







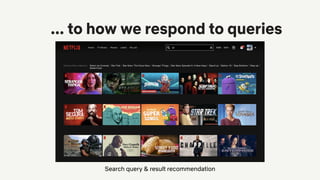








![From Correlation to Causation
● Most recommendation algorithms
are correlational
○ Some early recommendation
algorithms literally computed
correlations between users and items
● Did you watch a movie because
we recommended it to you? Or
because you liked it? Or both?
● If you had to watch a movie, would
you like it? [Wang et al., 2020] p(Y|X) → p(Y|X, do(R))
(from http://www.tylervigen.com/spurious-correlations)](https://image.slidesharecdn.com/2020-09-netflixrecsysexpopublic-200925171822/85/Recent-Trends-in-Personalization-at-Netflix-18-320.jpg)
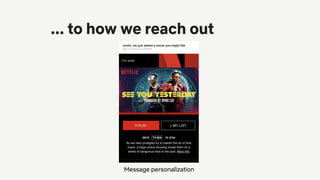
![Feedback loops
Impression bias
inflates plays
Leads to inflated
item popularity
More plays
More
impressions
Oscillations in
distribution of genre
recommendations
Feedback loops can cause biases to be
reinforced by the recommendation system!
[Chaney et al., 2018]: simulations showing that this can reduce the
usefulness of the system](https://image.slidesharecdn.com/2020-09-netflixrecsysexpopublic-200925171822/85/Recent-Trends-in-Personalization-at-Netflix-19-320.jpg)
![Challenges in Causal Recommendations
● Handling unobserved confounders
● Coming up with the right causal graph for the model
● High variance in many causal models
● Computational challenges (e.g. [Wong, 2020])
● Connecting causal recommendations with other aspects like
off-policy reinforcement learning
● When and how to introduce randomization](https://image.slidesharecdn.com/2020-09-netflixrecsysexpopublic-200925171822/85/Recent-Trends-in-Personalization-at-Netflix-23-320.jpg)

![Why contextual bandits for recommendations?
● Break feedback loops
● Want to explore to learn
● Uncertainty around user interests and new items
● Sparse and indirect feedback
● Changing trends
▶Early news example: [Li et al., 2010]](https://image.slidesharecdn.com/2020-09-netflixrecsysexpopublic-200925171822/85/Recent-Trends-in-Personalization-at-Netflix-25-320.jpg)

![Offline Replay Results
● Bandit finds good images
● Personalization is better
● Artwork variety matters
● Personalization wiggles
around best images
Lift in Replay in the various algorithms as
compared to the Random baseline
[More info in our blog post]](https://image.slidesharecdn.com/2020-09-netflixrecsysexpopublic-200925171822/85/Recent-Trends-in-Personalization-at-Netflix-28-320.jpg)








![Many recommenders to optimize
● Same objective? Different ones?
● Can we train (some of) them
together using multi-task learning?
● Is there a way to know a-priori if
combining tasks will be beneficial
or not?
User
history
Ranking
Page
Rating
Explanation
Search
Image
Context ...
[Some MTL examples: Zhao et al., 2015, Bansal et al., 2016, Lu et al., 2018, ...]](https://image.slidesharecdn.com/2020-09-netflixrecsysexpopublic-200925171822/85/Recent-Trends-in-Personalization-at-Netflix-40-320.jpg)



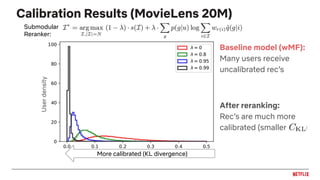
![Calibrated Recommendations [Steck, 2018]
● Fairness as matching distribution of user interests
● Accuracy as an objective can lead to unbalanced predictions
● Simple example:
● Many recommendation algorithms exhibit this behavior of exaggerating the
dominant interests and crowd out less frequent ones
30 action70 romance
30% action70% romance
User:
Expectation:
100% romanceReality: Maximizes accuracy](https://image.slidesharecdn.com/2020-09-netflixrecsysexpopublic-200925171822/85/Recent-Trends-in-Personalization-at-Netflix-44-320.jpg)
![● Which definition of fairness to use in different recommendation
scenarios? [Mehrabi et. al, 2019 catalogues many types]
● Handling fairness without demographic information: both
methods [Beutel et al., 2020] and metrics
● Relationship of fairness with explainability and trust
● Connecting Fairness with all the prior areas
○ Bandits, RL, causality, …
● Beyond fairness of the algorithm: ensuring a positive impact on
society
Challenges in fairness for recommenders](https://image.slidesharecdn.com/2020-09-netflixrecsysexpopublic-200925171822/85/Recent-Trends-in-Personalization-at-Netflix-46-320.jpg)


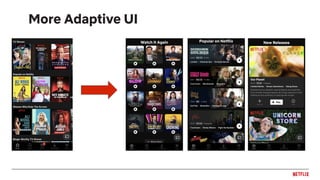
![Experience beyond the app
Recommendations New Arrival New Season AlertComing Soon
[Slides about messaging]](https://image.slidesharecdn.com/2020-09-netflixrecsysexpopublic-200925171822/85/Recent-Trends-in-Personalization-at-Netflix-52-320.jpg)
![● Novelty and learning effects for new experiences
● Cohesion across pages, devices, and time
● Dealing with indirect feedback
● Handling structures of components
○ See [Elahi & Chandrashekar, 2020] poster today
● Coldstarting new experiences
Challenges in Experience Personalization](https://image.slidesharecdn.com/2020-09-netflixrecsysexpopublic-200925171822/85/Recent-Trends-in-Personalization-at-Netflix-53-320.jpg)





The document discusses recent advancements in Netflix's personalization strategies, focusing on various techniques such as causality, bandits, and reinforcement learning to enhance user satisfaction and content discovery. It addresses the challenges of personalization, including handling feedback loops, fairness, and the optimization of long-term user engagement. The presentation also highlights the importance of evolving algorithms and metrics to improve the recommendation experience for diverse user needs.










































































