

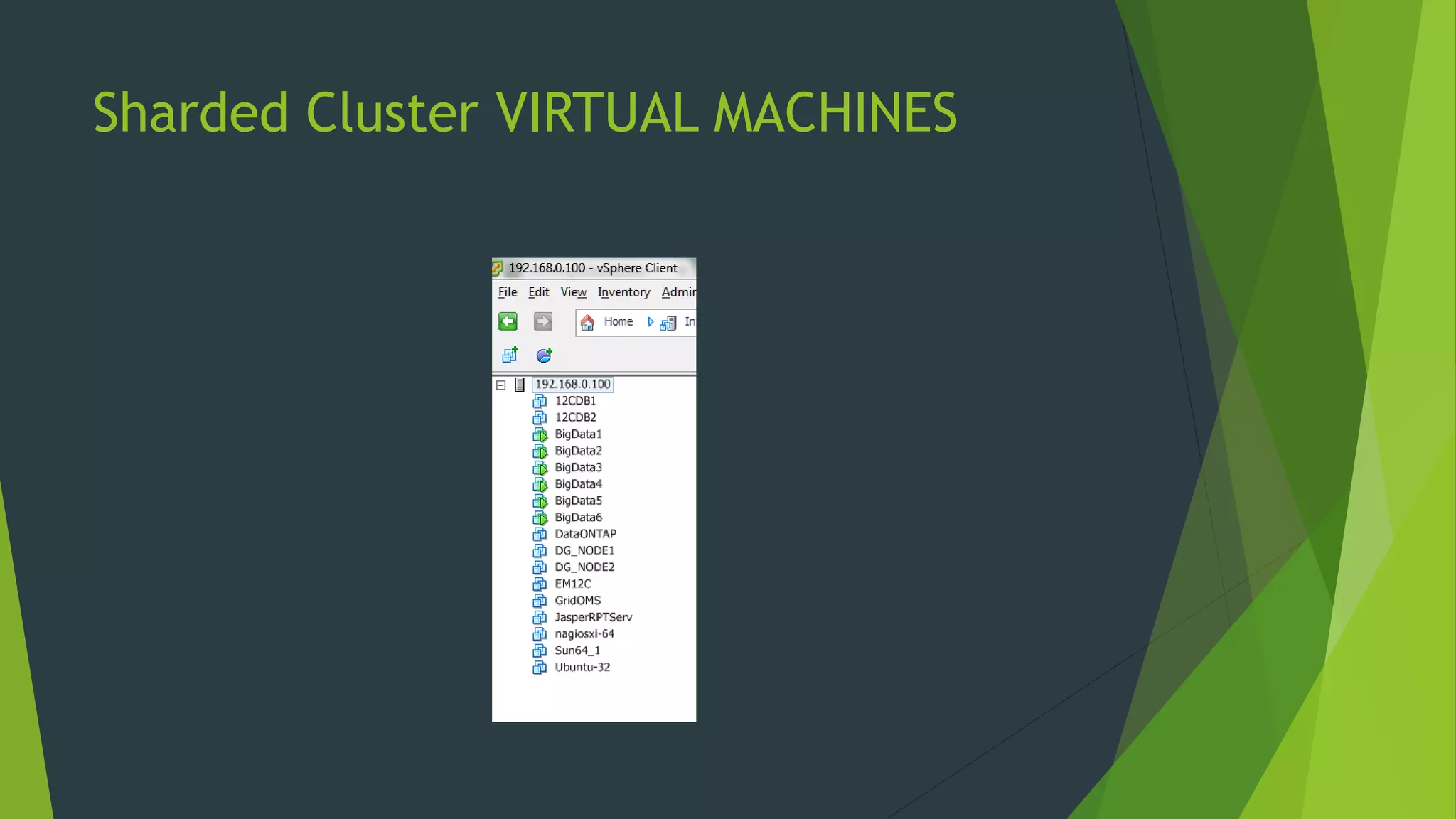
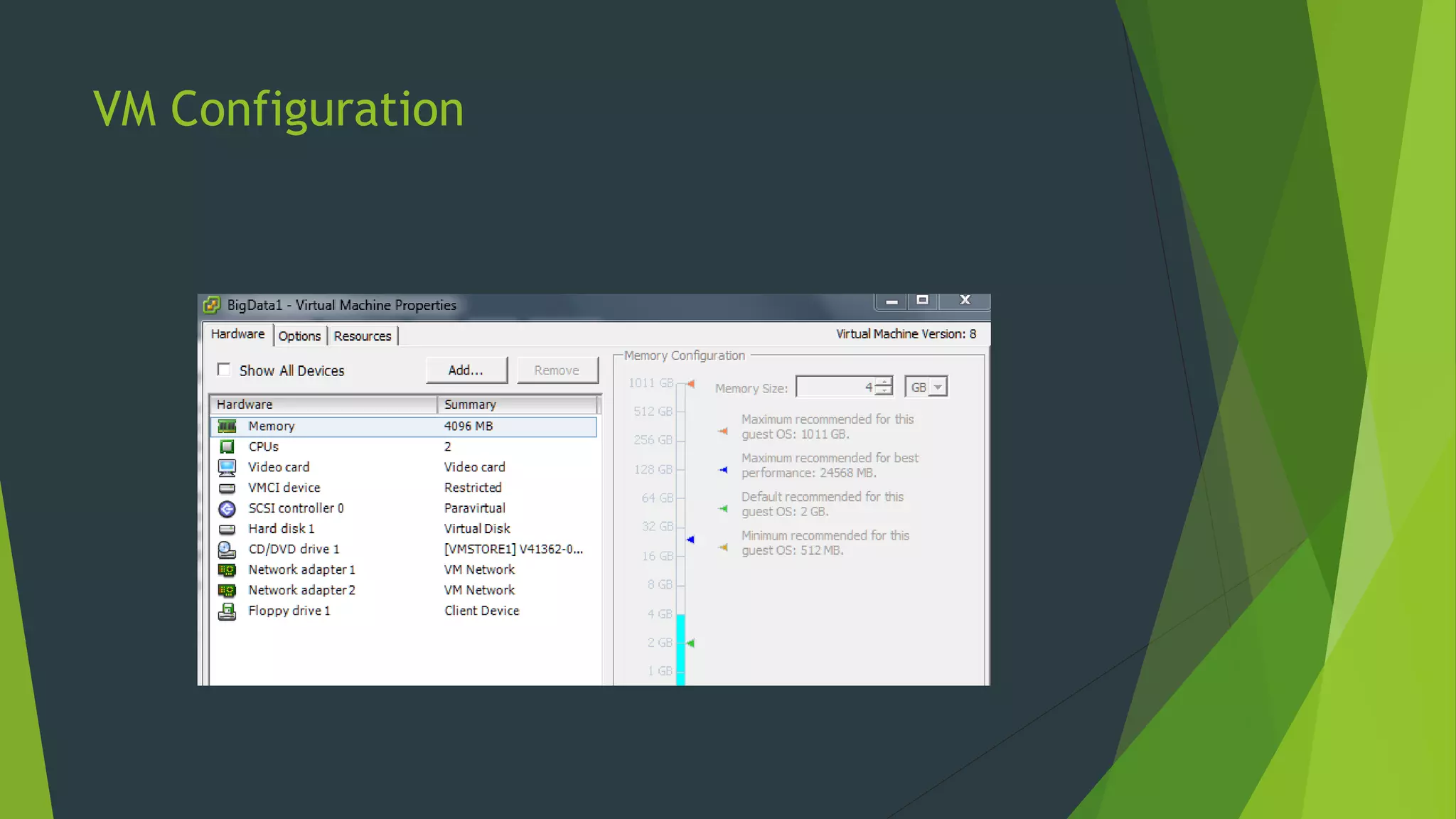
![Installing mongdb
The following steps guide you through installing mongodb software on Linux.
set yum repository and download packages using yum package installer.
[root@bigdata1 ~]# cd /etc/yum.repos.d/
[root@bigdata1 yum.repos.d]# cat mongodb.repo
[mongodb]
name=MongoDB Repository
baseurl=http://downloads-distro.mongodb.org/repo/redhat/os/x86_64/
gpgcheck=0
enabled=1
Before you run “yum install”, be sure to check internet is working.
[root@bigdata6 yum.repos.d]# yum install -y mongodb-org-2.6.1 mongodb-org-server-2.6.1
mongodb-org-shell-2.6.1 mongodb-org-mongos-2.6.1 mongodb-org-tools-2.6.1](https://image.slidesharecdn.com/settingupmongodbshardedclusterin30minutes-150905021858-lva1-app6891/75/Setting-up-mongodb-sharded-cluster-in-30-minutes-5-2048.jpg)


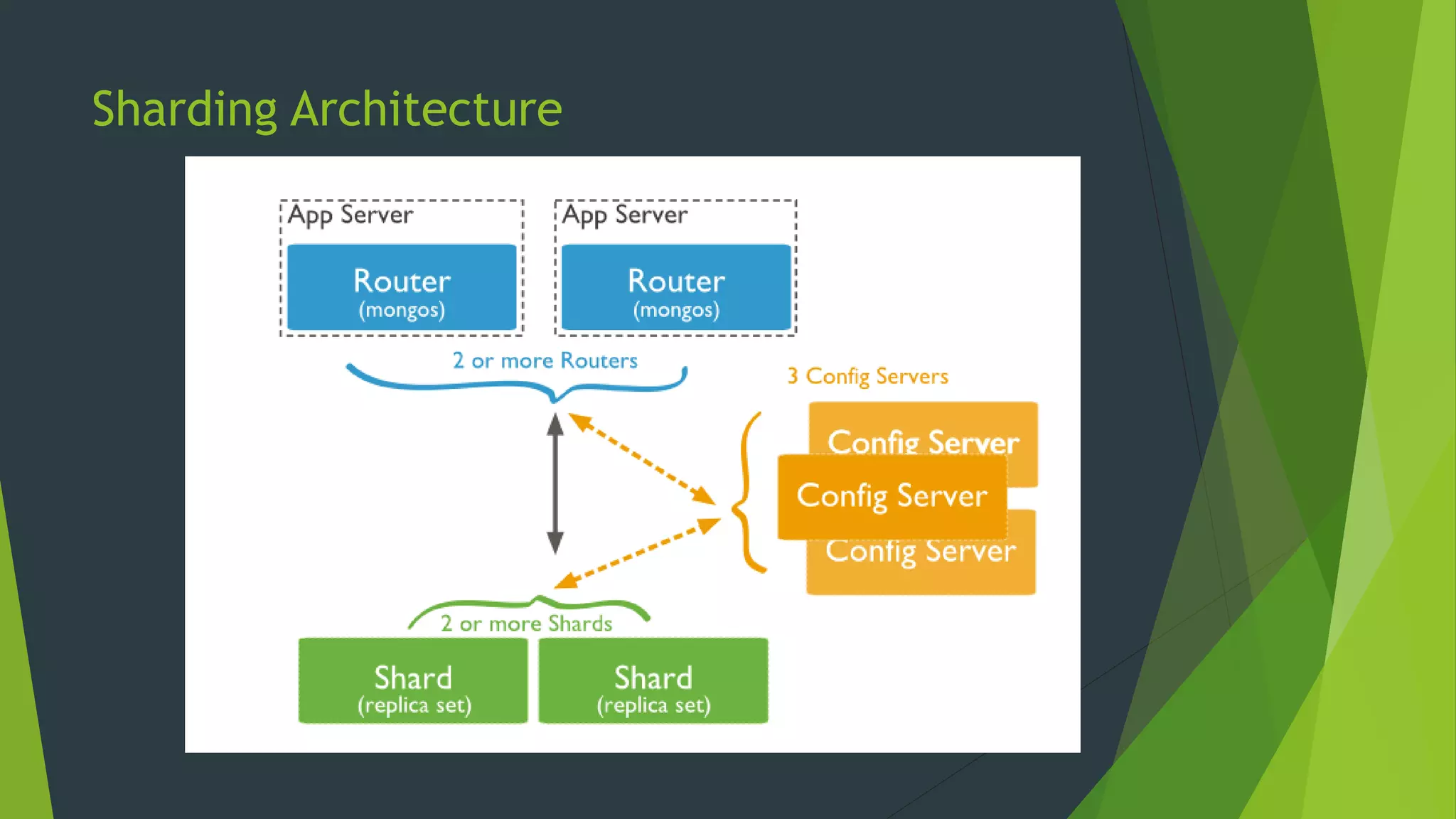

![Add Shards to the Cluster
Enable Sharding for a Database
Enabling sharding for a database does not redistribute data but make it possible to shard the
collections in that database.
From a mongo shell, connect to the mongos instance. Issue a command using the following
[hdfs@bigdata3 ~]$ mongo --host bigdata2 --port 27017
MongoDB shell version: 2.6.1
connecting to: bigdata2:27017/test
rs0:PRIMARY>
sh.addShard("rs0/bigdata1:27017")
sh.addShard("rs0/bigdata2:27017")
sh.addShard("rs0/bigdata3:27017")
sh.addShard("rs0/bigdata4:27017")
sh.addShard("rs0/bigdata5:27017")
sh.addShard("rs0/bigdata6:27017")](https://image.slidesharecdn.com/settingupmongodbshardedclusterin30minutes-150905021858-lva1-app6891/75/Setting-up-mongodb-sharded-cluster-in-30-minutes-10-2048.jpg)


The document describes how to configure and deploy a MongoDB sharded cluster with 6 virtual machines in 30 minutes. It provides step-by-step instructions on installing MongoDB, setting up the config servers, adding shards, and enabling sharding for databases and collections. Key aspects include designating MongoDB instances as config servers, starting mongos processes connected to the config servers, adding shards by hostname and port, and enabling sharding on specific databases and collections with shard keys.
![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)









![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)




![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
