Download to read offline








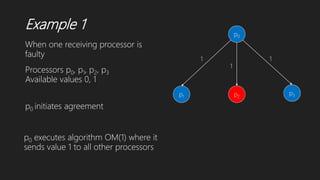
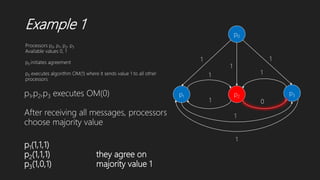




![Dolev et al.’s Algorithm
k
j
* k
k
k
i
Wi
k [ j,…..,]
Witness for k message is j
Processor j is direct supporter of k if j directly receives “*” from k.
When a nonfaulty processor j directly receives “*” from
processor k, it sends message “k” to all other processors
When processor i receives message “k” from processor j, it adds
j into Wi
k because j is a witness to message “k”
Wi
k is set of processors (witness) that have sent message k to
processor i.
Processor i is indirect supporter of processor j
if |Wi
k|>= LOW
Processor i confirms processor j
if |Wi
k|>= HIGH](https://image.slidesharecdn.com/solutionstobyzantineagreementproblem1-191208182430/85/Solutions-to-byzantine-agreement-problem-19-320.jpg)

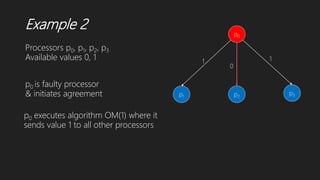
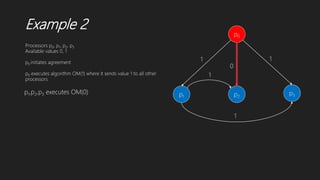
![Dolev et al.’s Algorithm
p1 p2
p3 p4
W* [1]
W1 []
W2 []
W3 []
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
*
* *
Round 1
P1 initiates and sends *](https://image.slidesharecdn.com/solutionstobyzantineagreementproblem1-191208182430/85/Solutions-to-byzantine-agreement-problem-21-320.jpg)
![Dolev et al.’s Algorithm
p1 p2
p3 p4
W* [1,3]
W1 []
W2 []
W3 []
W4 []
W* [1,3]
W1 [3]
W2 []
W3 []
W4 []
W* [1,3]
W1 []
W2 []
W3 []
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
*
* **,1
*
Round 1 Status
Round 2](https://image.slidesharecdn.com/solutionstobyzantineagreementproblem1-191208182430/85/Solutions-to-byzantine-agreement-problem-22-320.jpg)
![Dolev et al.’s Algorithm
p1 p2
p3 p4
W* [1,2,3]
W1 []
W2 []
W3 []
W4 []
W* [1,2,3]
W1 [3]
W2 []
W3 []
W4 []
W* [1,2,3]
W1 [2]
W2 []
W3 []
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
*
* **,1
*
*
*,1
Round 1 Status
Round 2](https://image.slidesharecdn.com/solutionstobyzantineagreementproblem1-191208182430/85/Solutions-to-byzantine-agreement-problem-23-320.jpg)
![Dolev et al.’s Algorithm
p1 p2
p3 p4
W* [1,2,3]
W1 [2]
W2 []
W3 [2]
W4 []
W* [1,2,3]
W1 [2,3]
W2 []
W3 [2]
W4 []
W* [1,2,3]
W1 [2]
W2 []
W3 [2]
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
*
* **,1
*
*
*,1
3,1
3,1
Round 2 Status
Round 3](https://image.slidesharecdn.com/solutionstobyzantineagreementproblem1-191208182430/85/Solutions-to-byzantine-agreement-problem-24-320.jpg)
![Dolev et al.’s Algorithm
p1 p2
p3 p4
W* [1,2,3]
W1 [2,,3]
W2 [3]
W3 [2]
W4 []
W* [1,2,3]
W1 [2,3]
W2 [3]
W3 [2]
W4 []
W* [1,2,3]
W1 [2,3]
W2 []
W3 [2]
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
*
* **,1
*
*
*,1
3,1
3,1
2,1 2,1
Round 2 Status
Round 3](https://image.slidesharecdn.com/solutionstobyzantineagreementproblem1-191208182430/85/Solutions-to-byzantine-agreement-problem-25-320.jpg)
![Dolev et al.’s Algorithm
p1 p2
p3 p4
W* [1,2,3]
W1 [2,,3]
W2 [3]
W3 [2]
W4 []
W* [1,2,3]
W1 [2,3]
W2 [3]
W3 [1,2]
W4 []
W* [1,2,3]
W1 [2,3]
W2 [1]
W3 [2]
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
*
* **,1
*
*
*,1
3,1
3,1
2,1 2,12
3
Round 2 Status
Round 3](https://image.slidesharecdn.com/solutionstobyzantineagreementproblem1-191208182430/85/Solutions-to-byzantine-agreement-problem-26-320.jpg)
![Dolev et al.’s Algorithm
p1 p2
p3 p4
W* [1,2,3]
W1 [1,2,3]
W2 [1,3]
W3 [1,2]
W4 []
W* [1,2,3]
W1 [1,2,3]
W2 [1,3]
W3 [1,2]
W4 []
W* [1,2,3]
W1 [1,2,3]
W2 [1]
W3 [1,2]
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
*
* **,1
*
*
*,1
3,1
3,1
2,1 2,12
31,2,3
1,2,3
Round 3 Status
Round 4](https://image.slidesharecdn.com/solutionstobyzantineagreementproblem1-191208182430/85/Solutions-to-byzantine-agreement-problem-27-320.jpg)
![Dolev et al.’s Algorithm
p1 p2
p3 p4
W* [1,2,3]
W1 [1,2,3]
W2 [1,2,3]
W3 [1,2]
W4 []
W* [1,2,3]
W1 [1,2,3]
W2 [1,2,3]
W3 [1,2]
W4 []
W* [1,2,3]
W1 [1,2,3]
W2 [1,2]
W3 [1,2]
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
*
* **,1
*
*
*,1
3,1
3,1
2,1 2,12
31,2,3
1,2,3 1,2,3
1,2,3
Round 3 Status
Round 4](https://image.slidesharecdn.com/solutionstobyzantineagreementproblem1-191208182430/85/Solutions-to-byzantine-agreement-problem-28-320.jpg)
![Dolev et al.’s Algorithm
p1 p2
p3 p4
W* [1,2,3]
W1 [1,2,3]
W2 [1,2,3]
W3 [1,2,3]
W4 []
W* [1,2,3]
W1 [1,2,3]
W2 [1,2,3]
W3 [1,2,3]
W4 []
W* [1,2,3]
W1 [1,2,3]
W2 [1,2,3]
W3 [1,2,3]
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
*
* **,1
*
*
*,1
3,1
3,1
2,1 2,12
31,2,3
1,2,3 1,2,3
1,2,3
1,2,3
1,2,3
Round 3 Status
Round 4](https://image.slidesharecdn.com/solutionstobyzantineagreementproblem1-191208182430/85/Solutions-to-byzantine-agreement-problem-29-320.jpg)
![Dolev et al.’s Algorithm
p1 p2
p3 p4
W* [1,2,3]
W1 [1,2,3]
W2 [1,2,3]
W3 [1,2,3]
W4 []
W* [1,2,3]
W1 [1,2,3]
W2 [1,2,3]
W3 [1,2,3]
W4 []
W* [1,2,3]
W1 [1,2,3]
W2 [1,2,3]
W3 [1,2,3]
W4 []
W* [1]
W1 []
W2 []
W3 []
W4 []
*
* **,1
*
*
*,1
3,1
3,1
2,1 2,12
31,2,3
1,2,3 1,2,3
1,2,3
1,2,3
1,2,3
An Agreement is reached in 4 rounds](https://image.slidesharecdn.com/solutionstobyzantineagreementproblem1-191208182430/85/Solutions-to-byzantine-agreement-problem-30-320.jpg)


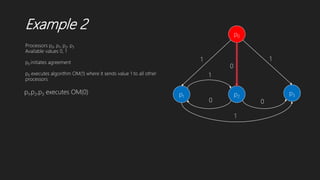
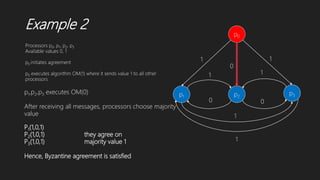
The document summarizes two algorithms for solving the Byzantine agreement problem: 1) Lamport-Shostak-Pease algorithm uses oral messaging to recursively achieve agreement among processors in the presence of faulty processors, as long as the number of faulty processors does not exceed one-third of the total. 2) Dolev et al.'s algorithm does not depend on behavior of faulty processors, requires 2m+3 rounds, and achieves agreement through processors broadcasting messages to confirm values until agreement is reached.













































































