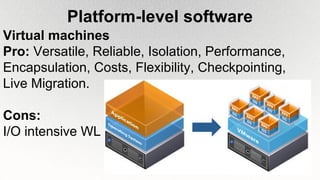
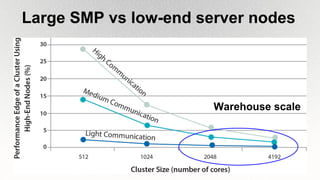
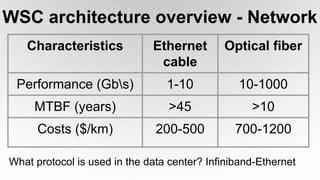
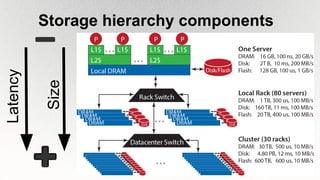
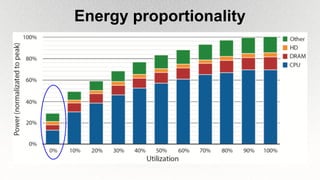
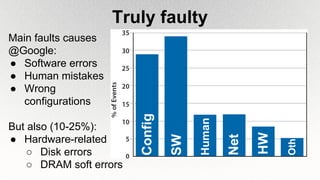
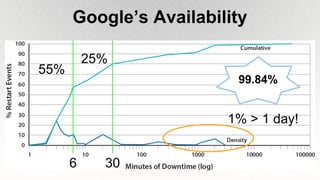
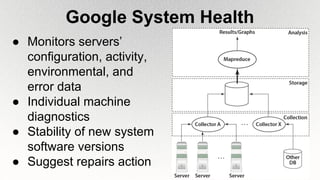
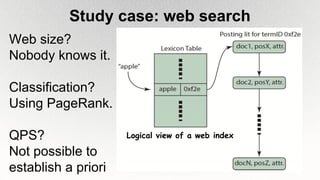
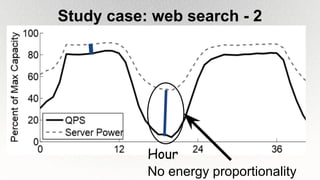
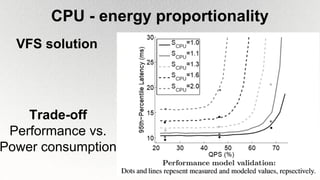
This document outlines the architecture and design principles of Warehouse-Scale Computers (WSCs), emphasizing their scalability, efficiency, and management of hardware and software technologies. It discusses key components like server hardware, networking, and storage, as well as factors such as energy efficiency, fault tolerance, and cost modeling in the context of operating large-scale data centers. The document also highlights the motivations for using WSCs, such as demand for cloud services, and provides insights into handling failures and optimizing performance.














![Capital Cost - example1
1
Ref. [2]
Servers
$2,997,090
Power &
Cooling
$1,296,902
Power
$1,042,440
Other
$284,686](https://image.slidesharecdn.com/c-150604210117-lva1-app6891/85/An-introduction-to-the-Design-of-Warehouse-Scale-Computers-19-320.jpg)










![References
[1] Barroso, Clidaras, Hölzle, The Datacenter as a Computer: An
Introduction to the Design of Warehouse-Scale Machines, Morgan &
Claypool Publishers, 2013
[2]http://perspectives.mvdirona.com/2008/11/cost-of-power-in-large-
scale-data-centers/, James Hamilton, AWS Team
Thank you for
listening !](https://image.slidesharecdn.com/c-150604210117-lva1-app6891/85/An-introduction-to-the-Design-of-Warehouse-Scale-Computers-44-320.jpg)



































































