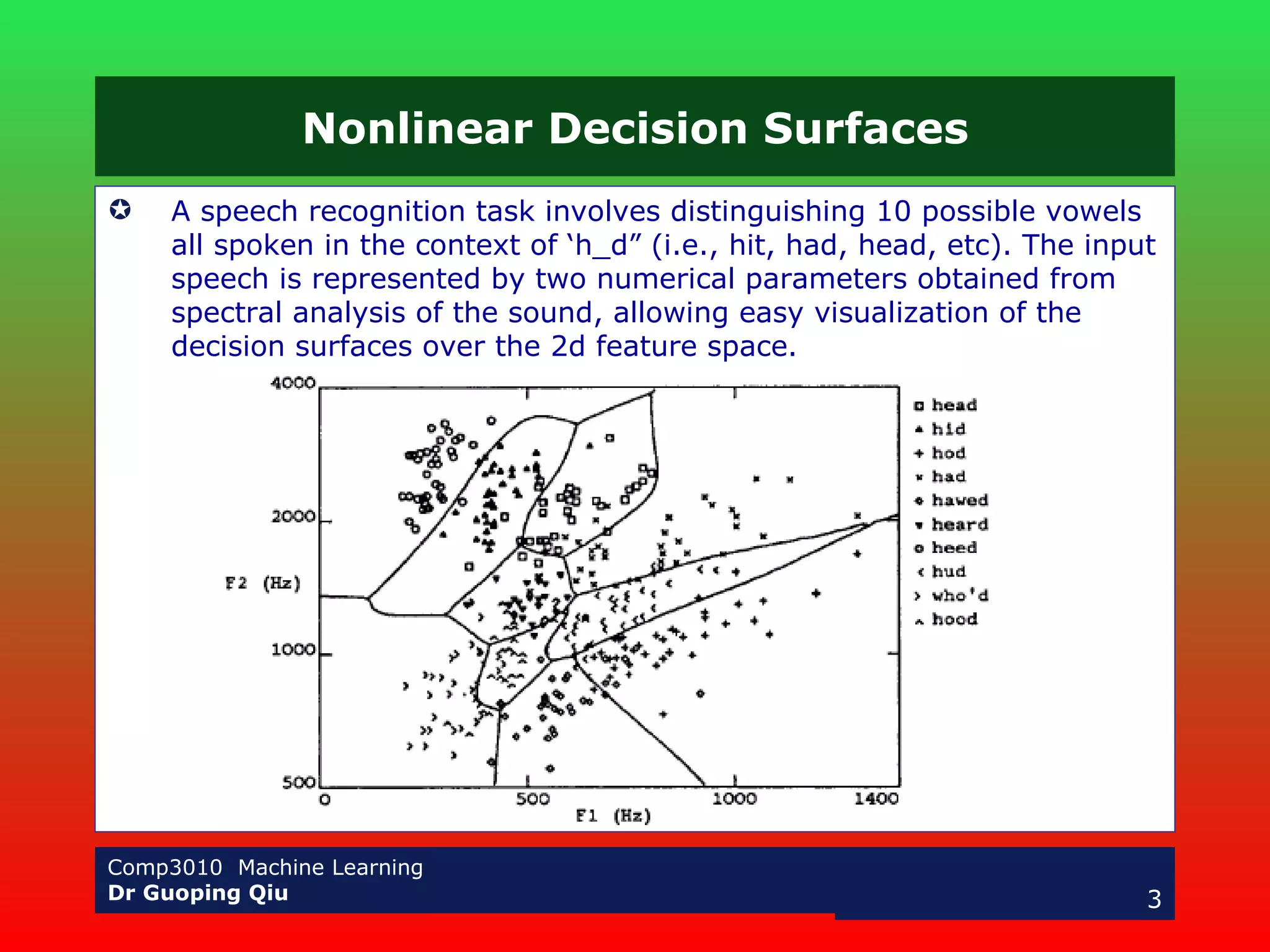
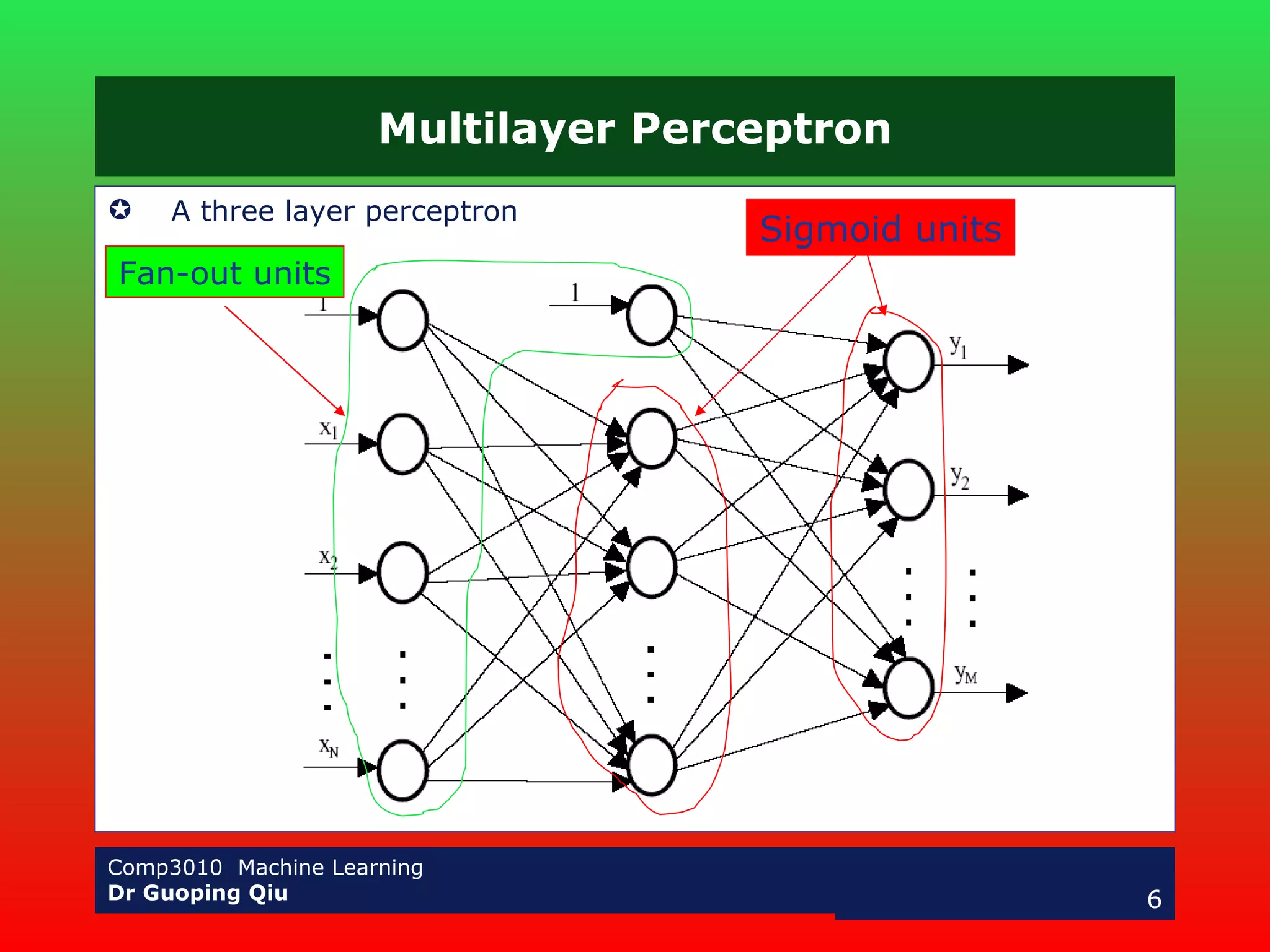
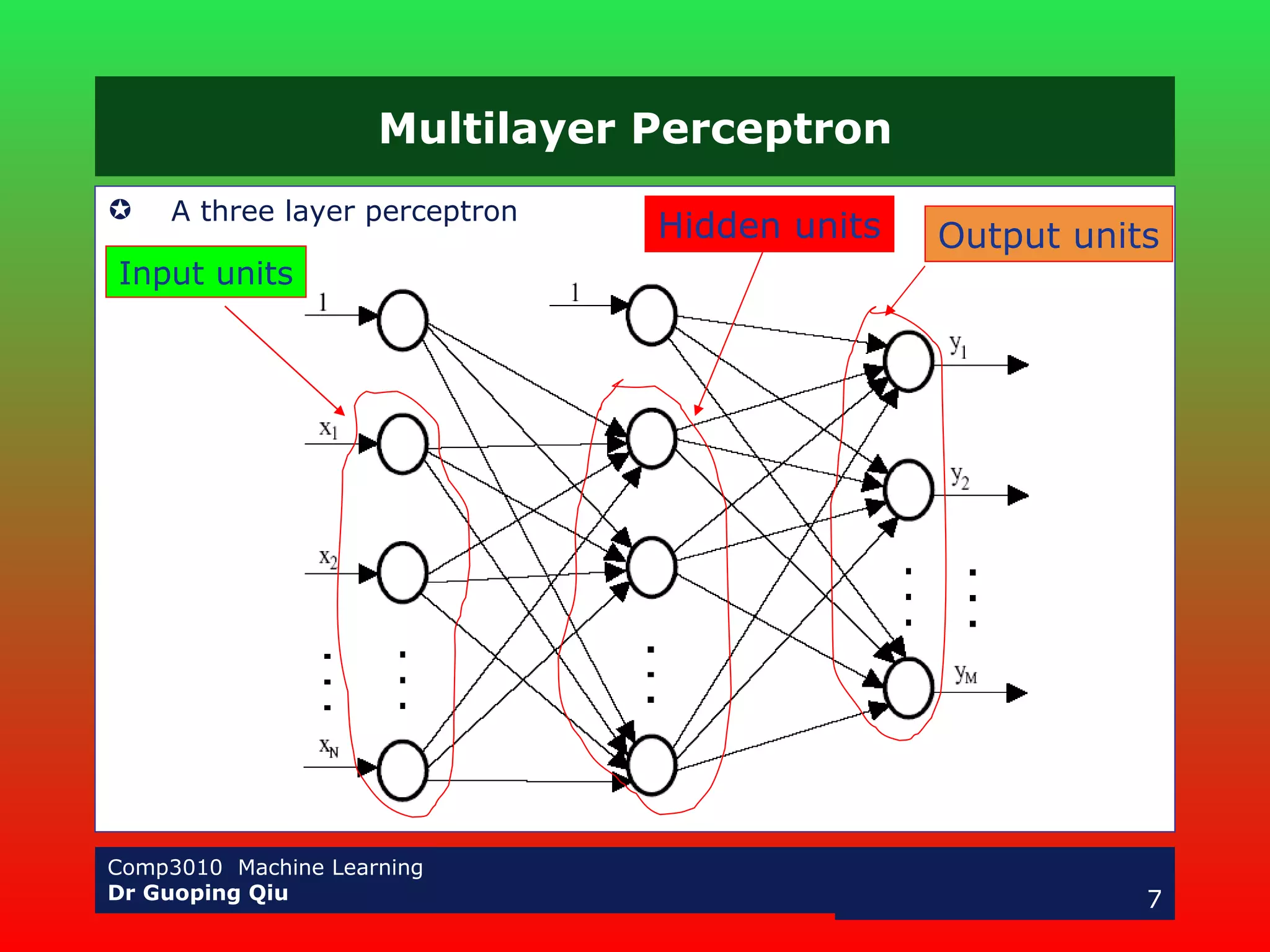
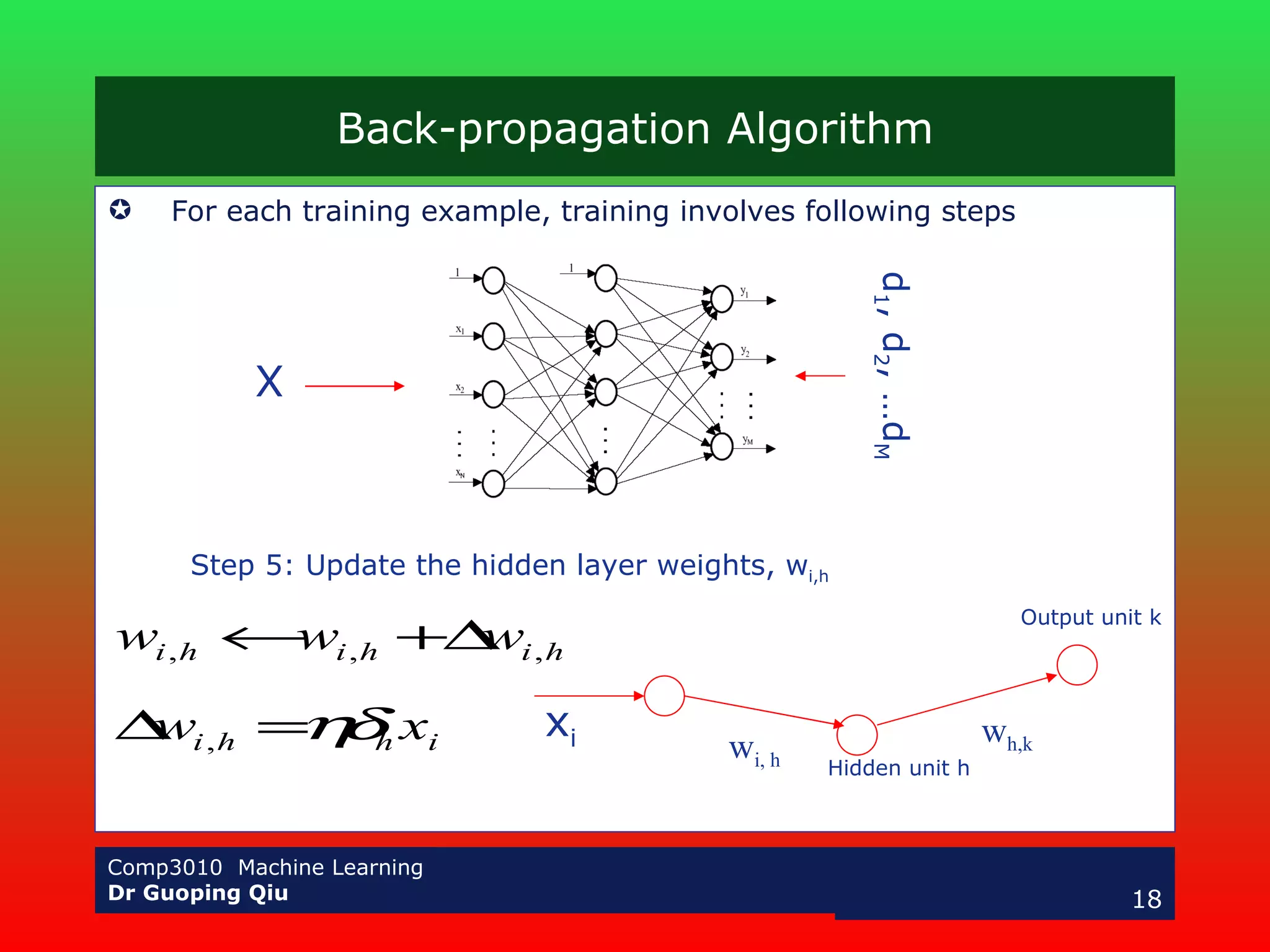
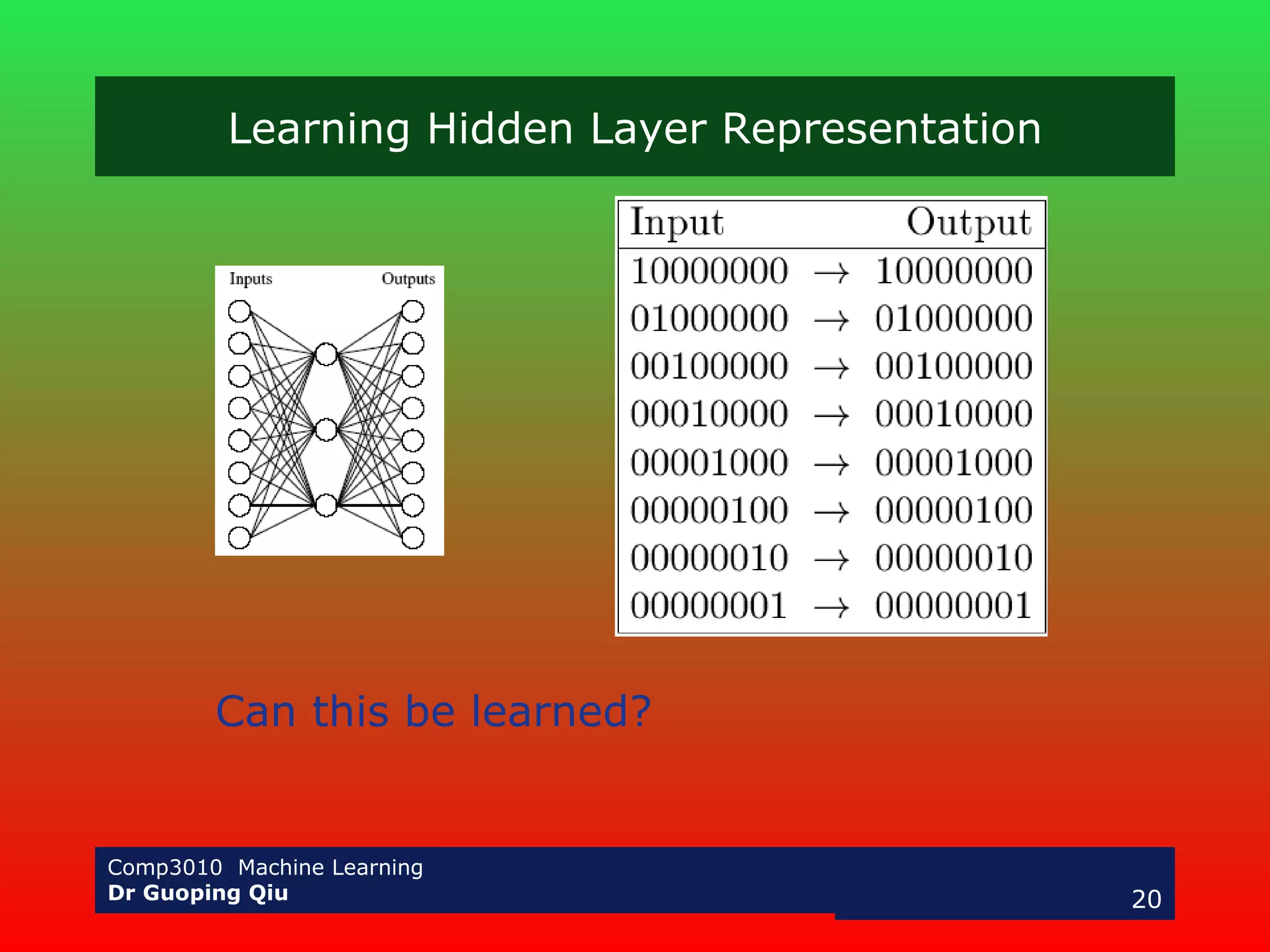
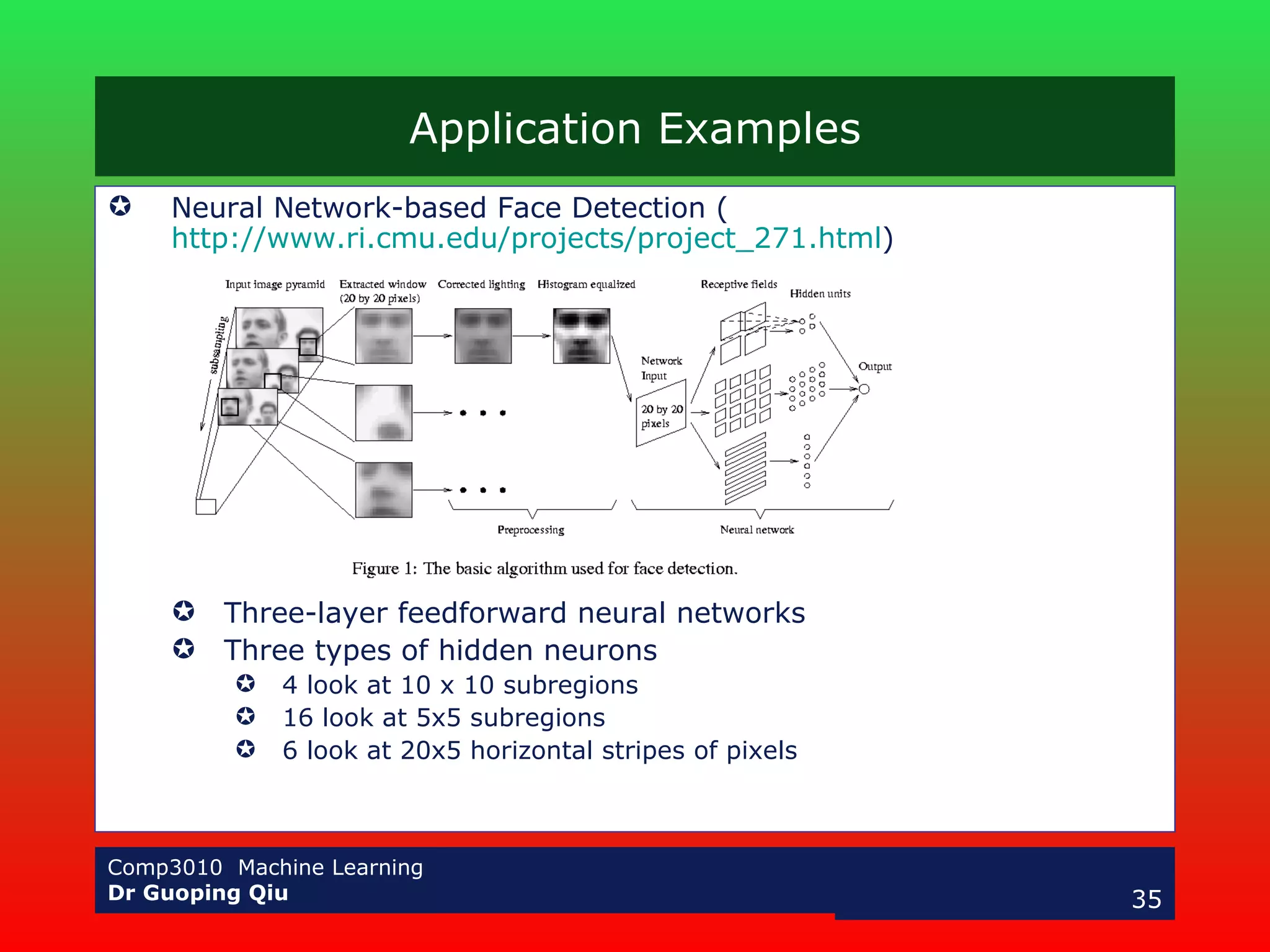
The document discusses multilayer perceptrons and the backpropagation algorithm. It describes how a multilayer network can represent nonlinear decision surfaces using hidden sigmoid units. It then explains the backpropagation algorithm, which involves calculating error gradients for each unit and using them to update weights in the forward and backward passes. Examples of applying neural networks to speech recognition and face detection are also provided.