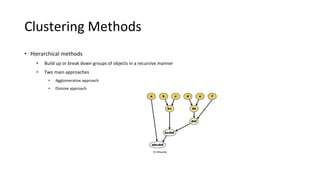
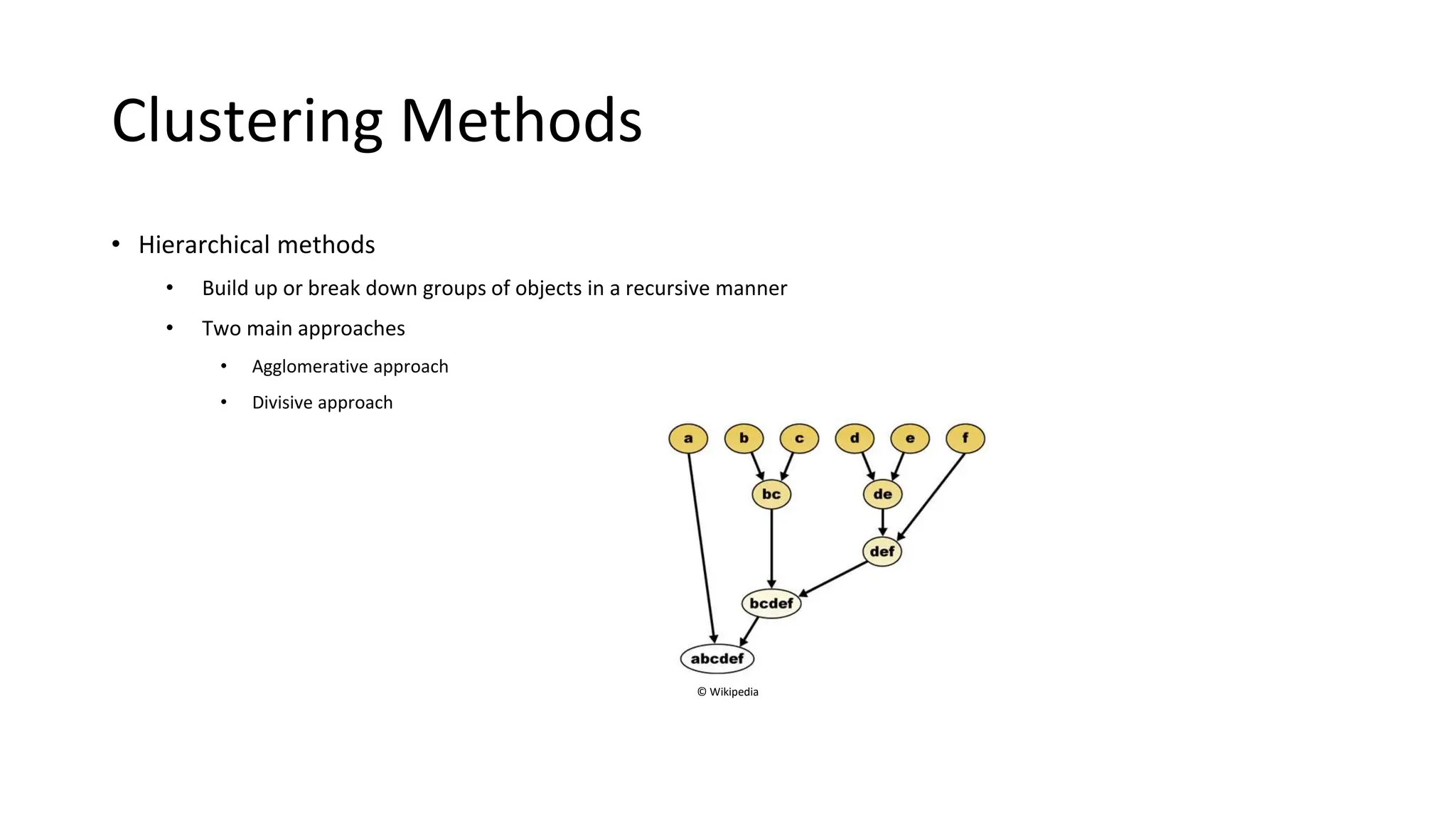
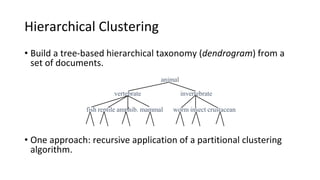
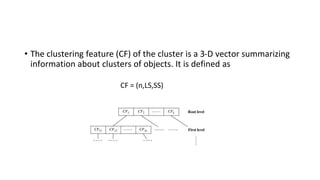
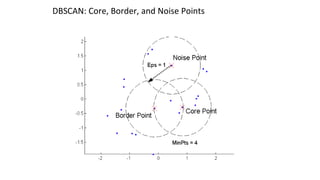
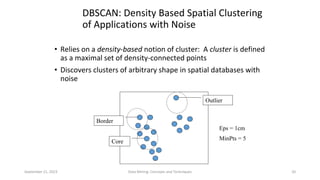
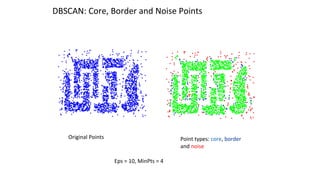
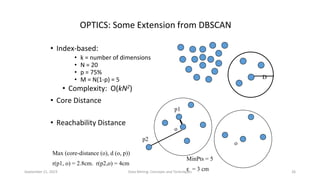
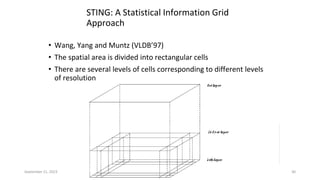
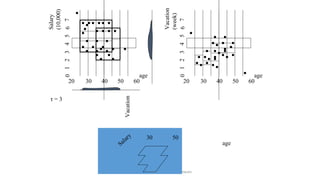
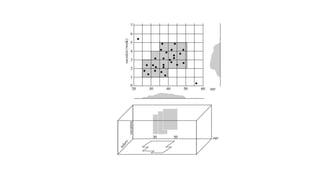
Hierarchical clustering methods build groups of objects in a recursive manner through either an agglomerative or divisive approach. Agglomerative clustering starts with each object in its own cluster and merges the closest pairs of clusters until only one cluster remains. Divisive clustering starts with all objects in one cluster and splits clusters until each object is in its own cluster. DBSCAN is a density-based clustering method that identifies core, border, and noise points based on a density threshold. OPTICS improves upon DBSCAN by producing a cluster ordering that contains information about intrinsic clustering structures across different parameter settings.