Downloaded 118 times





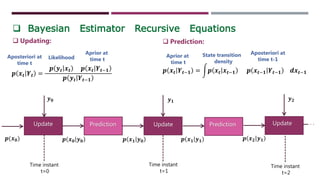














This document provides an overview of particle filtering and sampling algorithms. It discusses key concepts like Bayesian estimation, Monte Carlo integration methods, the particle filter, and sampling algorithms. The particle filter approximates probabilities with weighted samples to estimate states in nonlinear, non-Gaussian systems. It performs recursive Bayesian filtering by predicting particle states and updating their weights based on new observations. While powerful, particle filters have high computational complexity and it can be difficult to determine the optimal number of particles.













































![Sensor Fusion Study - Ch15. The Particle Filter [Seoyeon Stella Yang]](https://cdn.slidesharecdn.com/ss_thumbnails/particlefilter-200815094542-thumbnail.jpg?width=640&height=640&fit=bounds)





































