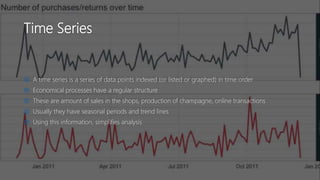
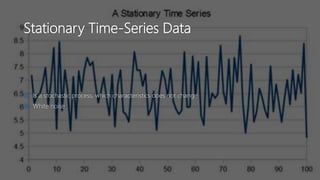
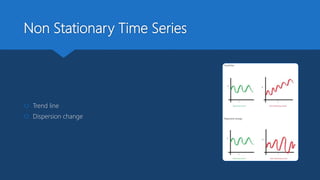
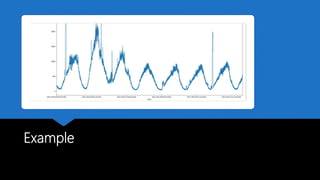
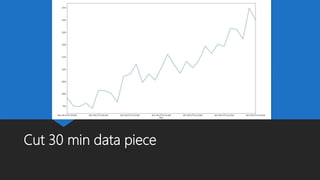
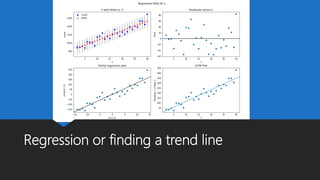
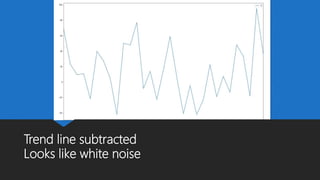
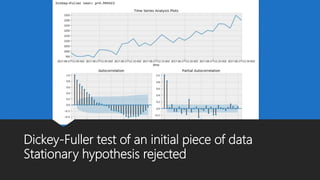
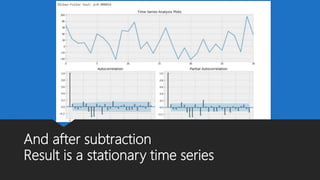
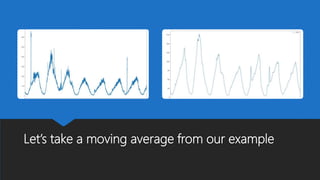
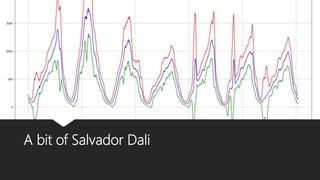
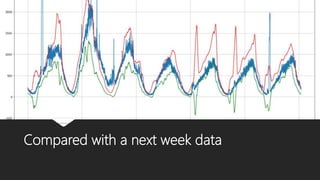
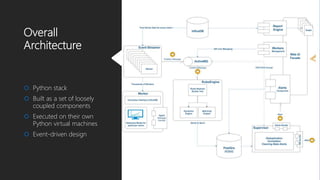
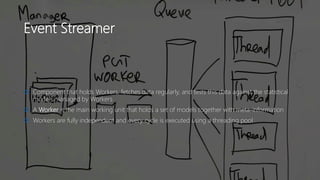
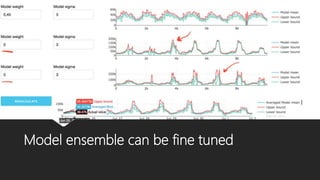
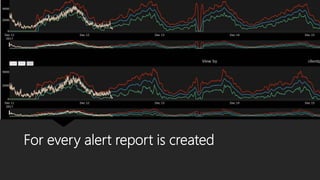
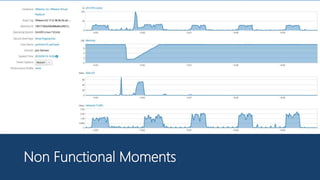
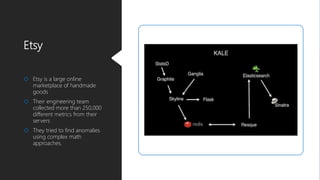
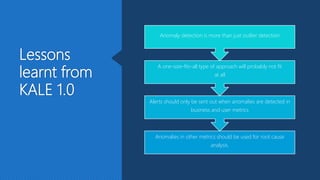
The document discusses Playtech's strategies for mastering failure detection in distributed systems, covering key concepts such as observability, monitoring, and instrumentation. It highlights the challenges faced in system monitoring and presents case studies from companies like Etsy and Google on anomaly detection and time series analysis. Additionally, it outlines Playtech's architecture, emphasizing an event-driven design with a focus on efficiency in monitoring and alerting processes.








![Google SRE team’s BorgMon
Google has trended toward simpler and faster monitoring
systems, with better tools for post hoc analysis
[They] avoid “magic” systems that try to learn thresholds or
automatically detect causality
Rules that generate alerts for humans should be simple to
understand and represent a clear failure
According to the authors of Site Reliability Engineering](https://image.slidesharecdn.com/dzonewebinar-181210122053/85/Monitoring-Distributed-Systems-11-320.jpg)