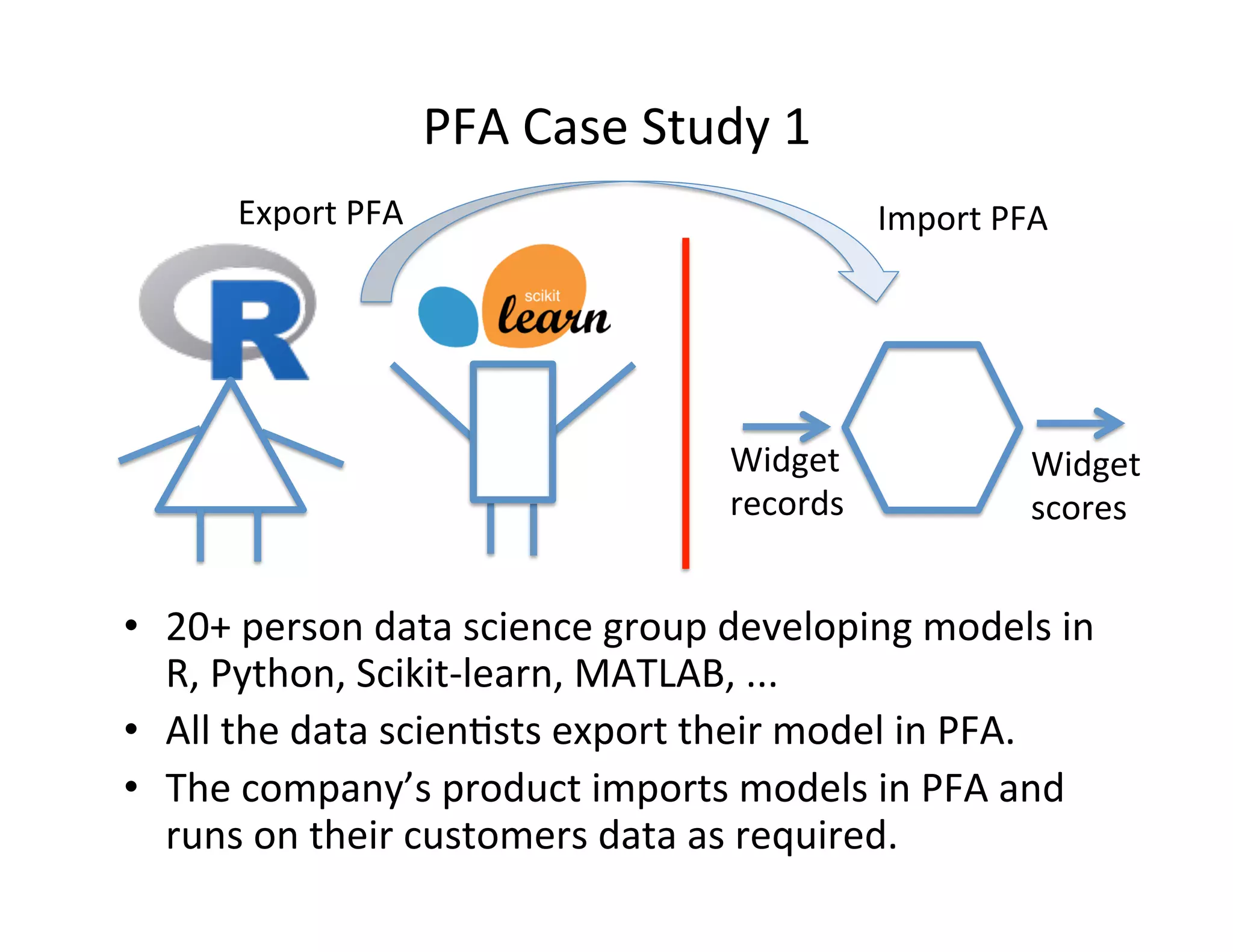
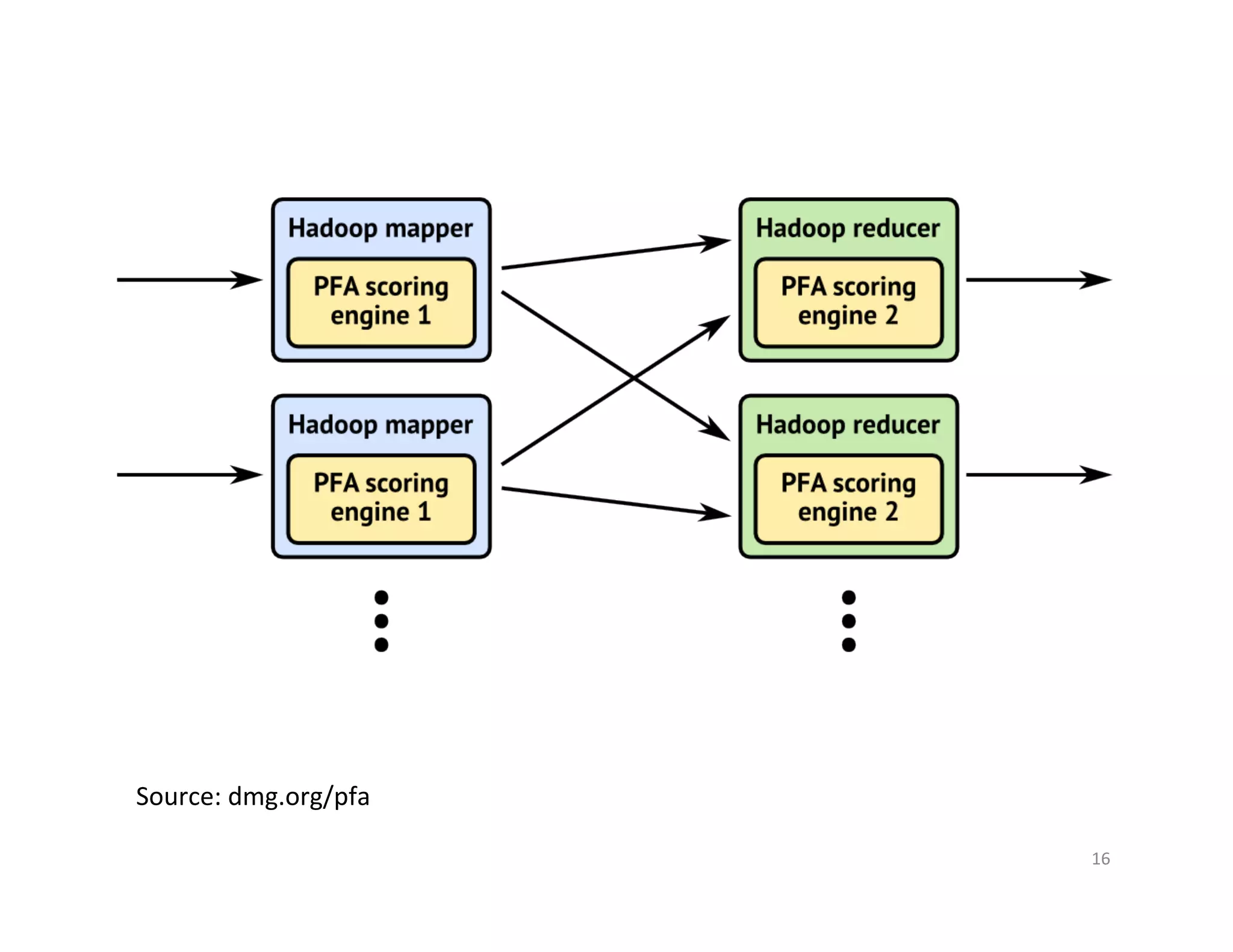
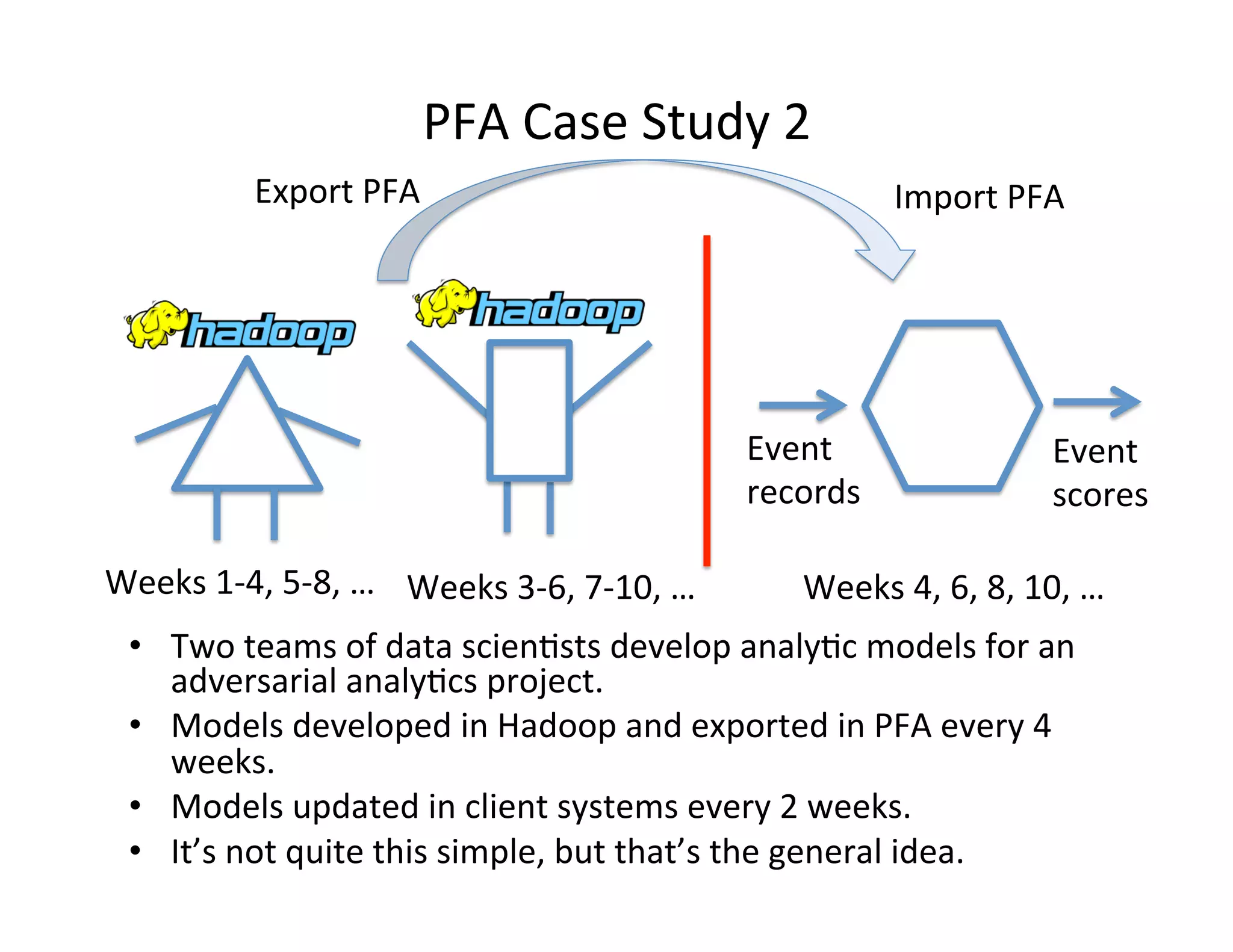
Downloaded 21 times







![PFA
Func*onality
• PFA
codes
arbitrary
mathema*cal
algorithms
in
a
*ghtly
controlled
environment.
• PFA
has
all
the
standard
flow
control
of
a
programming
language:
if/then/else
&
for/while
loops.
• PFA
has
func*on
calls
and
func*on
call
backs
• PFA
has
algebraic
data
types.
• PFA
is
encoded
as
func*on
calls
in
JSON
{func*on:
[arg
1,
arg
2,
…,
arg
n]
}
13](https://image.slidesharecdn.com/analytic-ops-paw-chicago-16-v4-160625001836/75/AnalyticOps-Chicago-PAW-2016-13-2048.jpg)



![Gaussian
Process
Model
(2
of
5)
input: {type: array, items: double}
output: {type: array, items: double}
cells:
table:
type:
{type: array, items: {type: record, name: GP, fields: [
- {name: x, type: {type: array, items: double}}
- {name: to, type: {type: array, items: double}}
- {name: sigma, type: {type: array, items: double}}]}}
init:
- {x: [ 0, 0], to: [0.01870587, 0.96812508], sigma: [0.2, 0.2]}
- {x: [ 0, 36], to: [0.00242101, 0.95369720], sigma: [0.2, 0.2]}
- {x: [ 0, 72], to: [0.13131668, 0.53822666], sigma: [0.2, 0.2]}
...
- {x: [324, 324], to: [-0.6815587, 0.82271760], sigma: [0.2, 0.2]}
action:
model.reg.gaussianProcess:
- input
- {cell: table}
- null
- {fcn: m.kernel.rbf, fill: {gamma: 2.0}}
input
and
output
of
scoring
engine
expressed
as
Avro
schemas
Source:
dmg.org/pfa](https://image.slidesharecdn.com/analytic-ops-paw-chicago-16-v4-160625001836/75/AnalyticOps-Chicago-PAW-2016-19-2048.jpg)
![Gaussian
Process
Model
(3
of
5)
input: {type: array, items: double}
output: {type: array, items: double}
cells:
table:
type:
{type: array, items: {type: record, name: GP, fields: [
- {name: x, type: {type: array, items: double}}
- {name: to, type: {type: array, items: double}}
- {name: sigma, type: {type: array, items: double}}]}}
init:
- {x: [ 0, 0], to: [0.01870587, 0.96812508], sigma: [0.2, 0.2]}
- {x: [ 0, 36], to: [0.00242101, 0.95369720], sigma: [0.2, 0.2]}
- {x: [ 0, 72], to: [0.13131668, 0.53822666], sigma: [0.2, 0.2]}
...
- {x: [324, 324], to: [-0.6815587, 0.82271760], sigma: [0.2, 0.2]}
action:
model.reg.gaussianProcess:
- input
- {cell: table}
- null
- {fcn: m.kernel.rbf, fill: {gamma: 2.0}}
type
(also
Avro)
and
value
(as
JSON,
truncated)
Gaussian
Process
model
parameters
Source:
dmg.org/pfa](https://image.slidesharecdn.com/analytic-ops-paw-chicago-16-v4-160625001836/75/AnalyticOps-Chicago-PAW-2016-20-2048.jpg)
![Gaussian
Process
Model
(4
of
5)
input: {type: array, items: double}
output: {type: array, items: double}
cells:
table:
type:
{type: array, items: {type: record, name: GP, fields: [
- {name: x, type: {type: array, items: double}}
- {name: to, type: {type: array, items: double}}
- {name: sigma, type: {type: array, items: double}}]}}
init:
- {x: [ 0, 0], to: [0.01870587, 0.96812508], sigma: [0.2, 0.2]}
- {x: [ 0, 36], to: [0.00242101, 0.95369720], sigma: [0.2, 0.2]}
- {x: [ 0, 72], to: [0.13131668, 0.53822666], sigma: [0.2, 0.2]}
...
- {x: [324, 324], to: [-0.6815587, 0.82271760], sigma: [0.2, 0.2]}
action:
model.reg.gaussianProcess:
- input
- {cell: table}
- null
- {fcn: m.kernel.rbf, fill: {gamma: 2.0}}
calling
method:
parameters
expressed
as
JSON
input:
get
interpola*on
point
from
input
{cell:
table}:
get
parameters
from
table
null:
no
explicit
Kriging
weight
(universal)
{fcn:
…}:
kernel
func*on
Source:
dmg.org/pfa](https://image.slidesharecdn.com/analytic-ops-paw-chicago-16-v4-160625001836/75/AnalyticOps-Chicago-PAW-2016-21-2048.jpg)


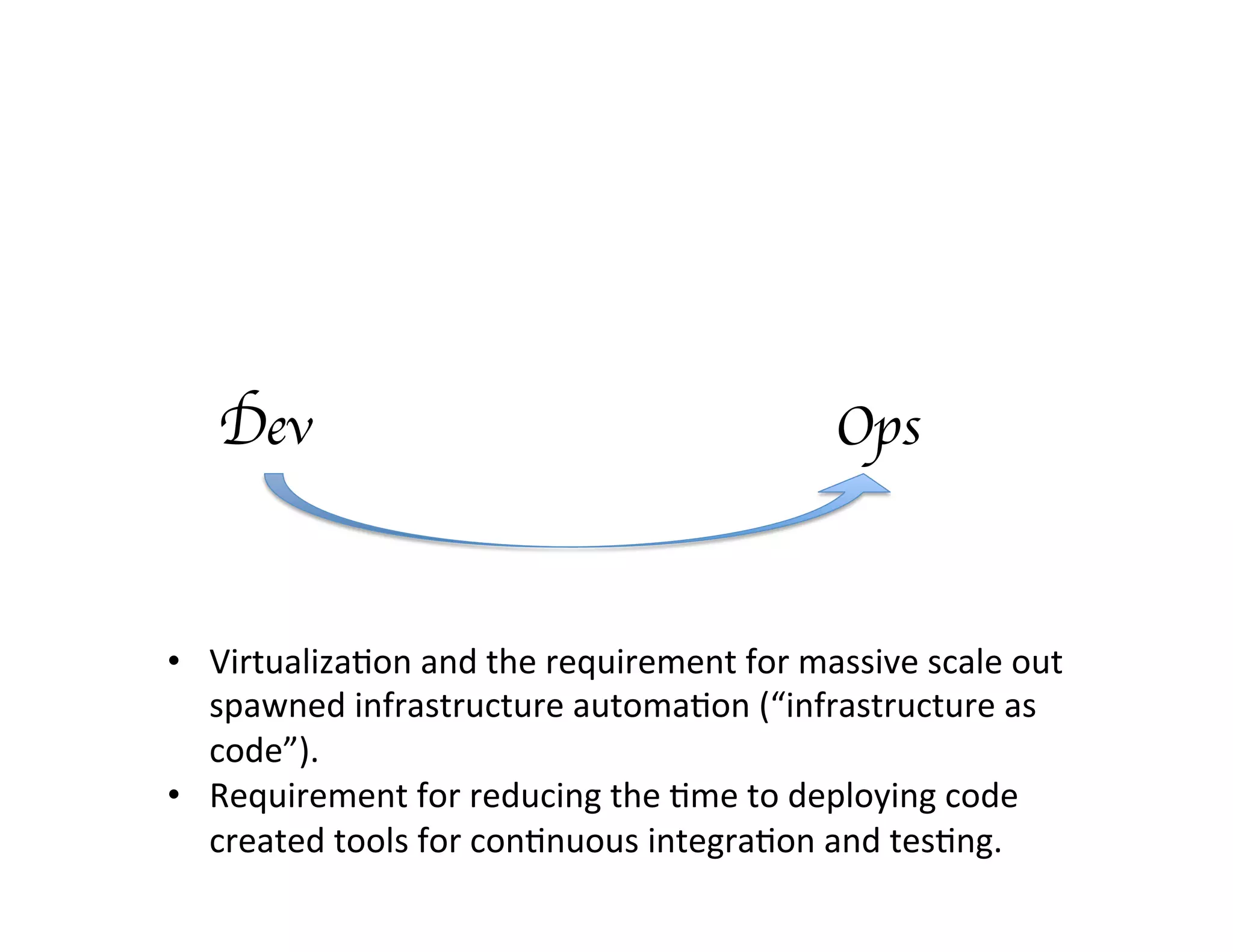

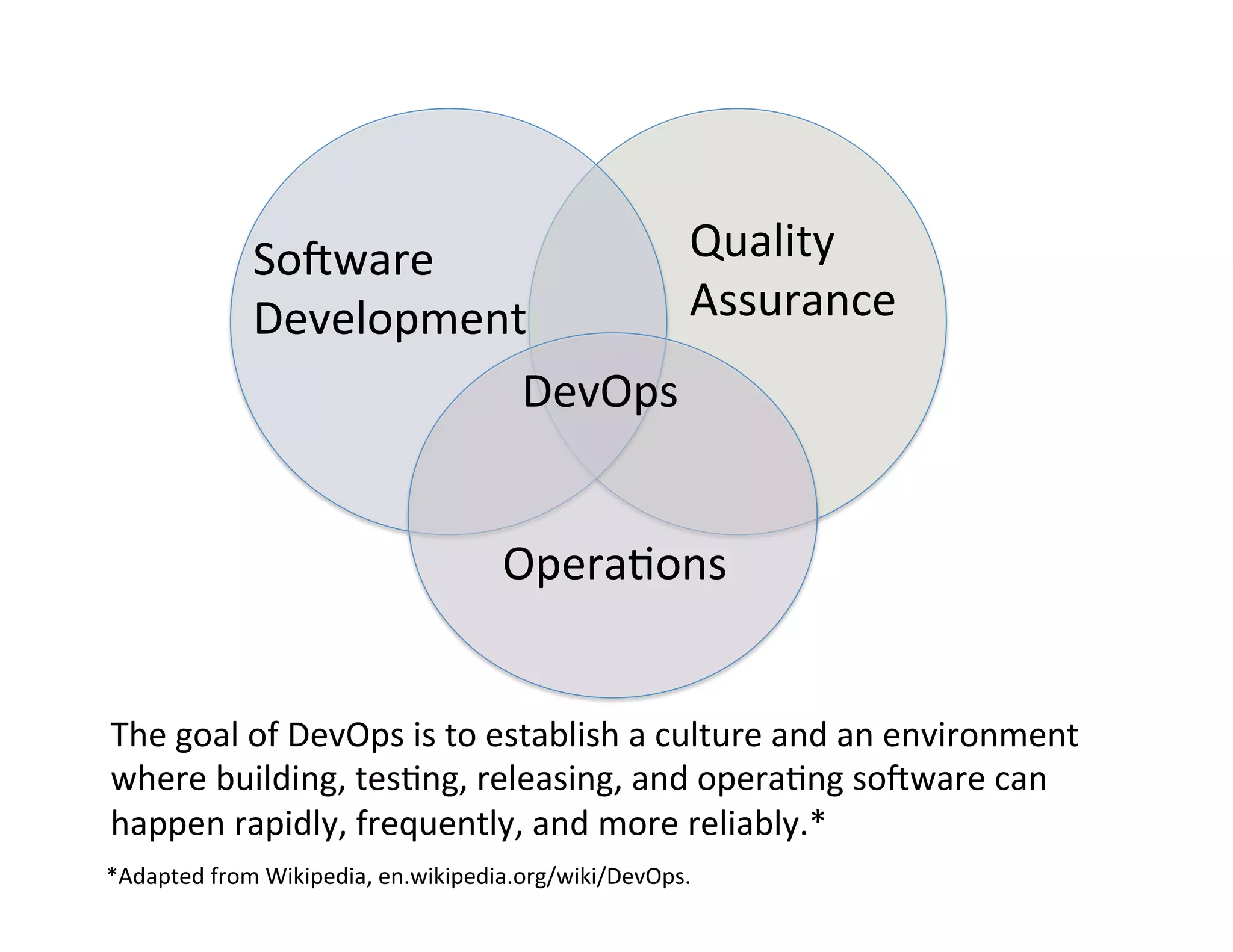
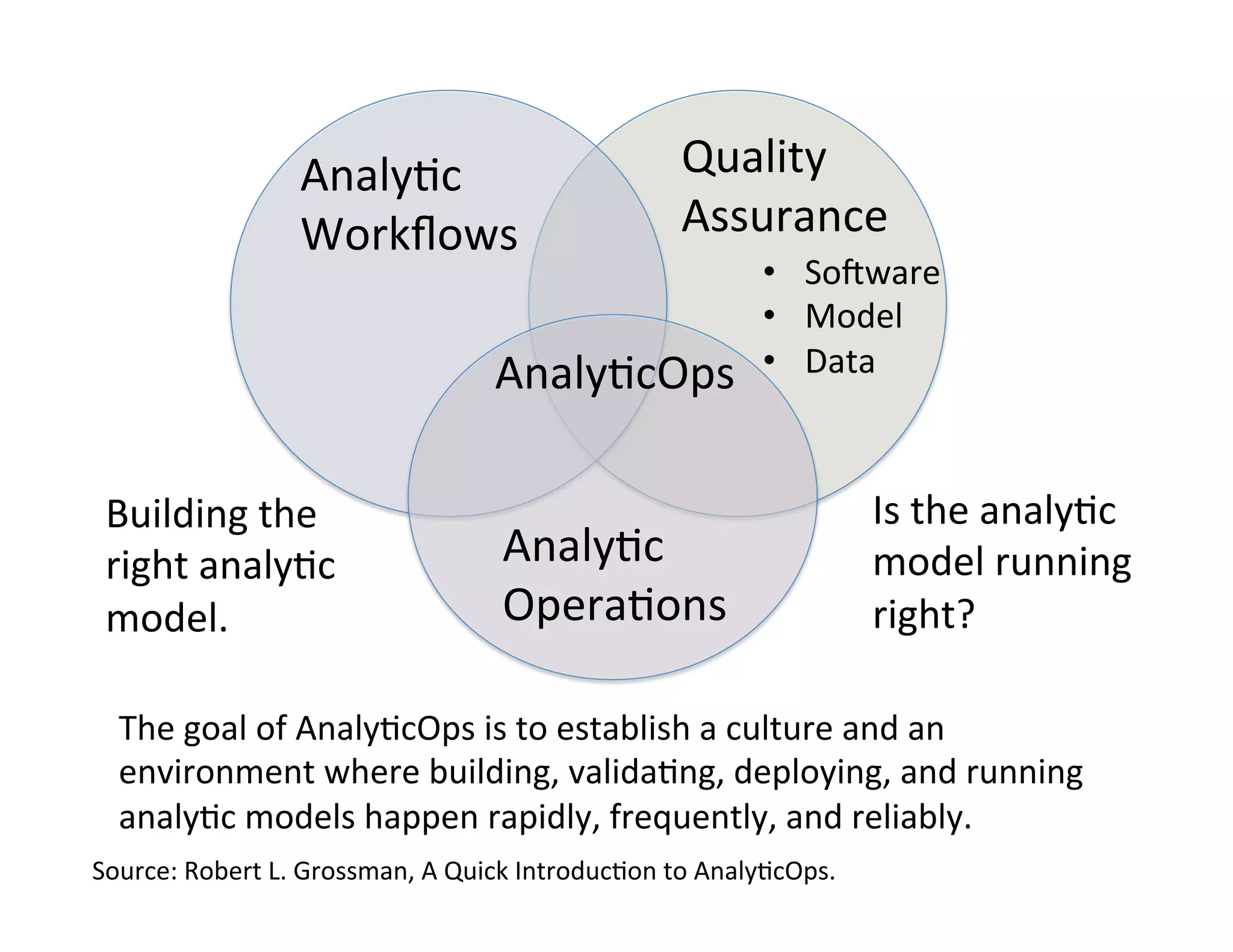




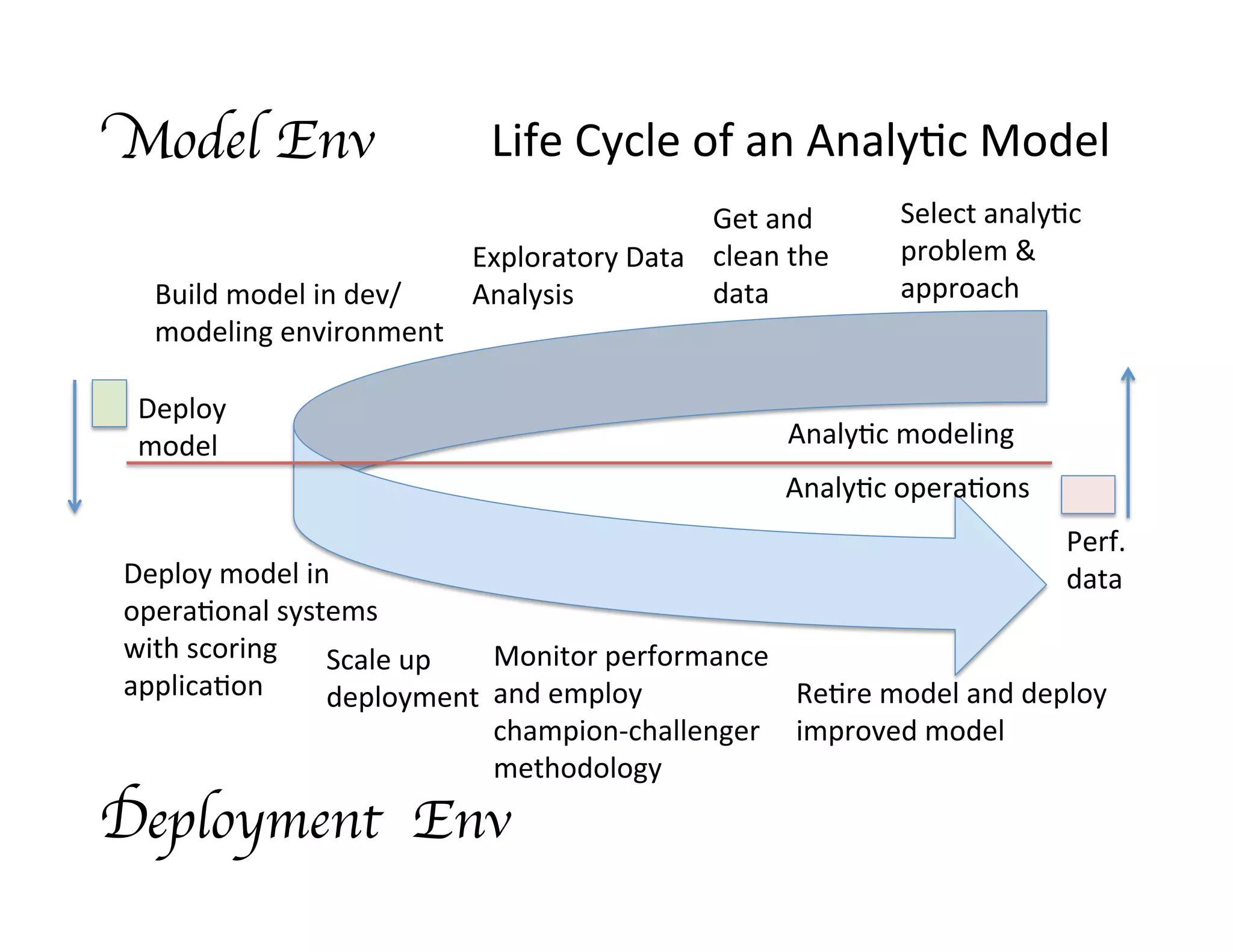
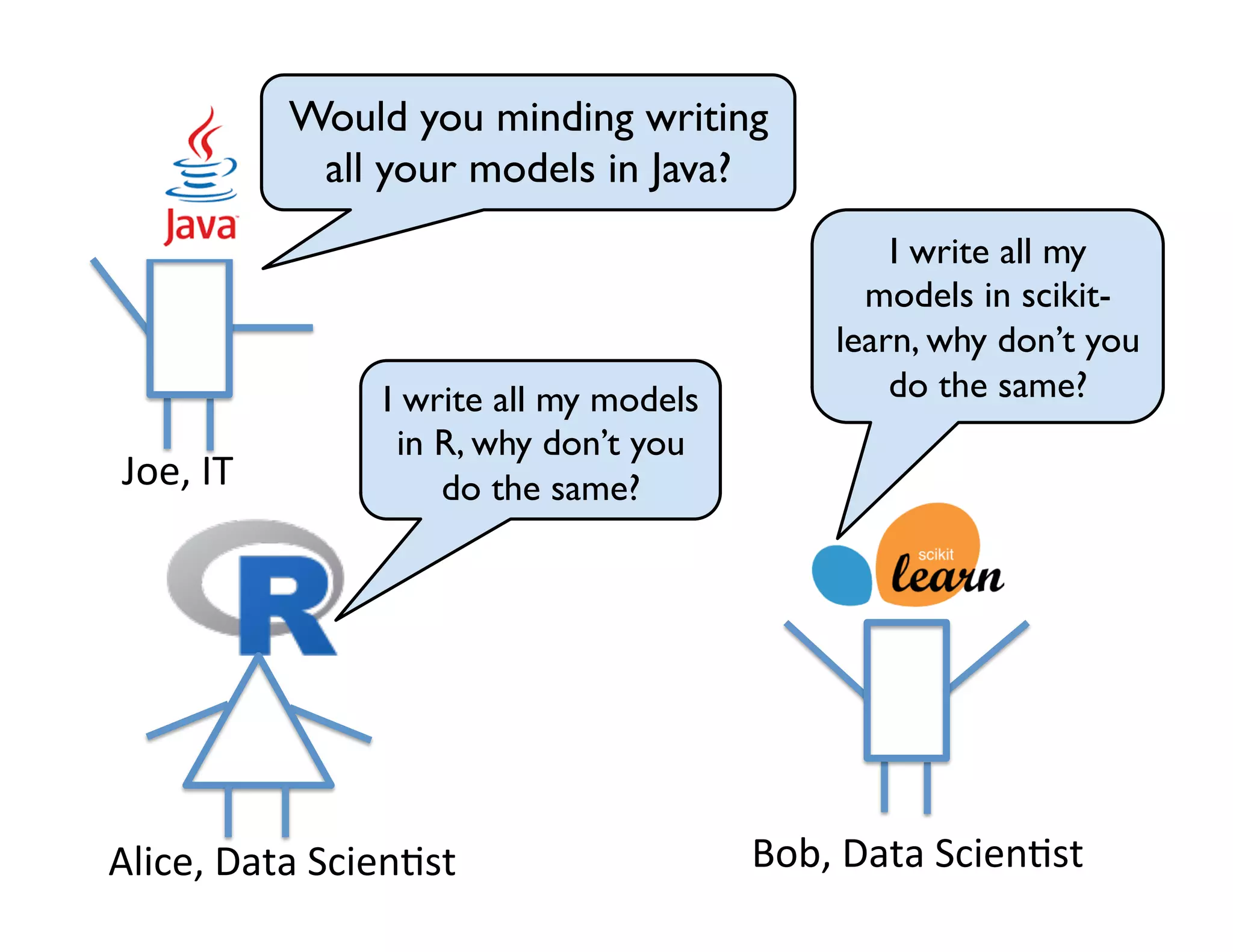
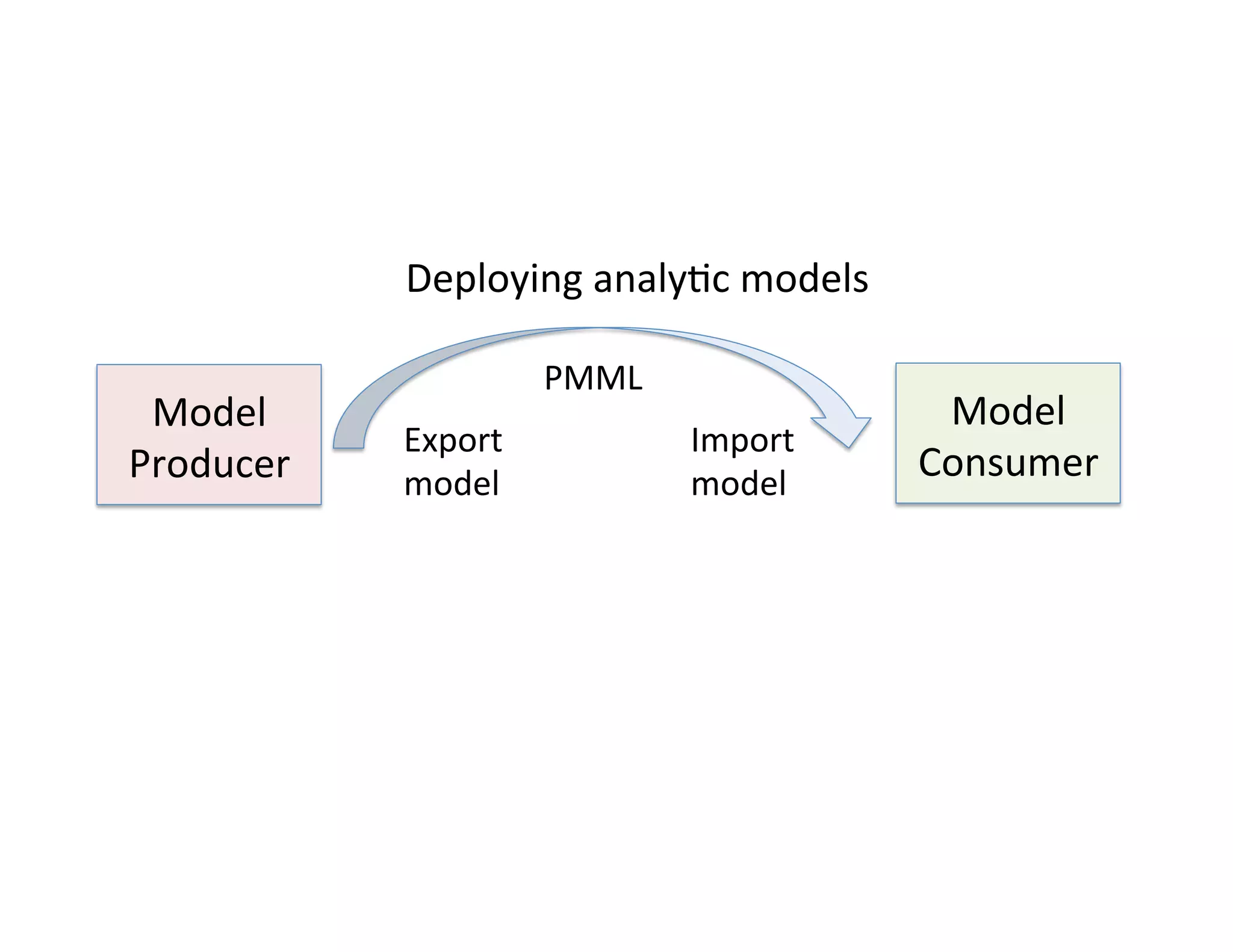
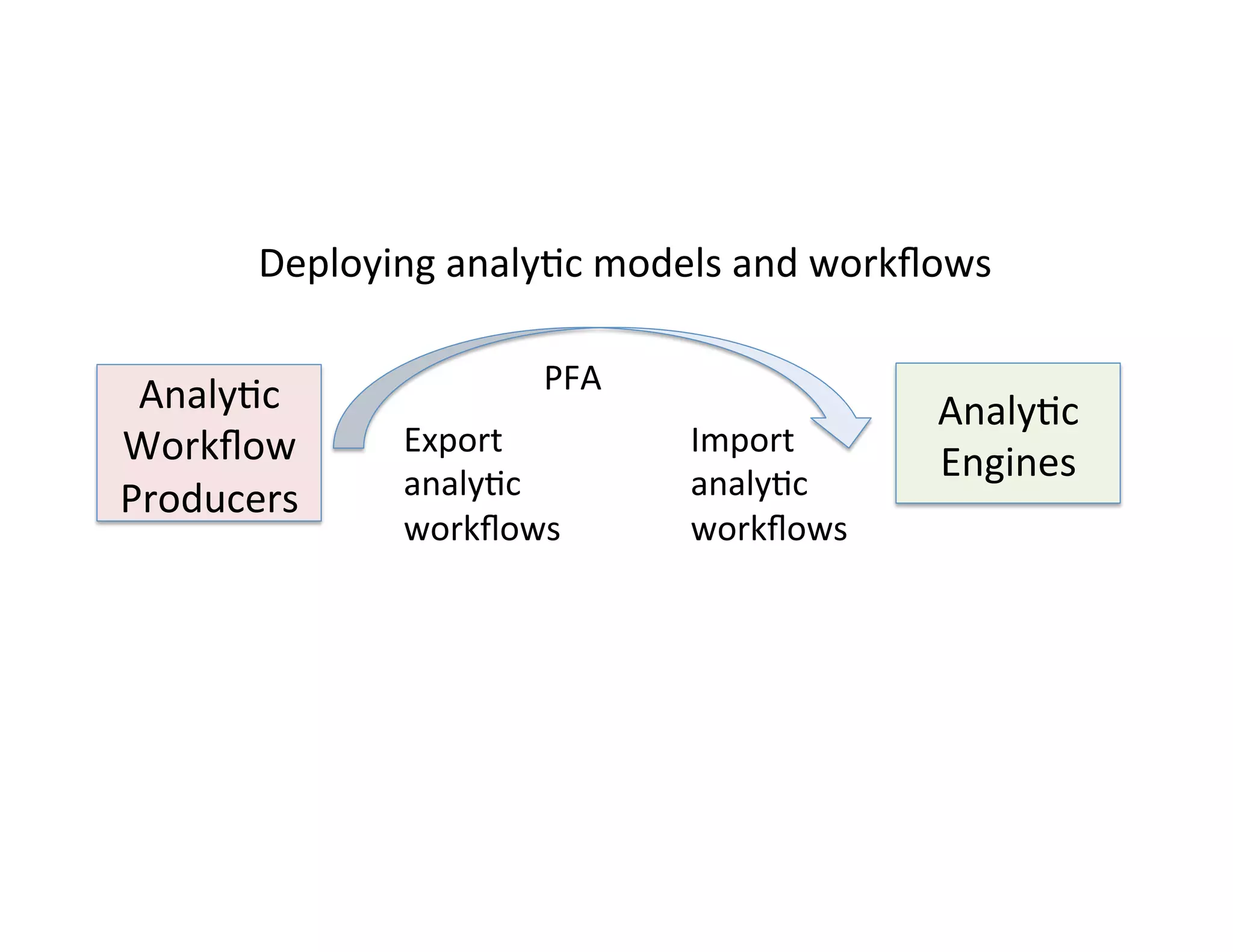
This document discusses best practices for deploying analytic models from development environments into operational systems. It describes how modeling environments often use different languages than deployment environments, requiring significant effort to move models. The document outlines the life cycle of analytic models, from exploratory data analysis to model deployment and monitoring. It also discusses standards like PMML and PFA that can be used to export models between different applications and analytic engines that integrate models into operational workflows.















































































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)









![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)



