Compact, Efficient and
UnlimitedCapacity:
Language Modeling with
Compressed SuffixTrees
Ehsan Shareghi, Matthias Petri,Gholamreza Haffari and
Trevor Cohn
2015/10/24 EMNLP読み会
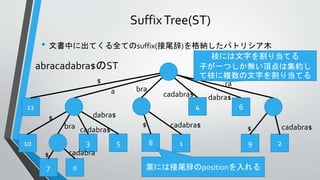
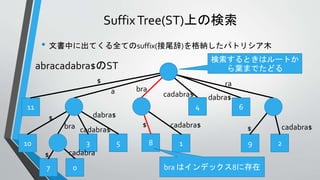
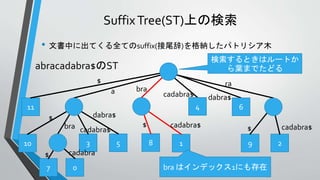
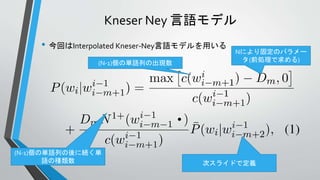
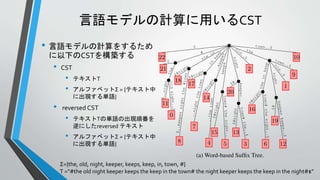
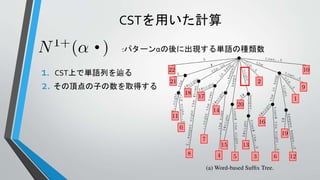
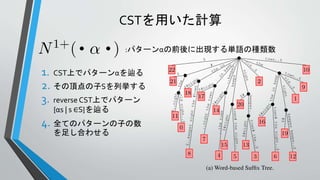
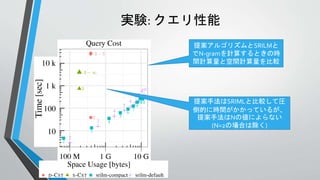
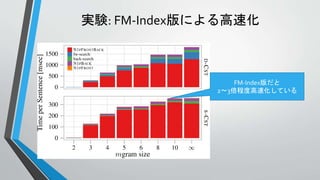
言語モデルの計算に用いるCST
• 言語モデルの計算をするため
に以下のCSTを構築する
• CST
•テキストT
• アルファベットΣ = {テキスト中
に出現する単語}
• reversed CST
• テキストTの単語の出現順番を
逆にしたreversed テキスト
• アルファベットΣ = {テキスト中
に出現する単語}
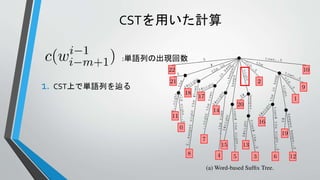
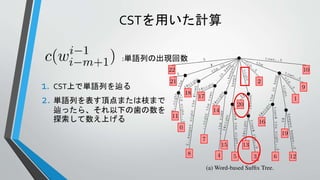
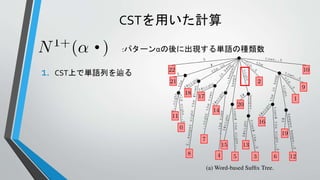
Σ={the, old, night, keeper, keeps, keep, in, town, #}
T =“#the old night keeper keeps the keep in the town# the night keeper keeps the keep in the night#$”





































![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)







![A Neural Attention Model for Sentence Summarization [Rush+2015]](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp2015yomi-151024073845-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)












