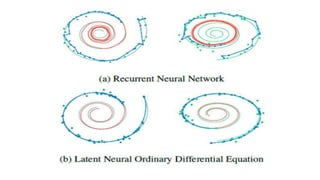
The document provides an overview of Neural ODEs, highlighting their significance in deep learning and referencing key research from NeurIPS 2018. It explains the basics of ordinary differential equations (ODE), their applications, and how they can be used to solve neural network problems, including methods like the adjoint method for backpropagation. Additionally, it discusses continuous normalizing flows and the potential of Neural ODEs in modeling data that is irregularly sampled.









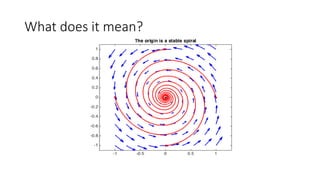
![ODE –Basic Terminology
𝑥 =f(x) or 𝑥 =f(x,t)
Initial condition
Let the eq. 𝑥 =f(x) we add the initial condition x[0] =c
Example:
𝑥=x by integrating both sides we get
x[t] =𝑒 𝑡
a . We need the i.c. to determine a](https://image.slidesharecdn.com/neuralode-190203201658/85/Neural-ODE-9-320.jpg)








![Adjoint Method (cont.)
So what do they do in the paper?
𝑧 =f(z,t,θ)
We assume a loss L s.t.
L(z(T) =L[z (0) + 0
𝑇
𝑓 𝑧, 𝑡, θ 𝑑𝑡] -ODE solver friendly
We define
a(T) =
𝜕𝐿
𝜕𝑧(𝑇)
What is actually z(T)?](https://image.slidesharecdn.com/neuralode-190203201658/85/Neural-ODE-20-320.jpg)


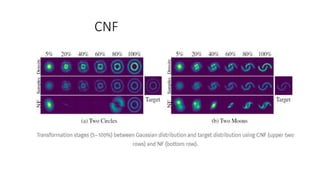
![Continuous Normalization Flow- CNF
• A method that maps a generic distribution (Gaussianexponents)
Into a more complicate distributions through a sequence of maps
𝑓1 , 𝑓2 , 𝑓3 .…. 𝑓𝑘
The main difficulties here are:
𝑧1= 𝑓(𝑧0 ) => log 𝑝(𝑧1)=log 𝑝(𝑧0) -log det(𝑓𝑍[𝑧0])
Calculating determinants is “costly”.](https://image.slidesharecdn.com/neuralode-190203201658/85/Neural-ODE-24-320.jpg)