7センチほど沈んでいるのが見つかり、警察は周辺の交通を規制して、詳し い状態などを調べています。・・・ 2. 陥没めど立たぬ休業補償 飲食店など博多駅前事業者 福岡市に 問い合わせ50件 • 福岡市のJR博多駅前の道路陥没事故で休業を余儀なくされた飲食店などの事業者から 損失補償に関する問い合わせが市に相次ぎ、11日までに50件を超えた。・・・ 3. 陥没周辺の建物は? 福岡市「倒壊の恐れなし」 専門家「地震 の揺れに注意を」 • 陥没事故の周辺では、建物の倒壊など二次被害も懸念された。福岡市は8日、陥没箇所を中心 に東西約400メートル、南北約150メートルにある42棟で応急危険度判定を実 施。・・・
9.
例:以下の3つのニュース記事をLDA 1. 博多駅前 再び道路7センチほど沈み込む
通行止めに • 26日未明、福岡市のJR博多駅前の大規模に道路が陥没した現場付近で、再び道路が 最大で深さ7センチほど沈んでいるのが見つかり、警察は周辺の交通を規制して、詳し い状態などを調べています。・・・ 2. 陥没めど立たぬ休業補償 飲食店など博多駅前事業者 福岡市に 問い合わせ50件 • 福岡市のJR博多駅前の道路陥没事故で休業を余儀なくされた飲食店などの事業者から 損失補償に関する問い合わせが市に相次ぎ、11日までに50件を超えた。・・・ 3. 陥没周辺の建物は? 福岡市「倒壊の恐れなし」 専門家「地震 の揺れに注意を」 • 陥没事故の周辺では、建物の倒壊など二次被害も懸念された。福岡市は8日、陥没箇所を中心 に東西約400メートル、南北約150メートルにある42棟で応急危険度判定を実 施。・・・
10.
今回用いるパッケージ • RMeCab :
日本語の形態素解析 • lda : LDAの実行 • LDAvis : LDAをいい感じに可視化
11.
RMeCab • RMeCabを使って名詞、形容詞のみに限定 setwd('/Users/apple/Desktop/ldavis_lt') library(RMeCab) tmp_doc.1 <-
NULL tmp_doc.1 <- RMeCabText("text_1.txt") doc.1 <- NULL for (i in 1:length(tmp_doc.1)) { if (tmp_doc.1[[i]][2] %in% c("名詞", "形容詞")) { doc.1 <- c(doc.1, paste(tmp_doc.1[[i]][1], sep = "", collapse = " ")) } } > head(doc.1) [1] "博多" "駅" "前" "道路" "7" "センチ"
12.
LDA準備 • 単語をカウント # 他の2記事もdoc.2,
doc.2として同様に読み込む(省略) #複数文章をリスト化 doc.list <- NULLdoc.list <- list(doc.1, doc.2, doc.3) names(doc.list) <- c("doc1", "doc2", "doc3") library(lda) # ターム行列作成(単語ごとにカウント) term.table <- table(unlist(doc.list)) term.table <- sort(term.table, decreasing = TRUE) # 単語一覧 vocab <- NULL vocab <- names(term.table) > head(term.table) > 市 陥没 補償 1 道路 福岡 > 22 14 13 11 11 11
13.
LDA準備 • 文章がどの単語に一致するかでindex化 get.terms <-
function(x) { index <- match(x, vocab) index <- index[!is.na(index)] rbind(as.integer(index - 1), as.integer(rep(1, length(index)))) } documents <- NULL documents <- lapply(doc.list, get.terms) > head(documents) >$doc1 > [,1] [,2] [,3] [,4] [,5] >[1,] 17 46 231 4 42 >[2,] 1 1 1 1 1
14.
LDA準備 • LDA用の各種パラメータの準備 D <-
length(documents) # 記事の数 W <- length(vocab) # 単語の数 doc.length <- sapply(documents, function(x) sum(x[2, ])) #記事ごとの単語数 N <- sum(doc.length) # トータルの単語数 term.frequency <- as.integer(term.table) K <- 10 ## トピック数 G <- 200 ## 反復回数 alpha <- 0.02 #αパラメータ eta <- 0.02 #ηパラメータ トピック数は試行錯誤しながら調整
15.
LDA実行 • LDAの実施とトピックの単語確認 library(lda) set.seed(357) fit <-
lda.collapsed.gibbs.sampler(documents = documents, K = K, vocab = vocab, num.iterations = G, alpha = alpha, eta = eta, initial = NULL, burnin = 0, compute.log.likelihood = TRUE) # 各トピックにおける上位3位の単語の行列。 top.words <- top.topic.words(fit$topics, 3, by.score = TRUE) print(top.words) >print(top.words) > [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] >[1,] "規模" "市" "補償" "くい" "棟" "こと" "福岡" "事業" "陥没" "現場” >[2,] "警察" "事故" "者" "危険" "倒壊" "2" "5" "問い合わせ" "1" "道路” >[3,] "7" "工事" "損失" "力" "福岡" "メートル" "詳しい" "JV" "4" "付近"
16.
LDA実行 • LDAの実施とトピックの単語確認 library(lda) set.seed(357) fit <-
lda.collapsed.gibbs.sampler(documents = documents, K = K, vocab = vocab, num.iterations = G, alpha = alpha, eta = eta, initial = NULL, burnin = 0, compute.log.likelihood = TRUE) # 各トピックにおける上位3位の単語の行列。 top.words <- top.topic.words(fit$topics, 3, by.score = TRUE) print(top.words) >print(top.words) > [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] >[1,] "規模" "市" "補償" "くい" "棟" "こと" "福岡" "事業" "陥没" "現場” >[2,] "警察" "事故" "者" "危険" "倒壊" "2" "5" "問い合わせ" "1" "道路” >[3,] "7" "工事" "損失" "力" "福岡" "メートル" "詳しい" "JV" "4" "付近" この状態だとよく分からないので可視化する
17.
LDA-Vis • パラメータ設定と実行 # パラメータ theta
<- t(apply(fit$document_sums + alpha, 2, function(x) x/sum(x))) phi <- t(apply(t(fit$topics) + eta, 2, function(x) x/sum(x))) # create the JSON object to feed the visualization: display_word_num = 20 #表示する単語数 json <- createJSON(phi = phi, theta = theta, doc.length = doc.length, vocab = vocab, term.frequency = term.frequency, R = display_word_num ) ## 古いvisフォルダがある場合はエラー出るので削除する事 serVis(json, out.dir = 'vis', open.browser = T )
18.
デモ
19.
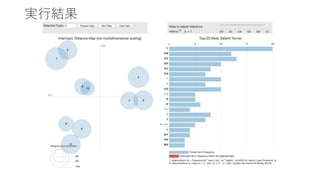
実行結果
20.
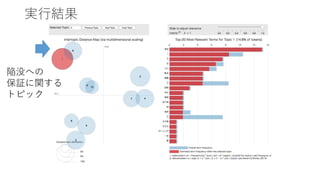
実行結果 陥没への 保証に関する トピック
21.
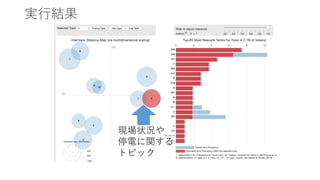
実行結果 現場状況や 停電に関する トピック
22.
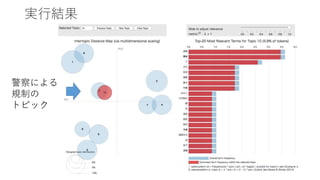
実行結果 警察による 規制の トピック
23.
LDA-Vis 所感 • LDA実行の状態から一手間加えるだけで使えて便利! •
探索的な発見に期待
24.
ブラウザでの確認 • 実行時に指定したout.dir にあるindex.htmlを実行するとブラウ ザでも確認が可能(FireFox推奨) •
マウスオーバーやクリック、パラメータ変更によりインタラク ティブに動作
25.
参考情報 • RMeCab • http://rmecab.jp/wiki/index.php?RMeCab •
LDA(+RMeCab) • http://qiita.com/HirofumiYashima/items/faaf857e49a065b5e0f1 • LDA-Vis • https://github.com/cpsievert/LDAvis/blob/master/README.md • http://cpsievert.github.io/LDAvis/reviews/reviews.html
26.
2.doradora09からお知らせ
27.
2010年より ご愛顧いただいていた BAR doradoraですが
28.
この度、諸事情により 移転することになりました!
29.
場所
30.
だいたいこのあたり
31.
だいたいこのあたり 福岡、博多近辺!
32.
BAR doradora福岡移転のお知らせ • 諸事情にて、年明け頃から福岡に引っ越し予定 •
(注:リアルに脱サラしてのBAR開業ではないです・・) • Tokyo.Rの後任スタッフ+BAR担当募集中 • fukuoka.Rに参加できると嬉しいです!! • 土地勘がないため九州出身の方、是非お話聞かせてください • あとは分析ごった煮勉強会とかも需要あれば。 • 遠方からの発表者も募集します。特典はもつ鍋。 • 詳細は懇親会にて!
33.
Enjoy!!
Download












![RMeCab
• RMeCabを使って名詞、形容詞のみに限定
setwd('/Users/apple/Desktop/ldavis_lt')
library(RMeCab)
tmp_doc.1 <- NULL
tmp_doc.1 <- RMeCabText("text_1.txt")
doc.1 <- NULL
for (i in 1:length(tmp_doc.1)) {
if (tmp_doc.1[[i]][2] %in% c("名詞", "形容詞")) {
doc.1 <- c(doc.1, paste(tmp_doc.1[[i]][1], sep = "", collapse = " "))
}
}
> head(doc.1)
[1] "博多" "駅" "前" "道路" "7" "センチ"](https://image.slidesharecdn.com/20161127doradora09japanr2016lt-161127071628/85/20161127-doradora09-japanr2016_lt-11-320.jpg)

![LDA準備
• 文章がどの単語に一致するかでindex化
get.terms <- function(x) {
index <- match(x, vocab)
index <- index[!is.na(index)]
rbind(as.integer(index - 1), as.integer(rep(1, length(index))))
}
documents <- NULL
documents <- lapply(doc.list, get.terms) > head(documents)
>$doc1
> [,1] [,2] [,3] [,4] [,5]
>[1,] 17 46 231 4 42
>[2,] 1 1 1 1 1](https://image.slidesharecdn.com/20161127doradora09japanr2016lt-161127071628/85/20161127-doradora09-japanr2016_lt-13-320.jpg)
![LDA準備
• LDA用の各種パラメータの準備
D <- length(documents) # 記事の数
W <- length(vocab) # 単語の数
doc.length <- sapply(documents, function(x) sum(x[2, ])) #記事ごとの単語数
N <- sum(doc.length) # トータルの単語数
term.frequency <- as.integer(term.table)
K <- 10 ## トピック数
G <- 200 ## 反復回数
alpha <- 0.02 #αパラメータ
eta <- 0.02 #ηパラメータ
トピック数は試行錯誤しながら調整](https://image.slidesharecdn.com/20161127doradora09japanr2016lt-161127071628/85/20161127-doradora09-japanr2016_lt-14-320.jpg)
![LDA実行
• LDAの実施とトピックの単語確認
library(lda)
set.seed(357)
fit <- lda.collapsed.gibbs.sampler(documents = documents, K = K, vocab = vocab,
num.iterations = G, alpha = alpha,
eta = eta, initial = NULL, burnin = 0,
compute.log.likelihood = TRUE)
# 各トピックにおける上位3位の単語の行列。
top.words <- top.topic.words(fit$topics, 3, by.score = TRUE)
print(top.words)
>print(top.words)
> [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
>[1,] "規模" "市" "補償" "くい" "棟" "こと" "福岡" "事業" "陥没" "現場”
>[2,] "警察" "事故" "者" "危険" "倒壊" "2" "5" "問い合わせ" "1" "道路”
>[3,] "7" "工事" "損失" "力" "福岡" "メートル" "詳しい" "JV" "4" "付近"](https://image.slidesharecdn.com/20161127doradora09japanr2016lt-161127071628/85/20161127-doradora09-japanr2016_lt-15-320.jpg)
![LDA実行
• LDAの実施とトピックの単語確認
library(lda)
set.seed(357)
fit <- lda.collapsed.gibbs.sampler(documents = documents, K = K, vocab = vocab,
num.iterations = G, alpha = alpha,
eta = eta, initial = NULL, burnin = 0,
compute.log.likelihood = TRUE)
# 各トピックにおける上位3位の単語の行列。
top.words <- top.topic.words(fit$topics, 3, by.score = TRUE)
print(top.words)
>print(top.words)
> [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
>[1,] "規模" "市" "補償" "くい" "棟" "こと" "福岡" "事業" "陥没" "現場”
>[2,] "警察" "事故" "者" "危険" "倒壊" "2" "5" "問い合わせ" "1" "道路”
>[3,] "7" "工事" "損失" "力" "福岡" "メートル" "詳しい" "JV" "4" "付近"
この状態だとよく分からないので可視化する](https://image.slidesharecdn.com/20161127doradora09japanr2016lt-161127071628/85/20161127-doradora09-japanr2016_lt-16-320.jpg)