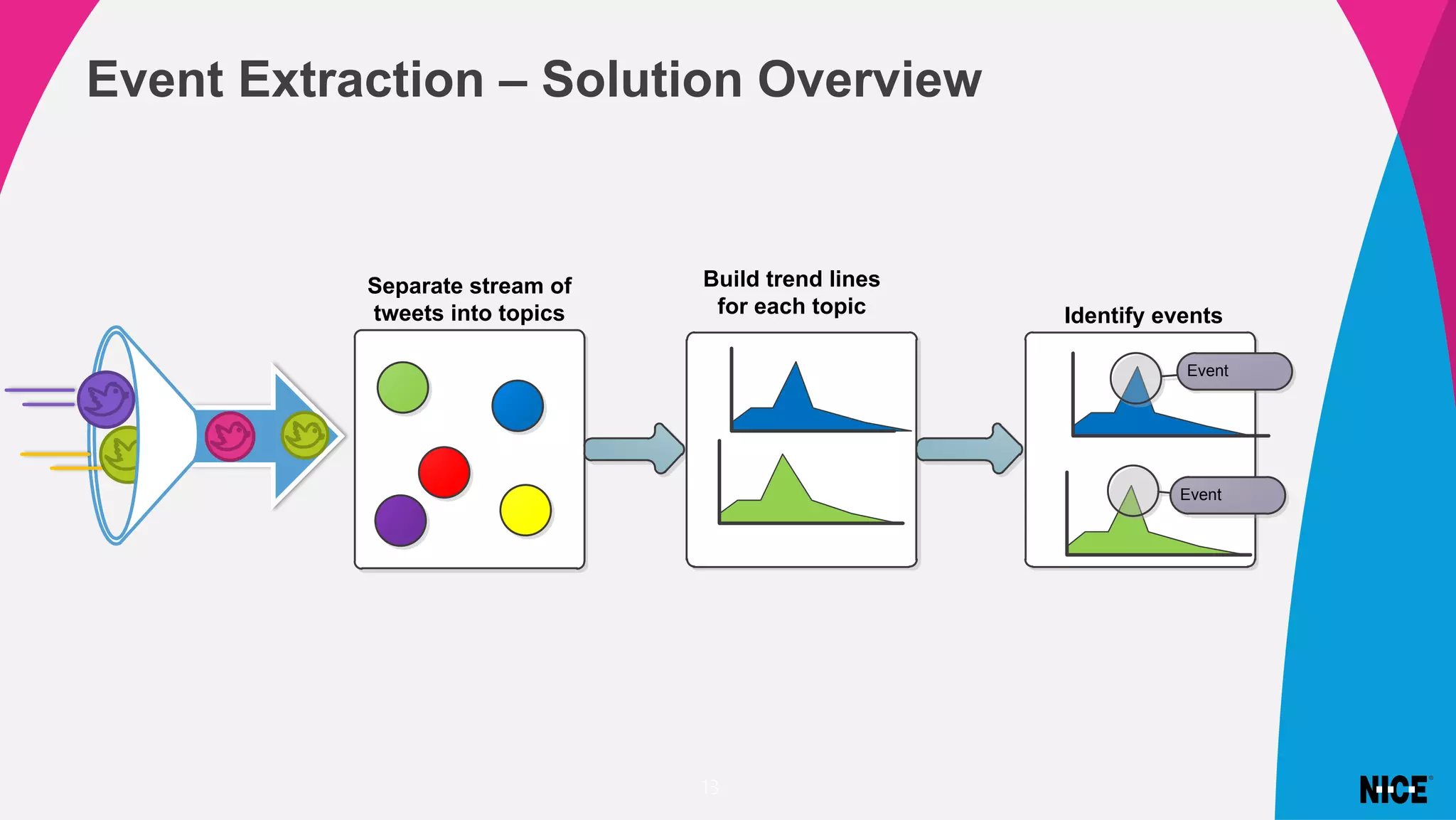
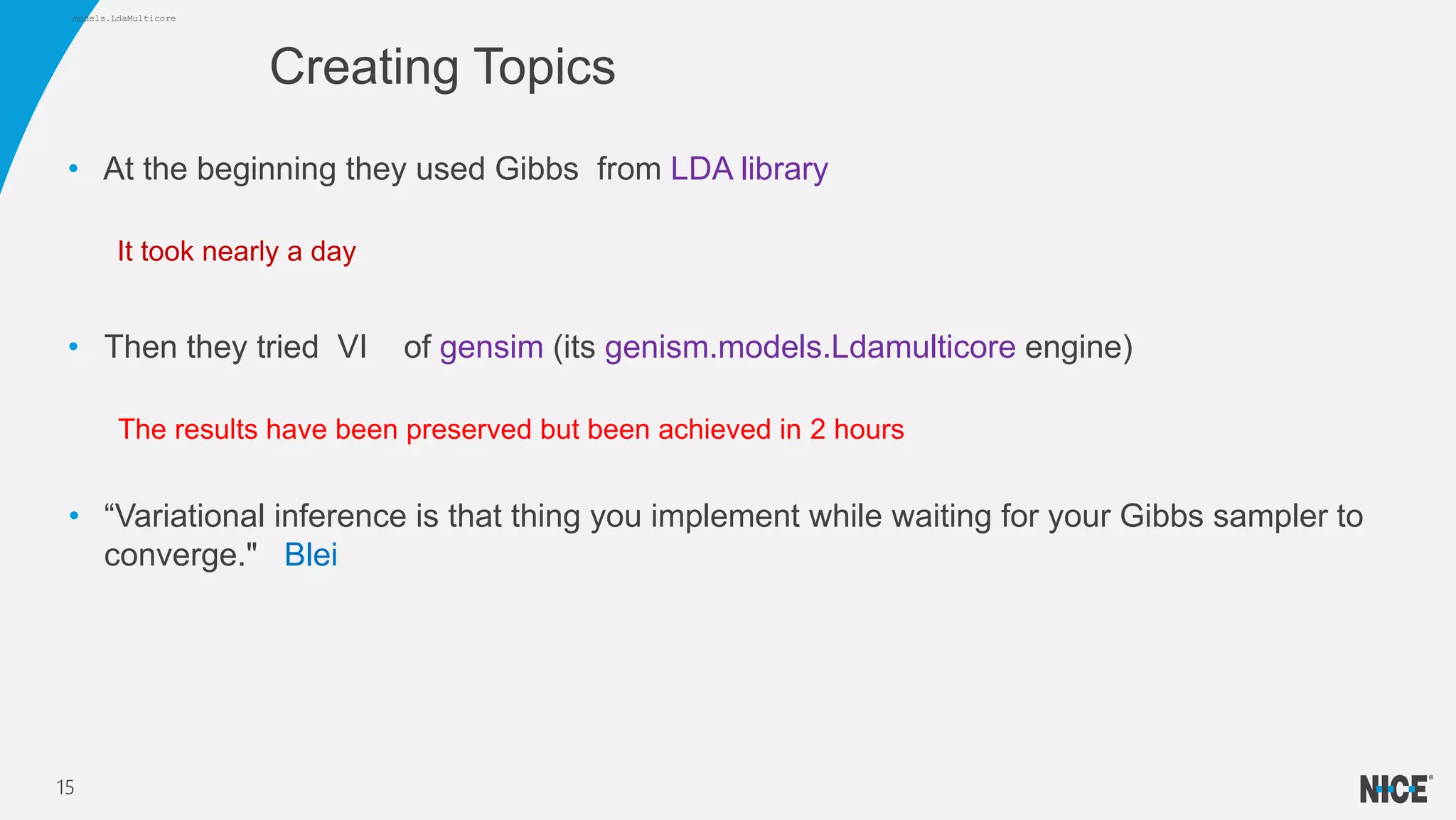
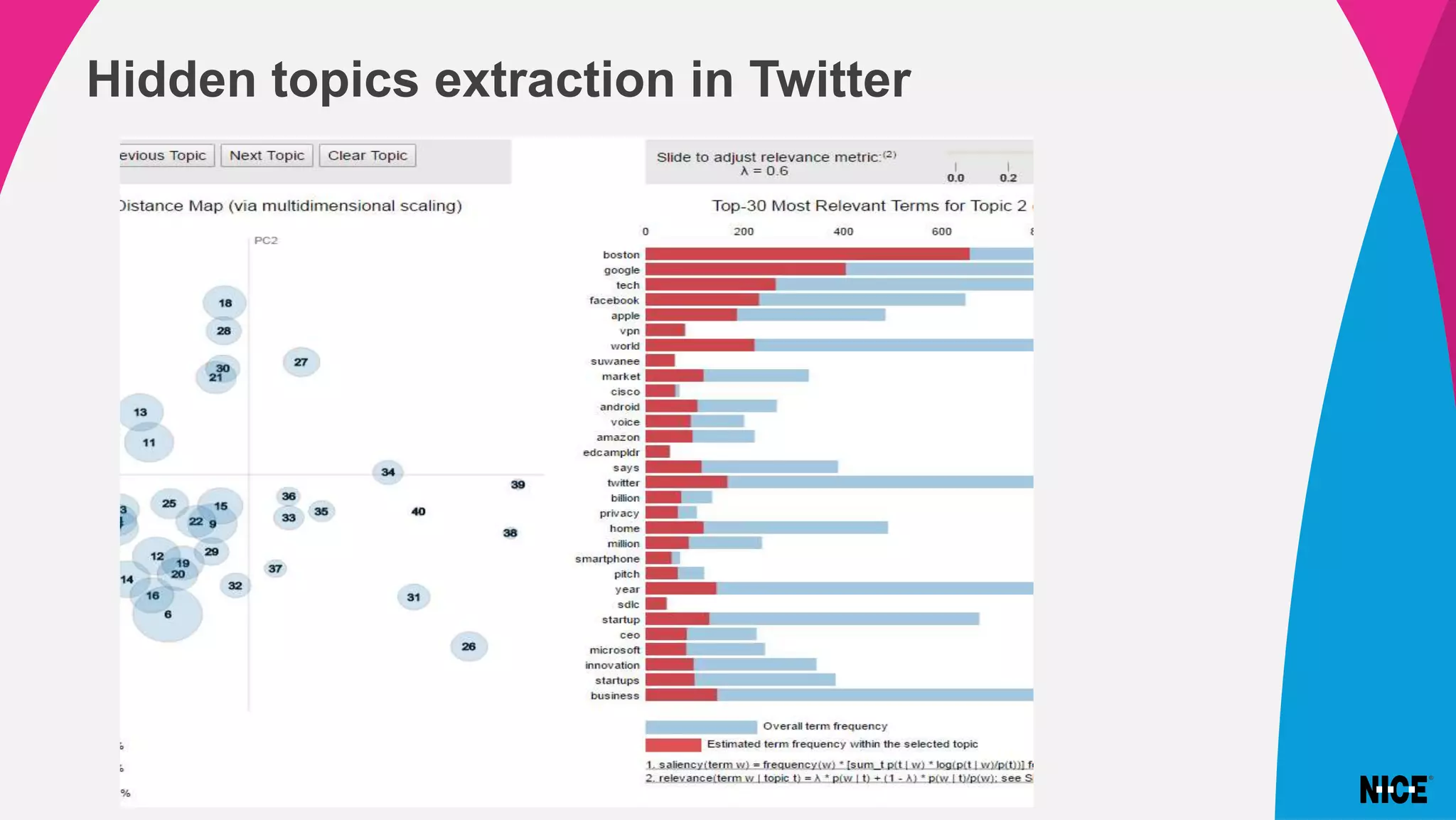
Variational inference is a technique for approximating intractable distributions by optimizing a tractable variational distribution. It was used by Infomedia to identify global events from Twitter data by separating tweets into topics using latent Dirichlet allocation (LDA). Initially Gibbs sampling for LDA took nearly a day but variational inference using Gensim's LDA model converged much faster in 2 hours. Variational inference works by choosing a family of distributions and minimizing the Kullback-Leibler divergence between the true posterior and the variational distribution. This can be done using coordinate ascent variational inference or stochastic variational inference for large datasets.

















![Cross Entropy
(P,Q)= H(P)+ KL(P||Q)
PMI Pointwise mutual information
• Let X,Y random variables
• PMI(X,Y)=Log[
𝑃(𝑋=𝑎,𝑌=𝑏)
𝑃 𝑋=𝑎 𝑃(𝑌=𝑏)
]
• KL(P(X/Y=a)||Q(x)) = 𝑥 𝑃(𝑋 = 𝑥|𝑌 = 𝑎)PMI(X=x, Y=a)
KL- Applications
21](https://image.slidesharecdn.com/lectmodifiedaa-200107133015/75/NICE-Research-Variational-inference-project-21-2048.jpg)
![Can we approximate P(Z|X)?
min KL(Q(z)|| P(Z|X))
We have:
log(P(X)) = 𝐸 𝑄 [log P(x, Z)] − 𝐸 𝑄 [log Q(Z)] + KL(Q(Z)||P(Z|X))
ELBO-Evidence Lower Bound
Remarks
1. LHS is indecent on Z
2. log(P(X)) ≥ ELBO (log concavity)
Hence: Maximizing ELBO =>minimizing KL
VI -Let’s Develop
22](https://image.slidesharecdn.com/lectmodifiedaa-200107133015/75/NICE-Research-Variational-inference-project-22-2048.jpg)
![𝐸𝐿𝐵𝑂 = 𝐸 𝑄[log P(X, Z)] − 𝐸 𝑄 [log Q(Z)] = 𝑄𝐿𝑜𝑔(
𝑃(𝑋,𝑍)
𝑄(𝑍)
)= J(Q)
Q may have enormous number of variables, can we do more?
VI Development
23](https://image.slidesharecdn.com/lectmodifiedaa-200107133015/75/NICE-Research-Variational-inference-project-23-2048.jpg)

![• If if Ising & Lenz can do it .why don’t we?
• We assume independency rather non-correlation
𝐸𝐿𝐵𝑂 = 𝐸 𝑄[log P(X, Z)] − 𝐸 𝑄 [log Q(Z)]
Q becomes Q(z) = 𝑖=1
𝑛
𝑞𝑖(𝑧𝑖) (Obviously not true)
• We can use now Euler –Lagrange with the constrain
𝑞𝑖(z) =1
L𝑜𝑔(𝑞𝑖) = 𝑐𝑜𝑛𝑠𝑡 + 𝐸−𝑖[𝑝 𝑥, 𝑧 ] Bolzman Dist.! (as said . We are as good as Ising)
Back to VI
25](https://image.slidesharecdn.com/lectmodifiedaa-200107133015/75/NICE-Research-Variational-inference-project-25-2048.jpg)

![• Blei 2018 VI- A review for statistics
The basic step is set sequentially each 𝑞𝑖 to 𝐸−𝑖[𝑝 𝑥, 𝑧 ] +constant
No 𝑖 𝑡ℎ
coordinate in the RHS (Independency)
Simply update each q until a convergence of ELBO
Coordinate Ascent Variational Inference
CAVI
28](https://image.slidesharecdn.com/lectmodifiedaa-200107133015/75/NICE-Research-Variational-inference-project-28-2048.jpg)





















































































