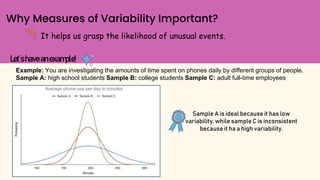
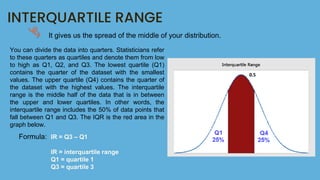
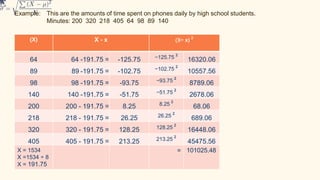
This document discusses different measures of variability used to describe the dispersion of data, including range, interquartile range, standard deviation, and variance. It provides formulas and examples to calculate each measure using a sample data set of time spent on phones daily by high school students. The range tells the difference between highest and lowest values, while the interquartile range describes the middle half of data. Standard deviation and variance measure how far data points are from the mean, with variance being the average of squared deviations and standard deviation being the square root of variance.