


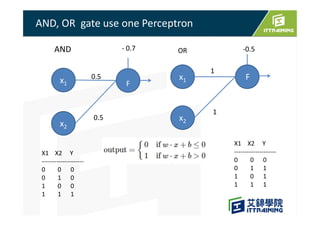
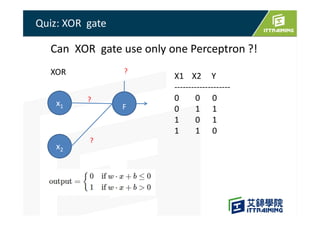

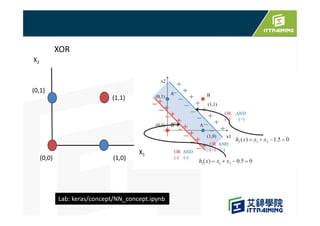



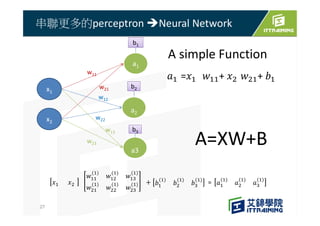







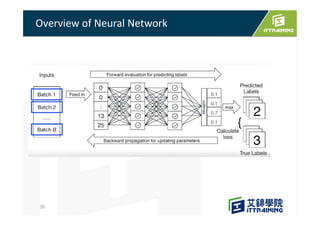


This document discusses the basics of artificial neural networks including multi-layer perceptrons (MLPs). It explains that MLPs use multiple hidden layers between the input and output layers to extract meaningful features from the data. The document also covers topics like training neural networks using backpropagation and stochastic gradient descent, the use of mini-batches to speed up training, and common activation and loss functions.
![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[系列活動] 手把手的深度學實務](https://cdn.slidesharecdn.com/ss_thumbnails/slidedlfinal1216-171213041058-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 手把手的深度學習實務](https://cdn.slidesharecdn.com/ss_thumbnails/slidesharestepbystepdl-161213072731-thumbnail.jpg?width=640&height=640&fit=bounds)




![[系列活動] 一日搞懂生成式對抗網路](https://cdn.slidesharecdn.com/ss_thumbnails/gan-170813004356-thumbnail.jpg?width=640&height=640&fit=bounds)



















































