Downloaded 78 times







![IMPORTING DATASET
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:,2:4]
y= dataset.iloc[:,-1]](https://image.slidesharecdn.com/14-svmclassification-171230051757/85/svm-classification-27-320.jpg)









![READ DATASET
library(readr)
dataset <- read_csv("D:/machine learning AZ/Machine Learning A-Z
Template Folder/Part 3 - Classification/Section 14 - Logistic
Regression/Logistic_Regression/Social_Network_Ads.csv")
dataset = dataset[3:5]](https://image.slidesharecdn.com/14-svmclassification-171230051757/85/svm-classification-37-320.jpg)


![FEATURE SCALING
training_set[-3] = scale(training_set[-3])
test_set[-3] = scale(test_set[-3])](https://image.slidesharecdn.com/14-svmclassification-171230051757/85/svm-classification-40-320.jpg)

![PREDICTION
y_pred = predict(classifier , newdata = test_set[-3])](https://image.slidesharecdn.com/14-svmclassification-171230051757/85/svm-classification-42-320.jpg)
![CONFUSION MATRIX
cm = table(test_set[, 3], y_pred)](https://image.slidesharecdn.com/14-svmclassification-171230051757/85/svm-classification-43-320.jpg)

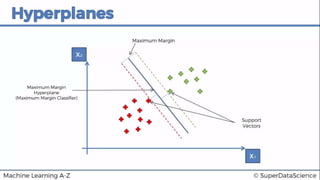
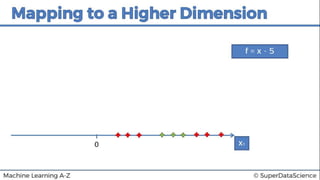
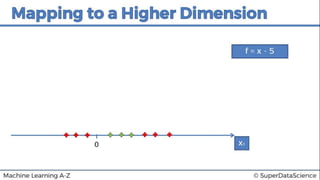
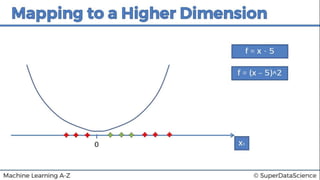
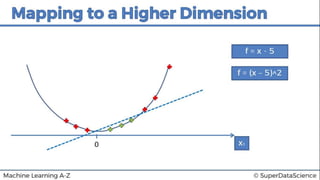
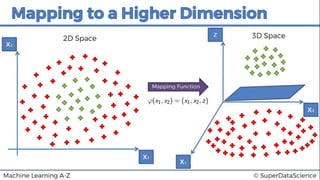
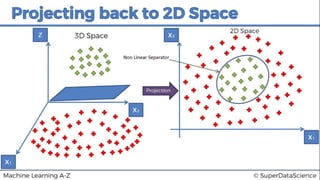
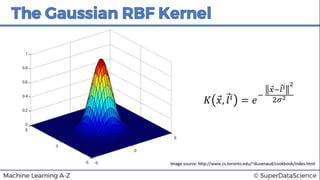
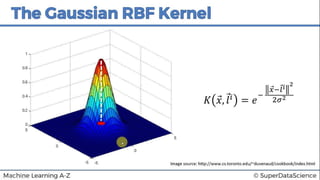
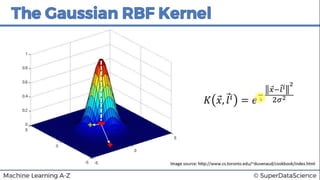
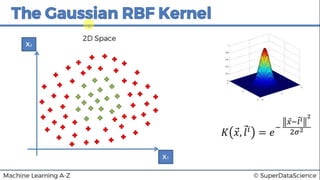
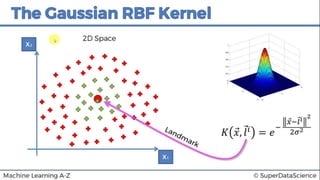
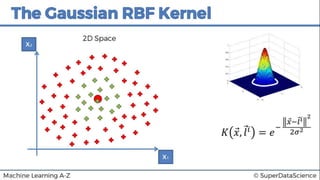
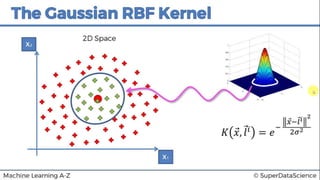
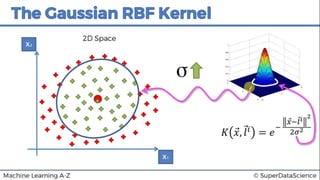
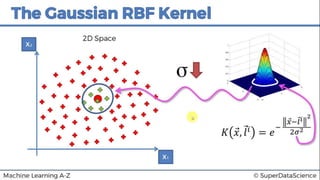
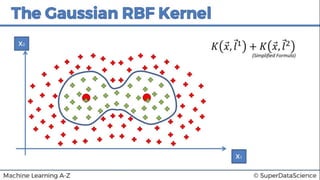
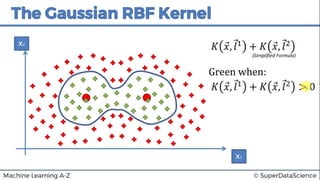
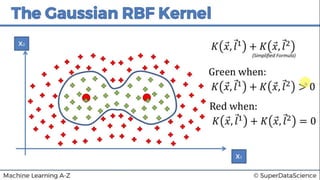
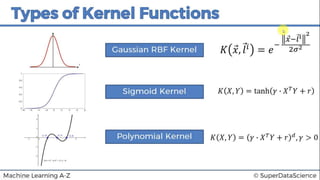
This document discusses support vector machine (SVM) classification using Python and R. It covers importing and splitting a dataset, feature scaling, fitting SVM classifiers to the training set with different kernels, evaluating performance using metrics like confusion matrix, and making predictions on test data. Key steps include feature scaling, fitting linear and radial basis function SVM classifiers, evaluating using k-fold cross validation and classification report.













































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)
![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






