Download to read offline


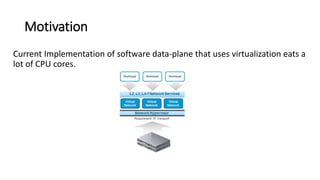


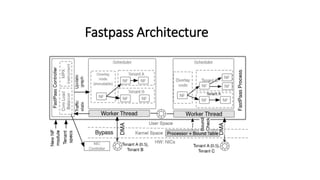


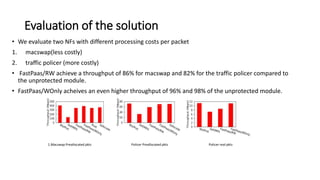



The document discusses challenges in multi-tenancy for function-based data planes, focusing on memory and performance isolation. It presents a solution called FastPass, which utilizes efficient scheduling and memory protection methods to enhance resource management and throughput for different network functions. The evaluation reveals that FastPass achieves significantly higher throughput compared to unprotected modules, with plans for future improvements in scheduling strategies and performance comparison with Rust.















































































